A Zen architektúra - avagy az AMD második esélye
Az új mikroarchitektúrának hála 10 év után újraindulhat az x86-os processzorok versenye. Minden a Zen mélylélektanáról. Vigyázat, hosszú lett!
Az elmúlt nagyjából tíz év eseményeinek ismeretében nem túlzás kijelenteni, hogy 2006 július 27-én kis híján végzetes csapást mért az addigra egyetlen talpon maradt komoly konkurensére az Intel. A Core 2 Duo processzorok piaci rajtjával egy pillanat alatt megtört az AMD ezredforduló óta tartó lendületes menetelése, és az addig rendkívül versenyképes és népszerű, K8 mikroarchitektúrára épülő Athlon 64 (X2) processzorok tetemes hátrányba kerültek, a cég piaci értéke pedig meredek zuhanásba kezdett.
Évtizedes vesszőfutás
Az AMD ekkor még (látszólag) nem esett pánikba, az új dimenziót jelentő Core 2 termékekre jobb híján árcsökkentésekkel reagált, a piacot és a befektetőket pedig a már csőben lévő K10-es fejlesztéssel csitította. A piac első natív, azaz egyetlen monolitikus szilíciumlapkán négy processzormagot felvonultató fejlesztésének megjelenését azonban később komoly problémák hátráltatták: "[A Barcelona] szörnyen komplikált. Olyasmit csinálunk, amit még soha senki. Még egy olyan erős cég, mint a versenytársunk, sem készített négymagos chipet. Minden egyes alkalommal, mikor egy csapdába futottunk, egy nagyjából hathetes rés keletkezett az ütemtervben miután visszatértünk rá, és kijavítottuk. Reméltük nem lesz ilyenből túl sok, de a Barcelona esetében többet botlottunk, mint gondoltuk." - nyilatkozta 2007 augusztusában az akkori vezér, Hector Ruiz. (Akinek másfél évvel később az AMD igazgatótanácsa útilaput kötött a talpára.)

Ruizt a legrosszabbul teljesítő elnök-vezérigazgatónak választotta a 24/7 Wall Street magazin
A K10-es mikroarchitektúrára épülő processzorok végül csak nagyjából fél év késéssel, 2007 őszén jelentek meg. A csúszásnál azonban sokkal nagyobb probléma volt, hogy a CPU-k gyártási nehézségek miatt alacsony órajellel érkeztek, így sem a szerveres Opteronok, sem pedig az asztali Phenomok nem tudták felvenni a versenyt a konkurens Intel termékeivel. Ha ez még önmagában nem lett volna elég nagy csapás, alig néhány héttel a rajt után az AMD kénytelen volt leállítani a már amúgy is több sebből vérző processzorok szállítását. A problémát egy későn észrevett hiba (erratum) okozta, a memóriacím fordítási tár- (TLB) és cache-műveletek bizonyos esetekben olyan erőforráskonfliktushoz vezethettek, amelyek a rendszer fagyását eredményezhették, a javított stepping kiadása pedig újabb súlyos hónapokba került. Mindeközben a hibát hibára halmozó vállalat tőzsdei értéke nagyjából a történelmi rekord ötödére zuhant.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Az esetlen bukdácsolásból igazi felüdülést jelentett a K10 második iterációja. A K10.5 kisebb mikroarchitektúrális optimalizálások mellett új, 45 nanométeres gyártástechnológiát mutatott be, amivel az AMD nagyjából eljutott oda, ahová az első szériával szeretett volna, magasabb órajelek, alacsonyabb fogyasztás, kellemetlen hibától mentes processzormag. Az egyetlen problémát az ősi rivális időközben mutatott töretlen menetelés jelentette, amely ekkor már árkon-bokron túl járt, az Intel ugyanis a Shanghai kódnevű Opteronokkal és a Phenom II-vel szinte párhuzamosan mutatta be mai processzorainak közvetlen felmenőjét, a Nehalemet.
Ezzel már a szerverpiacon is abszolút technikai fölénybe került az Intel, ugyanis a Nehalem a vállalat kínálatában elsőként hozta el az integrált memóriavezérlőt és a pont-pont összeköttetéssel magas sávszélességet biztosító Quick Path Interconnectet. Az ehhez párosított erős processzormagokkal karöltve az Intel gyorsan domináns szereplővé tudott válni. Ebben pedig fontos szerepet játszott a fejlesztési tervek óramű pontosságú (tikk-takk) végrehajtása is, így az AMD felzárkózni sem tudott, emiatt pedig az Intel mára kvázi egyeduralkodóvá vált az igen vastag haszonnal kecsegtető szerverpiacon, miközben az AMD részesedése alig mérhető szintre zuhant.
Az önpusztító Bulldozer
Utóbbihoz a Bulldozer kódnéven futó, megváltóként várt fejlesztés sikertelensége is nagyban hozzájárult, amivel az AMD végül szinte pontosan lemásolta K10 vesszőfutását. A fejlesztés több hónapot csúszott, a gyártáshoz szükséges 32 nanométeres technológiával pedig csak nagyon nehezen boldogult az időközben leválasztott félvezetőgyártási tevékenységből létrejött bérgyártó cég, a GlobalFoundries. Ezt tetézte az x86-os mikroarchitektúrák között addig egyedinek számító modulos kialakítás, illetve az arra ültetett Cluster-based multi-threading (klaszter-alapú többszálúsítás), amire a piacon lévő alkalmazások rapszodikusan reagáltak, a szoftverek egy része lassabban futott le a vadiúj mikroarchitektúrán, mint a közvetlen elődökön.

Az Intel helyett kis híján gazdáját dózerolta le a munkagép
A gyártástechnológia problémái miatt az AMD képtelen volt elérni a tervezésnél megcélzott magas órajeleket, miközben az alacsonyabb frekvenciák mellé magas fogyasztás társult. Ahogy a Phenomok esetében, úgy az AMD FX asztali processzorok és a hasonló lapkára épülő Opteronoknál is sokat javított a helyzeten a második, Piledriver kódnevű iteráció, de ahogy korábban, úgy most is legalább egy lépéssel előrébb járt az Intel, aki időközben a 22 nanométeres FinFET gyártástechnológiájával, illetve az arra épülő Ivy Bridge processzorokkal még nagyobbra növelte előnyét.
A vállalat helyzetén az időközben bemutatott fúziós processzorok, a CPU és GPU magokat egyesítő, heterogén végrehajtásra kihegyezett APU-k sem segítettek. Bár a Brazos platform alapját jelentő legelső generációból az AMD sokat értékesített, a későbbi áttörés elmaradt, a szoftverfejlesztők nem haraptak rá a csaliként lógatott OpenCL API-ra és a HSA-ra. Eközben a tervezőcég helyzetét tovább hátráltatta a GlobalFoundries, a bérgyártó csak jelentős csúszással tudott amúgy versenyképtelen gyártástechnológiát biztosítani partnerének, ami alaposan rányomta bélyegét az AMD termékeire.
Az időközben a vállalaton belül uralkodó problémákról sokat elmond, hogy a korábban Hector Ruiz helyére érkezett Dirk Meyertől bő két év után megvált az igazgatótanács, ugyanis az AMD mellett szinte teljesen észrevétlenül száguldott el az okostelefonos és tabletes piac, bár ebbe később a két nagy rivális, az Intel és Nvidia bicskája is látványosan beletört. Meyer helyére végül csak hosszú hónapok fejvadászatával, 2011 augusztusában sikerült egy vállalkozó kedvű szakembert találni Rory Read személyében. (A jelöltek listája nem volt rövid, azon állítólag még Tim Cook neve is szerepelt.)

Lisa Su és Rory Read
Read, a Lenovo Csoport egykori elnöke azonban elődjénél végül csak alig töltött több időt az AMD vezetői pozíciójában, három évvel kinevezése után lemondott, helyére pedig egy előkészített utódlási terv keretében az általa korábban leszerződtetett Lisa Su került. Ezzel a cég hat éven belül háromszor váltott vezérigazgatót, miközben igazán versenyképes terméket továbbra sem tudott felmutatni, ami folyamatos, masszív veszteségekben ütött vissza. A negyedéves pénzügyi jelentésekből kiderült, hogy az utóbbi nagyjából három évben a konzolos processzorok (Xbox One, PS4) tartották víz felett a céget, az ezekből befolyt bevétel nélkül már valószínűleg régen csődöt jelentett volna az AMD.
A pénzügyi szakadék szélén
Bár Rory Read irányítása alatt csak alig néhány sikeres termék (pl. első GCN-es VGA-k) látott napvilágot, a szakember teljesen átszervezte az AMD-t, ennek keretein belül számos olyan lépést eszközölve, amelynek hatásai csak mostanra értek be. Kinevezése utáni egyik első mozzanatként az iparági legendának tartott Mark Papermastert szerződtette le Read, akit nem sokkal később korábbi IBM-es kolléganője, az AMD jelenlegi regnáló vezérigazgatója, a már említett Lisa Su követte.
The Exact Moment AMD Beat Intel
Még több videóEzután Papermaster egykori Apple-ös kollégája, a félvezetőipar egyik legnagyobb élő kiválóságának tartott Jim Keller csábult vissza az AMD-hez a mikroarchitekúra fejlesztéséért felelős alelnöki pozícióba. Keller anno az Intel-verő K7 és K8 mikroarchitektúrák, illetve a HyperTransport busz tervezésében is részt vett, távozása után pedig az Apple A4 és A5 processzorok megépítésében is oroszlánrészt vállalt. (Az ezekkel kitaposott ösvényen azóta is töretlenül menetelnek tovább a mai iPhone-ok és iPadek központi egységei, CPU teljesítményben utcahosszal a konkurensek előtt.)
Az időközben Teslához igazolt szakember vezénylete alatt indult meg a Zen kódnevű x86-os mikroarchitektúra fejlesztése lassan öt évvel ezelőtt, 2012 végén. Jól szemlélteti, mennyire lassú és bonyolult folyamat egy új processzordizájn felépítése, hogy az első prototípusok csak tavaly nyáron születtek meg, a végleges, piacképes termékek megjelenéséhez pedig nagyjából négy és fél év kellett.

A tervezőcsapat immár Keller nélkül: elől Mike Clark vezető tervező és Suzanne Plummer tervezési igazgató
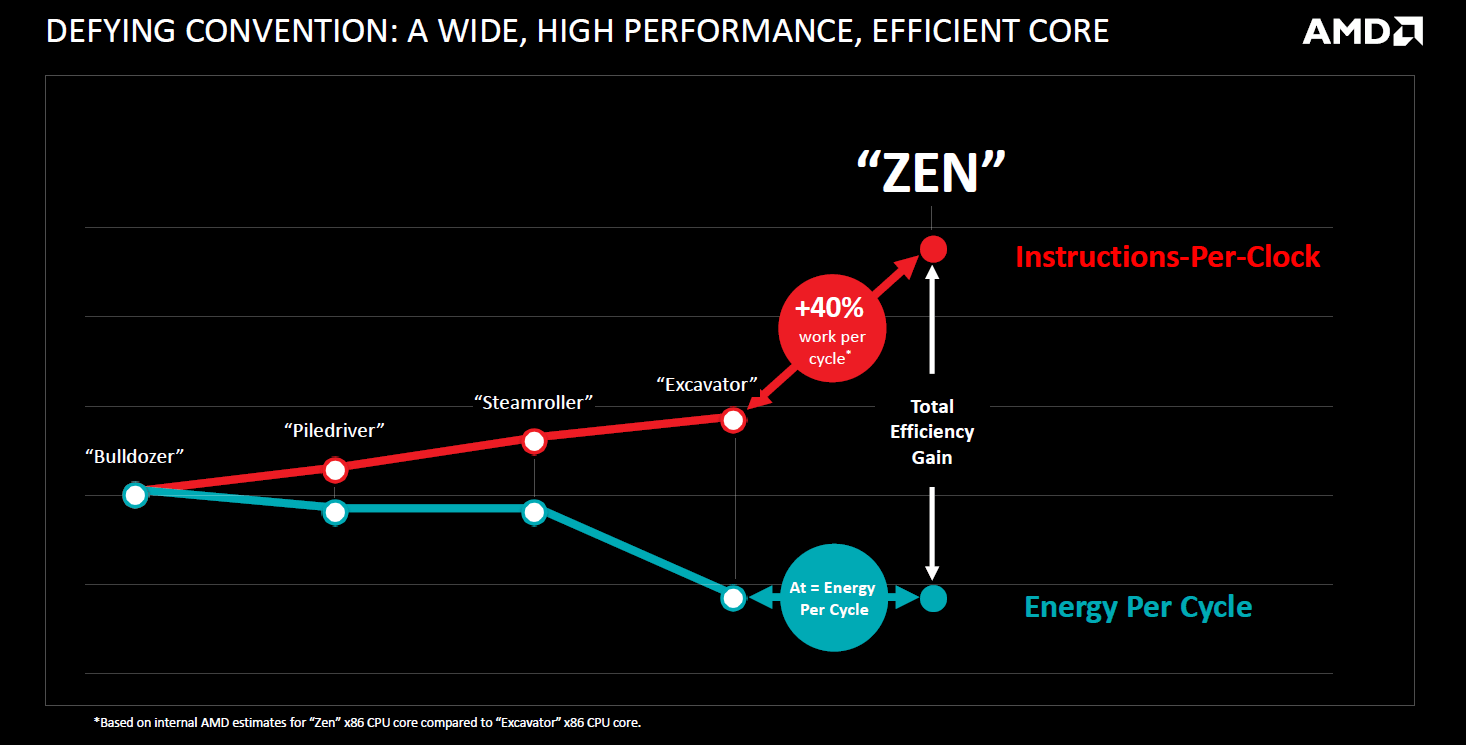
A tervezőgárdának közben mindent vagy semmit alapon kellett dolgoznia, miközben a munkaadó szinte folyamatosan a csőd szélén egyensúlyozott. Mike Clark vezető tervező szerint csapata mégsem ezért keresztelte Zenre a projektet, a szakember szerint a számítási teljesítmény, a fogyasztás, és az ehhez szükséges tranzisztormennyiség megfelelő egyensúlyának megtartása adta az ihletet, ami mellé egy konkrétabb, az Excavatorhoz viszonyított 40 százalékos IPC (órajelenként elvégzett utasítás) növekedést is kitűzött a csapat.
Az AMD alkalmazottjainak ez időtájt kapóra jöhetett a mikroarchitektúra nevéhez szorosan kapcsolható zazen ülőmeditáció gyakorlása, a vállalat ugyanis többszöri leépítésekkel, valamint ingatlanjainak és megmaradt gyártórészlegének eladásával próbálta átvészelni a kritikus időszakot. A vállalat nem engedhetett meg magának még egy K10-et vagy Bulldozert, a Zennek, illetve az arra épülő processzoroknak egyértelműen versenyképes alternatívaként kellett piacra kerülnie.
A Zen mélylélektana
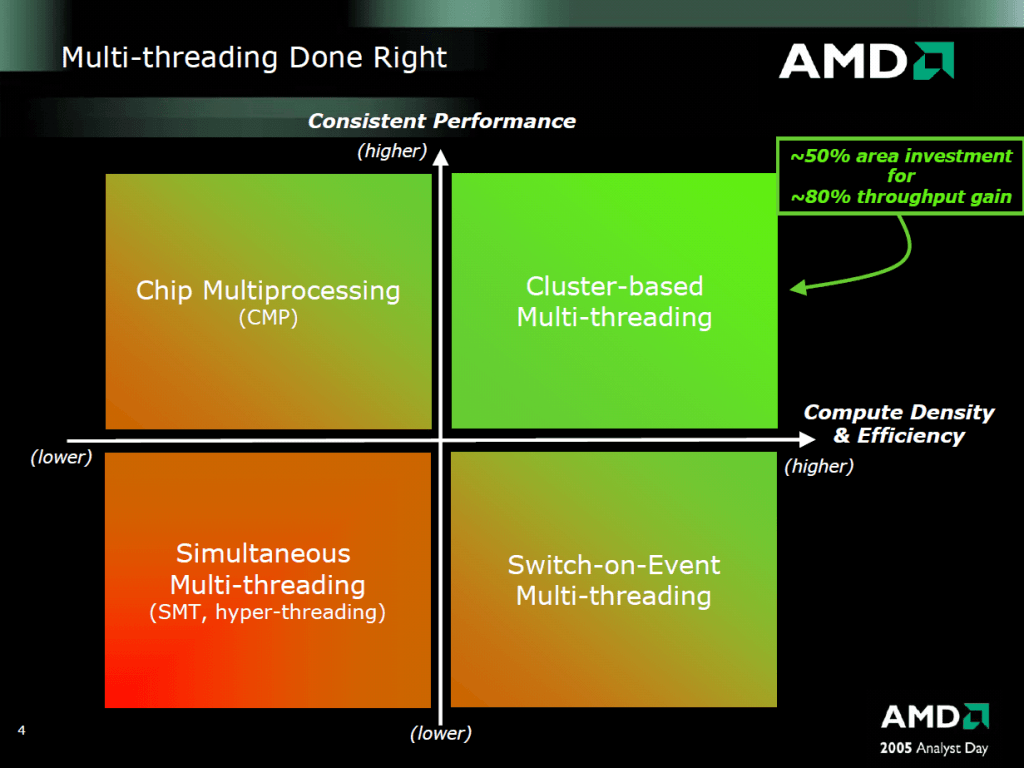
Ennek első lépcsőjeként a tervezőcsapat teljesen szakított a Bulldozer családban alkalmazott modul-alapú felépítéssel, amely bár két programszál futtatására alkalmas, az erőforrásokat nagyrészt statikusan osztja fel a szálak között, ami rontja az egyszálas teljesítményt. A Zen visszalép egyet, és a Bulldozerrel párhuzamosan fejlesztett apró, kis fogyasztású magokra fókuszáló Bobcat/Jaguar vonallal tovább vitt konvencionális alapokkal indít. Ezt kiegészíti az IBM által 1968-ban lefektetett (és a POWER processzorokban még ma is alkalmazott) SMT, amit a konkurens Intel Hyper-Threading fantázianéven kezdett el implementálni még a Northwood kódnevű Pentium 4-gyel, kisebb megszakítással (Core 2) pedig azóta is alkalmaz. Az SMT (simultaneous multi-threading) előnye, hogy szinte teljesen dinamikusan osztja fel a processzormag egységeit a két utasításfolyam (végrehajtószál) között, lehetővé téve, hogy egyetlen programszál futtatása esetén a teljes kapacitás ennek rendelkezésére álljon.
2005-ben még másképp látta az SMT-t az AMD
Ez pálfordulás az AMD tervezési filozófiájában, a cég 2005-ben még kifejezetten az SMT ellen kampányolt, mindezt elsősorban arra alapozva, hogy a megoldás se nem konzisztens, se nem elég hatékony. Általánosságban véve a hatékonyság alkalmazás- és architektúrafüggő, de elmondható, hogy out-of-order felépítésnél optimális esetben körülbelül 20-25% teljesítménynövekedést hozhat az SMT, nagyjából 5 százalékkal több tranzisztorért cserébe, amelyek az egy-egy szál dedikált (statikus) erőforrásaihoz szükségesek. A konzisztencia más kérdés, a technológia sajátosságai miatt olykor valóban előfordulhat, hogy az SMT jelenléte semmilyen, vagy szélsőségesebb esetben negatív hatással lehet a végrehajtási sebességre, ezért néhány esetben javasolt a kikapcsolása.
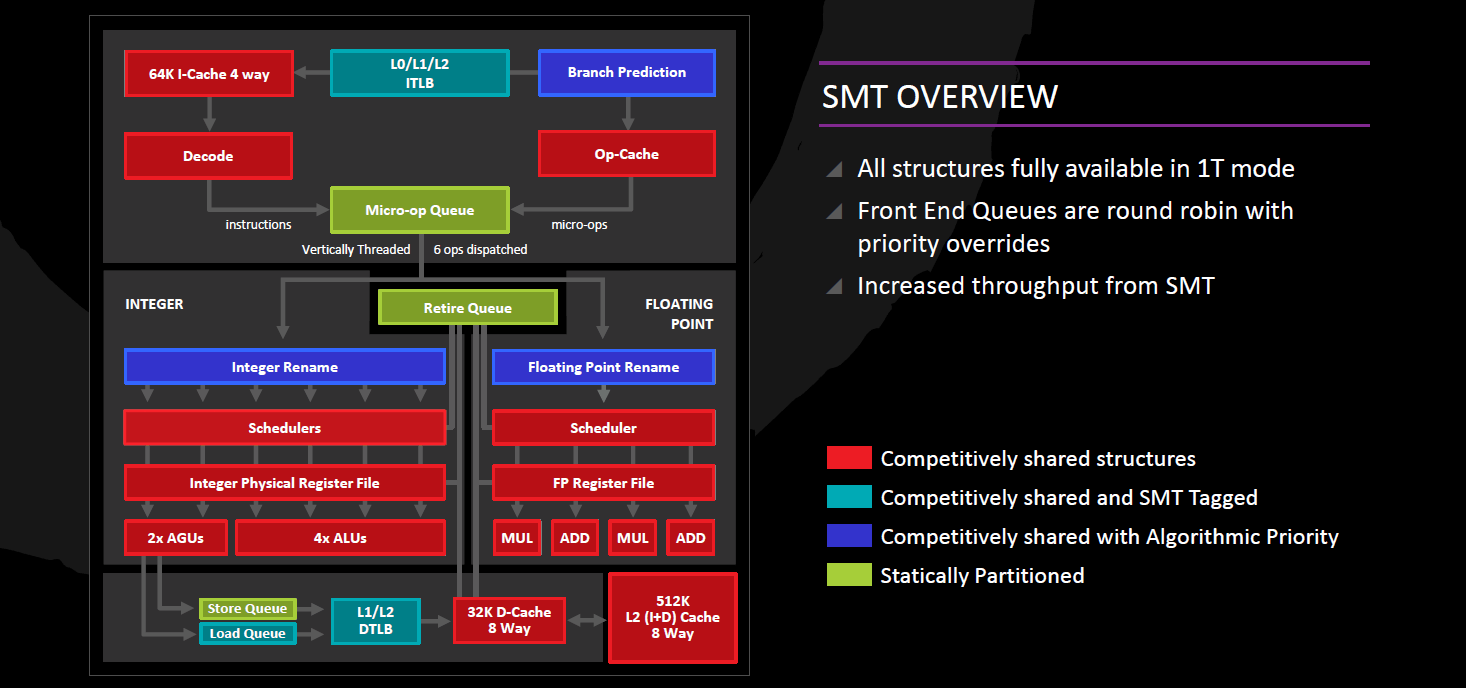
A Zen teljes integer/memória futószalagja 19 fokozat hosszú, amely jelentősen kevesebb, mint a korábbi Bulldozer-család végrehajtásai fokozatainak száma, illetve bizonyos esetekben ennél is kevesebb lépésen haladnak végig az utasítások. Tekintsük át ezeket a lépcsőket!
Elágazásbecslés
Az utasítások végrehajtása a soron következő utasítások címének meghatározásával kezdődik, amely az elágazásbecslő egységek feladata; ez három részből áll, és bár az AMD meglovagolva az aktuális trendeket "Neural Net Prediction" fantázianévvel hivatkozik rá, működési elvét tekintve nagyon hasonló a Bulldozer-alapú CPU-kban alkalmazott megoldással. Ez nem meglepő, hiszen ott a hosszú futószalag miatt kritikus fontosságú volt a minél pontosabb becslés, mivel a tévesztéseknek igen nagy büntetése van; a hosszú pipeline-hoz kidolgozott (ott perceptronként emlegetett) megoldásra viszont rövidebb futószalag etetését is rá lehet bízni, ezért megéri újrafelhasználni. Hasonló megoldást alkalmazott az Intel is korábban, a NetBursthöz kidolgozott elágazásbecslési mechanizmusokat és tapasztalatokat bevetették a Core mikroarchitektúrában is. A perceptronok olyan, neuronokhoz hasonló egységek, melyek az ugrás előző lefutásainak korrelációit veszi figyelembe, így nagyon hosszú ugrás-nem ugrás mintákat képes megtanulni. A bekezdés elején említett három rész a következő:
- a feltételes ugrások viselkedésének előrejelzését perceptron-alapú prediktorok végzik, kétszintes (L1 és L2) Branch Target Buffer-ben tárolva a kiszámolt célcímet (az x86 ill. x64 feltételes ugróutasításokba az aktuális – Instruction Pointer regiszterben tárolt - címtől számított pozitív vagy negatív elmozdulás van bekódolva);
- az indirekt vezérlésátadó utasítások gyors végrehajtásához - ezek alapvetően egy memóriában levő pointerből olvassák ki a célcímet – 512 elemű Indirect Target Array címtömböt alkalmaz;
- az eljáráshívás (CALL) ill. azokból történő visszatérés (RET) párokhoz 32 elemű Return Address Stack áll rendelkezésre. Ez utóbbi statikus megosztást kapott, 1 programszál legfeljebb 16 elemet tölthet ki.
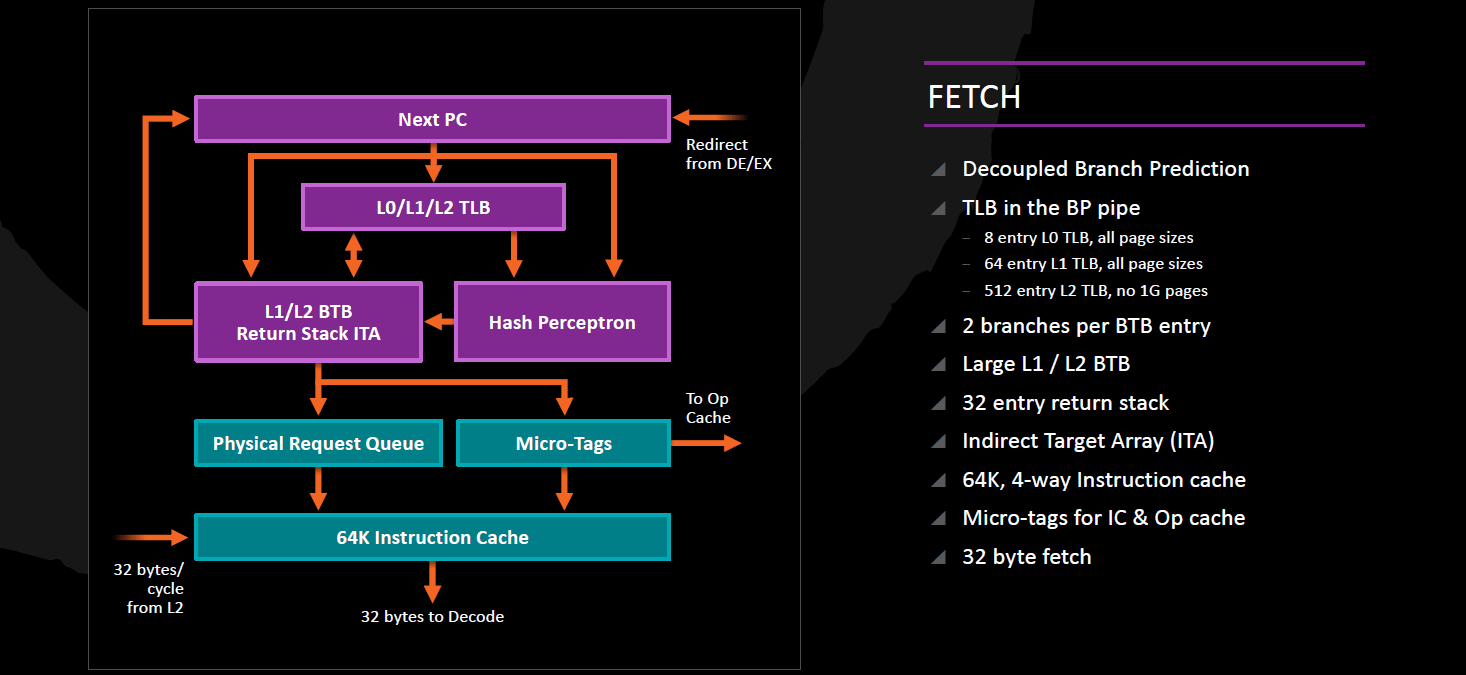
Az utasítás cache (L1I) címzéséhez használt ITLB-t (Instruction Translation Lookaside Buffer) tekintve azonnal két dolog szúr szemet:
- egyrészt az elágazásbecsléssel egybeépített, így a megkapott címet azonnal fordítja fizikai címmé, amely azonnal továbbítható a utasítás prefetcher-hez;
- másrészt 3, nevezetesen L0 (8 elem, teljes asszociativitás), L1 (64 elem, teljes asszociativitás) és L2 (512 elem, 4-utas csoport-asszociativitás) szintből áll, közülük az első két szint képes az 1 GB-os lapok kezelésére.
Micro-op cache
Az AMD korábbi processzoraiban nem találkozhattunk a lefordított utasítások micro-opjainak tárolásával, az Intel viszont a Sandy Bridge-től kezdve alkalmazza ezt. Immár a Zen is tartalmaz egy ilyen gyorsítótárat, amelynek pozitív következményei nyilvánvalóak: találat esetén nincs szükség az utasítás cache olvasására, sem pedig utasításdekódolásra, így az utasításoknak kettővel kevesebb futószalag-lépcsőn kell áthaladniuk, továbbá a téves elágazásbecslés büntetése is ennyivel kevesebb. Az elágazásbecslés által jósolt és az ITLB által lefordított fizikai címek közvetlenül e gyorstárat címzik, és találat esetén egy teljes vonal tartalma kerül továbbításra a feldolgozó egységek felé; ellenkező esetben innen kerül továbbításra az L1I-hez a cím kiolvasásra és dekódolásra, a fordítás eredménye ide (is) megérkezik lehetséges későbbi újrafelhasználásra.
A micro-op cache egy-egy vonala 8 darab, egyazon 64 bájtos memóriaszeletben található utasításokból származó micro-opot képes fizikailag tárolni, és azokat 1 órajel alatt továbbítani végrehajtásra. Összesen 256 vonalat tartalmaz 8-utas csoport-asszociatív elrendezésben, így elméleti mérete 2048 micro-op, szemben az Intel által alkalmazott 1536 uop mérettel; a teljes kapacitás viszont – az x86/x64 utasítások változó hosszúsága miatt – általában nincs teljesen kitöltve.
L1 utasításcache
Az AMD igen régóta, a K7, K8, K10 és az első generációs Bulldozer processzorokban (utóbbiban modulonként, azaz két mag között megosztva) 64 kB-os utasítás cache-t alkalmazott, amely 64 bájt vonalméretű és 2-utas csoport-asszociatív. Elmondható tehát, hogy kirívóan nagy méretű, de rémesen egyszerű felépítésű volt, amelynek hátránya már a K10-ben is megmutatkozott: az ott bevezetett utasítás prefetcher miatt a csoport egyik vonala az utoljára végrehajtott utasításokat, a másik pedig általában a prefetcher által spekulatívan előbetöltött instrukciókat tartalmazta. Ennek hátránya a Bulldozerben vált nyilvánvalóan korlátozó tényezővé, amikor is két utasításfolyam utasításait plusz az előbetöltött adatokat is tárolni kellett; vészmegoldásként az AMD mérnökei a Steamrollerbe 96 kB méretű, 3 utas csoport-asszociatív L1I-t építettek.
A Zen racionálisabb és kevésbé pazarló megoldást kínál a két párhuzamos utasításfolyam kezelésére, ugyanis visszatér a 64 kB mérethez, 4 utas csoport-asszociativitással megtoldva. Innen órajelenként 32 bájt olvasható ki, amely a legalább 16x16 bájt méretű Instruction Byte Buffer-be (IBB) kerül, ez szolgál arra, hogy az egyik 32 bájtos szeletben kezdődő, de a következőben végződő utasítások bájtjai egyszerre legyenek láthatóak. L1I tévesztés esetén az L2 cache-hez kell fordulni, ahonnan 32 bájt/órajel sebességgel érkezik meg az utasítás cache-be a kiolvasás eredménye.
Dekódolás
A Zen 4 egyszerű utasítás dekódert sorakoztat fel, amelyek az 1 vagy 2 micro-opra fordítható utasításokat tudják kezelni, azaz órajelenként legfeljebb 4 utasítást tudnak lefordítani, 4-8 micro-opot létrehozva. Az Intel processzoraihoz és a Bulldozer-család tagjaihoz hasonlóan az egymást közvetlenül követő összehasonlító (CMP) és ugró utasításokat képes 1 micro-oppá összegyúrni.
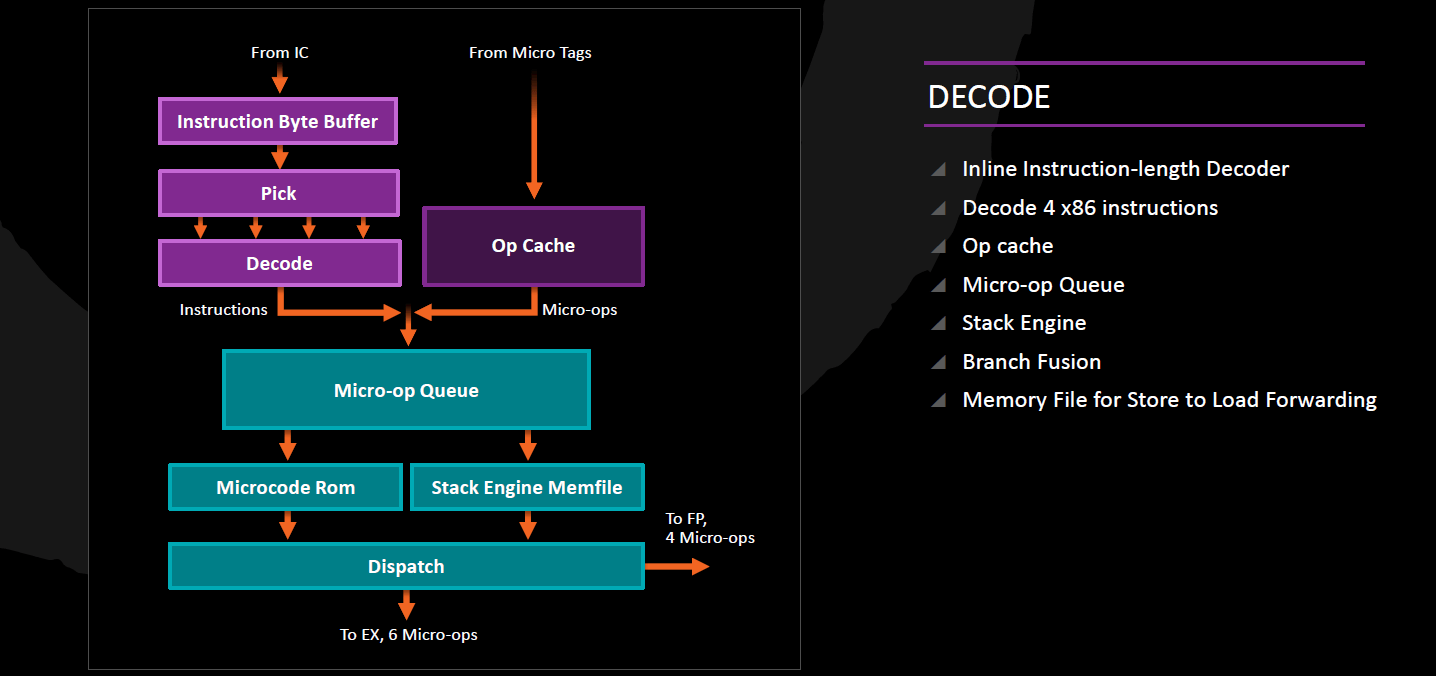
Az Intel ezt macro-op fusion néven emlegeti, bár ott általánosabb megoldást alkalmaznak: az összehasonlítás mellett az első utasítás lehet logikai bit-teszt (TEST), összeadás (ADD) vagy kivonás (SUB) illetve logikai ÉS (AND) is. A dekóderek mellett megtaláljuk a veremkezelő utasítások egyszerűbb, párhuzamosítható műveletekre fordítását végző Stack Engine-t is. Azon bonyolult utasítások, amelyek csak 2-nél több micro-opra fordíthatók le, a Microcode fordítóhoz kerülnek.
Micro-Op Queue, Retirement Queue
A lefordított utasításokból származó micro-opok tehát két helyről származhatnak, a dekóderekből, illetve szerencsésebb esetben a már ecsetelt Micro-op cache-ből. Akármelyik irányból is jöjjenek, a 72 elemű, a két programszál között statikusan 36-36 elemre felosztott Micro-Op Queue-ba kerülnek, amely átadja őket végrehajtásra 6 micro-op/órajel ütemben a 192 elemű Retirement Queue-nak. Itt tartózkodnak a micro-opok életciklusuk végéig, amely vagy a végrehajtásukat + programsorrendben történő véglegesítésüket jelenti vagy pedig – például téves elágazásbecslés miatti – kiléptetésüket. A véglegesítés órajelenként egy programszál legfeljebb 8, eredeti programsorrendben egymás után következő lefuttatott kész micro-opját tudja lekezelni.
Integer végrehajtás
Az AMD processzorok tradicionálisan különválasztják az egész számos illetve memóriaműveletek végrehajtását a lebegőpontos/vektor utasításokétól: a Zenben 4 végrehajtó portot találunk az integer műveleteknek, kettőt a memóriaírásnak illetve -olvasásnak, valamint további 4-et a lebegőpontos adatokon és/vagy vektorokon végrehajtandó műveleteknek. Az integer- és memóriacím műveletek közös 168 elemű fizikai regiszterfájlon osztoznak (lévén a memóriacímek is egész számok), amely önálló hatáskörben, végrehajtó egység igénybevétele nélkül el tudja végezni a regiszterből regiszterbe másolásokat (MOV reg, reg).
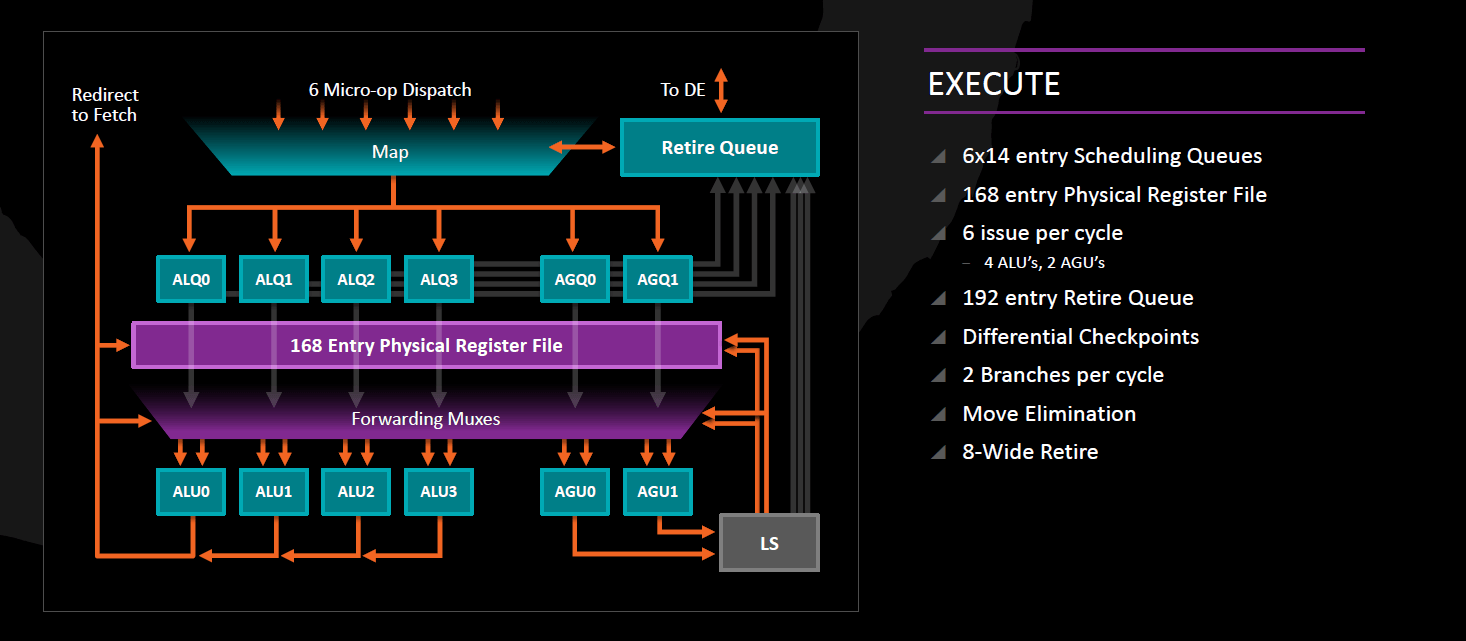
Maguk az integer műveletek részére tehát 4 darab végrehajtó port áll rendelkezésre, amelyekhez egy-egy 14 elemű ütemező és egy-egy ALU tartozik, amelyek mindegyike végre tudja hajtani az összes alapvető műveletet. Az egész számok szorzását csak az ALU1, osztását csak az ALU2 tudja kezelni, míg az ugró utasításokat az ALU0 és az ALU3 várja; utóbbiakat tehát 2/órajel ütemmel tudja újra végrehajtani - a K7, K8 és K10-hez hasonlóan -, mert ez a képesség a Bulldozer-család tagjaiból kikerült. Természetesen ezekből csak az egyik lehet valóban megtett ugrás, de mivel viszont rengeteg ciklus tartalmaz a cikluszáró utasításon kívül további ritkán megtett, viszont a helyességhez feltétlenül szükséges belső (pl. break vagy continue) ugró utasítást, ezen ciklusok optimális végrehajtásához hasznos ez a sajátosság; az Intel a Haswell-től kezdve képes erre.
Memóriaírás és –olvasás: AGU, DTLB, L1D
A memóriaműveletek kezelésére 2 portot találunk, egy-egy egyenként 14 elemű ütemezővel és egy-egy AGU-val ellátva. Mindkettő órajelenként egy-egy 128 bites adathozzáférés kezdeményezésére képes, így a 256 bites AVX memóriaműveletek 2 db 128 bites micro-opra fordítódnak és hajtódnak végre (a gather-utasítások még többre, ezeket a microcode dekóder kezeli). A memóriaírások és -olvasások végrehajtása szabadon átrendezhető egymás között, azaz teljesen out-of-order végrehajtást kínál a Zen, ehhez 72 elemű olvasási és 44 elemű írási sort alkalmaz. A memóriaírásokhoz szükség van egy további micro-opra is, amely a kiszámolt címre továbbítja a szükséges adatot; ezt bármely ALU végre tudja hajtani.
A kiszámolt címeket az Data Translation Lookaside Buffer fordítja fizikai címre, amely két szintű:
- az L1 szintje 64 elemű, teljesen asszociatív, és a 4 kB, 2 MB és 1 GB lapok kezelésére egyaránt alkalmas
- míg az L2 1500 elemű, 6-utas csoport-asszociatív és a 4 kB illetve a 2 MB méretű lapok információit tartalmazhatja
A Zen két független – adatra és utasításra is alkalmazható - laptábla bejáró egységet (page walker) vonultat fel, mint ahogy a Broadwell óta az Intel CPU-i is.
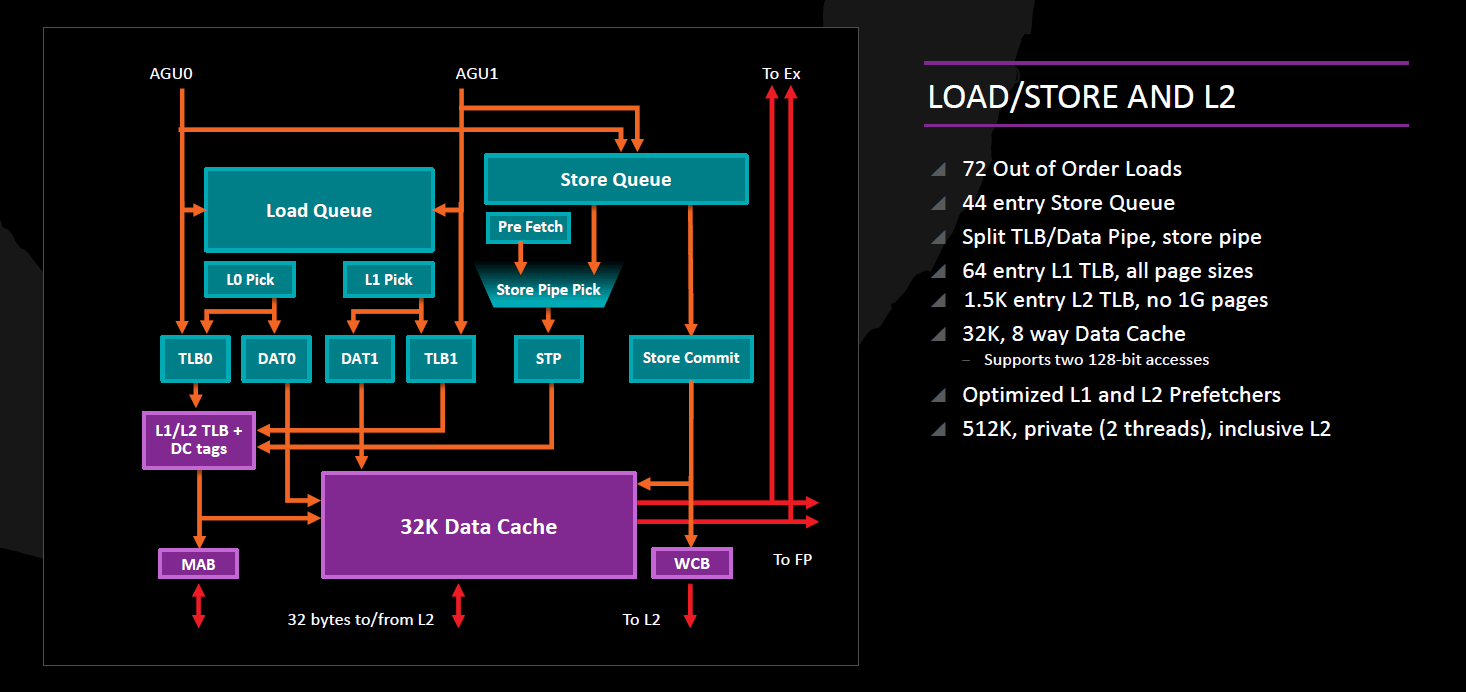
A DTLB által kiszámolt fizikai címek az L1 adatcache-hez (L1D) kerülnek, melynek mérete 32 kB, vonalmérete 64 bájt és 8-utas csoport-asszociatív. Az L1D órajelenként legfeljebb két darab 128 bites memóriaolvasást és legfeljebb egy darab 128 bites memóriaírást tud végrehajtani; azaz összesen 3 hozzáférést kínál órajelenként, noha a két AGU órajelenként maximum két címet tud kiszámítani. Az L1D késleltetése 4-5 órajel integer adat olvasását/írását tekintve, és +3, azaz összesen 7-8 órajel, ha az olvasást vagy írást lebegőpontos vagy vektoros utasítás kezdeményezte. Viselkedését tekintve write-back cache (ellentétben a Bulldozer-család igencsak korlátozó write-through mechanizmusával), azaz az adatmódosítások nem jelennek meg azonnal a további cache-szint(ek)en; a koherenciát tekintve MOESI protokollt használ. A Zen kínál egy utasítást (CLZERO néven), amely egyetlen egyszerű művelettel egy teljes 64 bájtos cache-vonalat kinulláz.
Lebegőpontos és vektoros végrehajtás
Az AMD processzorokra jellemző módon az FPU külön részegységet képez a magon belül, és önálló kétszintű ütemezővel, saját 160 elemű regiszterfájllal valamint négy darab végrehajtóegységgel rendelkezik. Ezen végrehajtók 128 bit szélesek, így a 256 bites AVX- és AVX2-műveletek kétszer annyi erőforrást igényelnek, mint a 128 bites operációk. Az FPU által feldolgozott műveletek a lefordításuk után szintén a korábban említett 192 elemű Retirement Queue-ba kerülnek és ott is tartózkodnak a végrehajtásuk befejezéséig, viszont végrehajtásukhoz szükséges regisztereket az FPU 160 elemű regiszterfájlja biztosítja, és az összesen 96 elemű kétszintes FPU ütemező dönt az out-of-order végrehajtásukról:
- minden lebegőpontos és vektoros micro-op először az első szintű ütemezőbe kerül, amely megvizsgálja őket, és a konkrét számítási műveletet valóban tartalmazóakat továbbküldi a másodszintű ütemezőnek, amint abban van szabad kapacitás; ez utóbbi osztja el azokat a végrehajtó egységek között
- azokat a micro-opokat, amelyek viszont nem tartalmaznak számítási feladatot (ilyen pl. a memóriaolvasás, tárolás, integer<->FPU regisztermásolás), az integer egység felé küldi feldolgozásra.
Az FPU 2 db 128 bites FMUL (szorzás, FMA, AES) és 2 db 128 bites FADD (összeadás, kivonás, összehasonlítás) végrehajtót tartalmaz; utóbbiak alkalmasak a speciális feladatok ellátására is: az egyik FADD feladata a tárolás és az integer vektorok bitléptetése/bitrotációja, míg a másik felel számkonverziókért, az osztásért és a gyökvonásért. Mind a négy pipeline képes a vektorregiszterek másolására és a rajtuk végzett bitműveletek (AND, OR, XOR) kezelésére. A vektorelemek átrendezésére (shuffle, pack, permute) az egyik FMUL és az egyik FADD alkalmas.
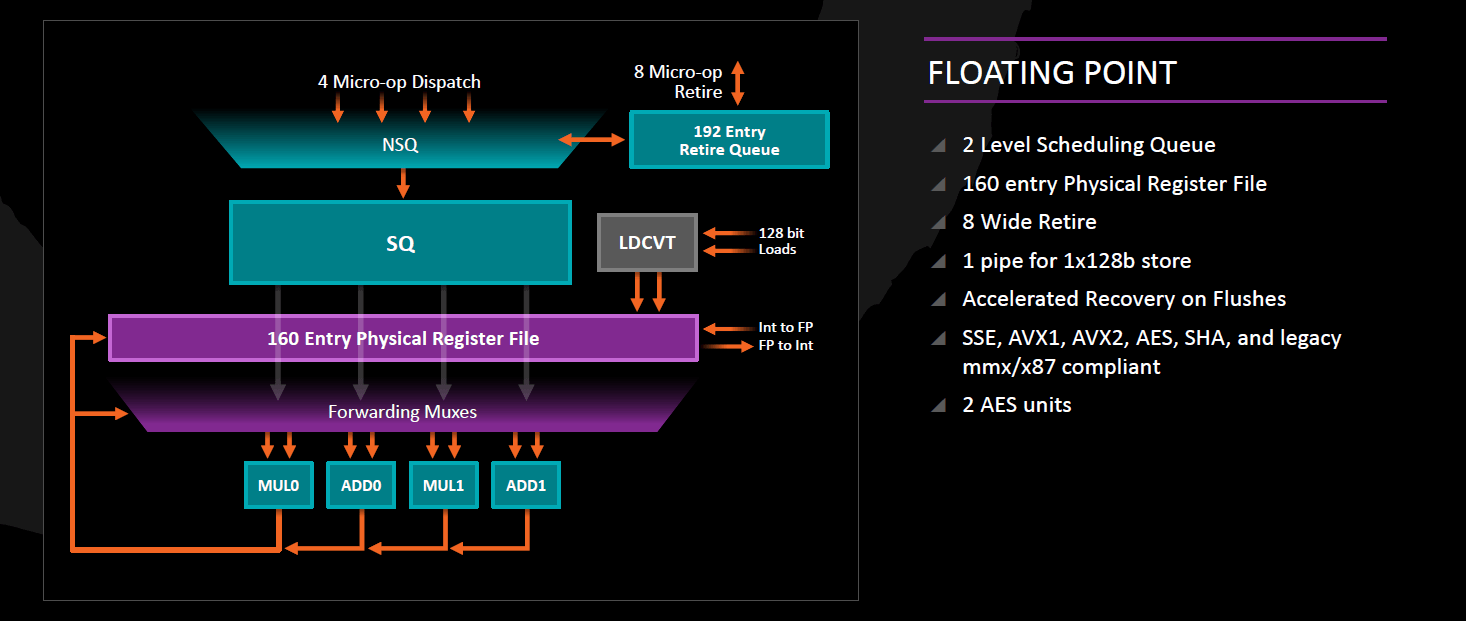
Az FMA műveletek időigénye 5 órajel, és ezekből párhuzamosan csak 2 db hajtható végre, mivel egy-egy FMA kiszámítását ugyan az FMUL végrehajtó végzi, viszont a 3. paramétert az egyik FADD olvassa ki a regiszterfájlból. A lebegőpontos szorzás időigénye egyszeres pontosságú (32 bit) adatra 3 órajel, kétszeres pontosságúra (64 bit) 4 órajel, extended (80 bit) 5 órajel, az összeadás/kivonás végrehajtási ideje 3 órajel. A vektoros integer-műveletek jelentős része 1 órajel alatt lefuttatható (a korábbi AMD-processzoroknak ezzel szemben ezekhez 2 órajelre volt szükségük).
Másodszintű gyorsítótár (L2 cache)
A Zen minden magját 512 kB méretű, 64 bájtos vonalméretű, 8-utas csoport-asszociatív saját L2 cache-sel szereli, amely inkluzív a mag összes adatára és utasítására nézve, azaz tartalmazza az L1I, az L1D és a micro-op cache tartalmát is.
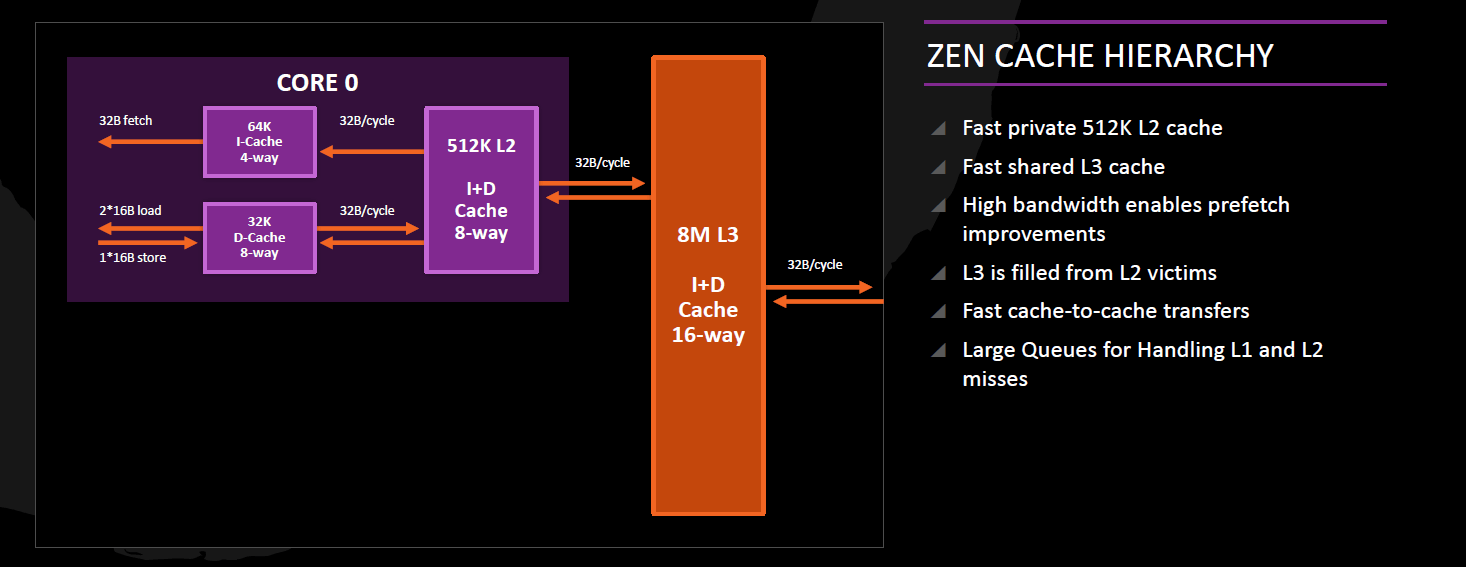
Ennek pozitív hatása a teljes – főleg sokmagos – rendszer memóriakoherenciáját fenntartó, háttérben zajló címforgalomnál (snooping) érhető tetten. Az L2 cache 32 bájt/órajel szélességű busszal kapcsolódik az adott mag mindkét L1 cache-éhez.
Harmadszintű gyorsítótár (L3 cache) és Core Complex (CCX)
Az első generációs Zen processzorok alapvető felépítő egysége a négy darab magból és ugyanennyi L3-szeletből álló Core Complex (vagy CCX). Jelenleg a szeletek mérete 2 MB, kiadva a 8 MB összkapacitás, de a dokumentációk szerint később lehetnek olyan variánsok is, amelyekben 4x1 MB lesz az L3 mérete. Az L3 átlagos késleltetése 35 órajel. A Core Complexen belüli magok ezen az L3 cache-en keresztül tartják a kapcsolatot, amely jellemzően exkluzív a magok L2-ben – és így az L1 cache-ekben – tárolt privát adataira nézve, és az onnan helyhiány miatt kikerülő adatokat tárolja (azaz victim cache). A L3 cache vezérlő logika a kérdéses adat címéből számolt hash eredménye alapján dönti el, hogy az melyik szeletbe kerül és mind a négy mag L2 cache-ének mind a négy szelethez van hozzáférése egy-egy 32 bájt/órajel keresztmetszetű buszon keresztül.
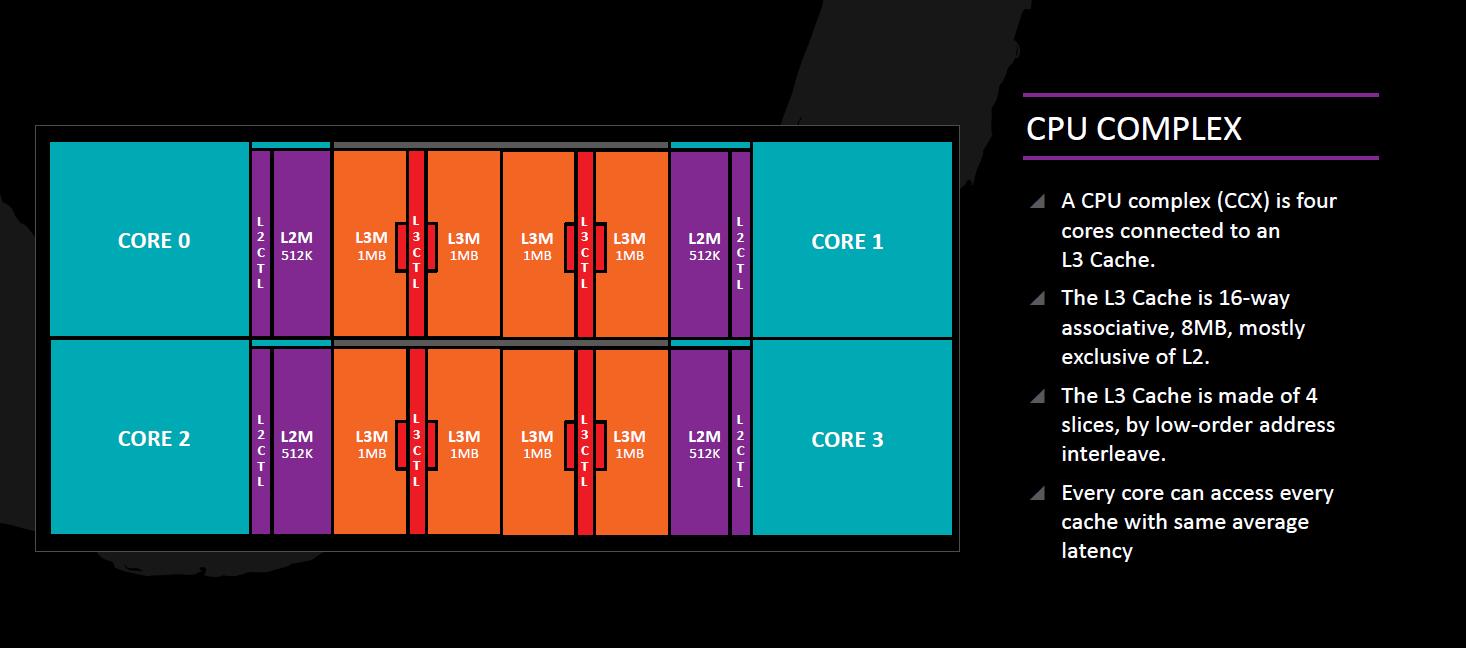
Az L3 cache továbbá egy adminisztrációt is vezet a Core Complex-beli négy mag L2-jének tartalmáról, ezáltal a kihasználható mérete valamivel kisebb, mint 8 MB. Amennyiben egy magnak az L3-hoz kell fordulnia, mivel nem találja a keresett adatot a saját L2 cache-ben, és az L3-ban sem található, akkor kerül ellenőrzésre az adminisztrációs táblázat: ebből kiderül, hogy egy másik mag L2-jében fellelhető-e a kérdéses adat és ha igen, onnan közvetlen úton kiolvasható.

Az AMD belső mérései szerint a vadiúj mikroarchitektúrával sikerült túlszárnyalni az indulásnál kitűzött célt, a Zen első iterációja 52 százalékkal magasabb IPC-t nyújt a Bulldozer vonal utolsó állomását jelentő Excavatorhoz képest, azaz azonos órajelet feltételezve ennyivel gyorsabb egyetlen szálon a Zen.
Fizikai implementáció
Ahogy azt az AMD elmúlt nagyjából egy évtizede is remekül szemlélteti, a jó mikroarchitektúra fabatkát sem ér a magok mellé pakolt megfelelően gyors és hatékony gyorsítótárak, vezérlők, buszok, valamint a mindezt szilíciumba öntő, versenyképes gyártástechnológia nélkül. Az AMD-nek elsősorban utóbbival gyűlt meg a baja, a 2008-ban bemutatott 45 nanométeres csíkszélesség óta folyamatosan komoly hátrányban volt a cég, az Intelhez mért lemaradása pedig idővel egyre csak nőtt, a napokban piacra kerülő Zenig másfél lépcsős (28 vs. 14 nanométer) hendikepet halmozva fel riválisához képest.
Utólag visszanézve a sors iróniájának tűnik, hogy bár az okostelefonos piac teljesen állva hagyta az AMD-t, a cég közvetett módon mégis az éves szinten értékesített több száz millió darab készüléknek köszönheti, hogy hosszú idő után ismét versenyképes technológián gyártathatja termékeit. A vállalat számára elérhető bérgyártók ugyanis az okostelefonos forradalmon felkapaszkodva gyorsították meg fejlesztéseiket, illetve építettek újabb milliárdos üzemeket, mindezt például az Intel kárára, amely cég okostelefonos kirándulása masszív kudarcnak bizonyult, és végül az Atomok teljes visszavonultatására sarkallta a legnagyobb processzorgyártót.
Miközben az Intel elzárkózott a klasszikus bérgyártói szerep felvállalásától és a konkurens ARM architektúrára épülő chipek gyártásától, addig a Samsung és a TSMC éves szinten több milliárdos bevételt köszönhetett az üzletnek. Előbbi vállalat ebből fejlesztette ki első FinFET gyártástechnológiáját a 14 nanométeres 14 LPE-t (Low Power Early), amin például az iPhone 6s processzorainak egy része készül(t). A dél-koreai cég ezt továbbfejlesztette, az így született 14 LPP (Low Power Plus) pedig 15 százalékkal alacsonyabb fogyasztást, illetve 15 százalékkal magasabb órajelet biztosít az első generációs fejlesztéshez képest, az előrelépést a tranzisztor struktúra és a gyártási folyamat egyes részeinek optimalizálásával érték el a tervezők.
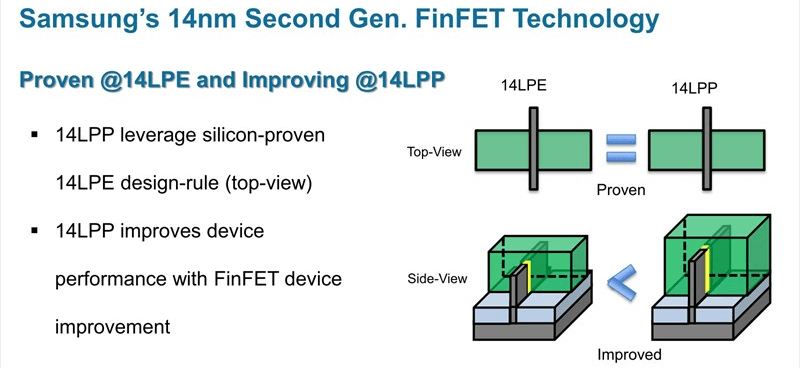
A 14 LPP-n számos lapkadizájn készült már, az Exynos 8 Octa rendszerchipek mellett a Qualcomm Snapdragon 820 és 821 is ezt alkalmazza, akárcsak az Nvidia Pascal GPU-sorozatának legkisebb, GP107 kódjelű tagja. Az AMD a GlobalFoundries üzleti döntése miatt került kapcsolatba a Samsung megoldásával, a közel-keleti érdekeltségű vállalat ugyanis három éve a flexibilitást igénylő ügyfelekre hivatkozva úgy döntött, hogy saját fejlesztésű 14XM eljárását sutba dobva a dél-koreaiak fejlesztését licenceli, magyarul inkább fizet konkurensének, mintsem egy újabb bizonytalan fejlesztéssel hozza hátrányba magát és partnereit.
A döntés az AMD számára nem jöhetett volna jobbkor, amely cég ezzel megfelelő alapot kapott következő generációs termékeihez, amit elsőként a tavaly bemutatott Polaris GPU-kkal próbálhatott ki tömegtermelésben. A Zen mikroarchitektúrát manifesztáló lapkadizájn is ezen a gyártástechnológián készül néhány, a nagy teljesítményhez (magas órajelhez) szükséges módosítás mellett.
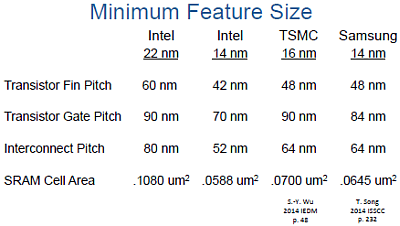
Köztudott, hogy a félvezetőgyártók által alkalmazott jelölésrendszer már évek óta nem fedi az egyes technológiák mögött húzódó valós csíkszélességet, a cégek jóformán bármit eladhatnak, nincs szabványosítva, hogy milyen paraméterekkel kell rendelkezzen az adott technológia. Ennek megfelelően a Samsung 14 LPP tranzisztorsűrűsége gyengébb az Intel 14 nanométeres megoldásánál, hasonló lapkadizájn esetében az eltérés nagyjából 37 százalékos lenne, a dél-koreaiak fejlesztésével körülbelül ennyivel nagyobb területű lapka gyártható le. Ez bár kisebb hátrány az AMD számára, a korábbi tetemes lemaradást sikerült töredékére faragni. A Kaveri, Carrizo és Bristol Ridge APU-knál alkalmazott 28 nanométer 2,37-szer nagyobb lapkákat produkált az Intel 14 nanométeréhez képest, ami a gyártási költségek és az elérhető tranzisztorteljesítmény (és fogyasztás) tekintetében egyaránt komoly hendikepet jelentett.
Az AMD eddig egyetlen, Zen magokat alkalmazó lapkadizájnt tervezett, a 12 fémrétegből felépülő szilícium egyes főbb paramétereit még nem erősítette meg tervezőcég, iparági pletykák szerint az összesen nyolc processzormagot tartalmazó lapka 4,8 milliárd tranzisztor vonultat fel 192 mm2-en. A lapka területe a többi hivatalos adat alapján reálisan hangzik, a tranzisztorok száma viszont elsőre hallásra elég hihetetlen, az Intel ugyanis az alapból jobb sűrűséget biztosító eljárásával a 246 mm2-es Broadwell-EP-be csak 3,1 milliárd tranzisztor tudott besűríteni. Amennyiben a számok mégis helyesek (és az AMD nem számolta ismét el a tranzisztorokat), úgy az egyetlen reális magyarázatot a HDL (High Density Library) jelentheti.
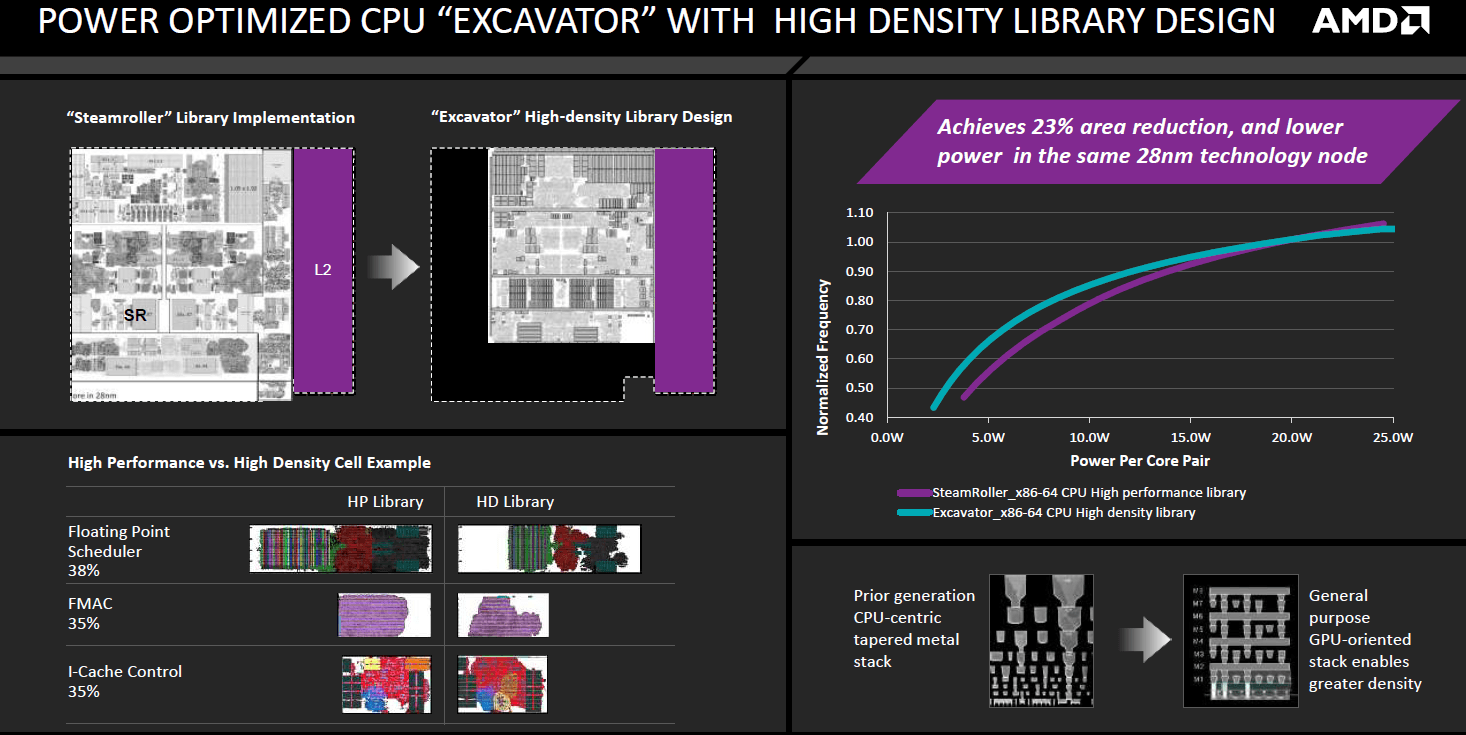
Az AMD először 2012 augusztusában beszélt az automatizált eljárás CPU-s kiterjesztéséről. A GPU-k tervezéséhez már régóta használt módszer jóval sűrűbb áramkörök létrehozását teszi lehetővé, azaz helytakarékosabb a "kézi" tervezésű, kvázi sztenderd HP (High Performance) variánsnál, miközben jóval alacsonyabb fogyasztást is biztosít. CPU magoknál elsőként Carrizoban vetette be a HDL-t a cég, így az Excavator magok területe 23, energiaigényük pedig 40 százalékkal csökkent az előd Steamrollerhez képest. Az eljárásnak természetesen hátránya is van, ugyanis alkalmazásával a korábbi módszerhez mérten alacsonyabb órajel érhető el, ami részben megkérdőjelezi a felvetést, miszerint a Zen tervezésénél is alkalmazták az eljárást, így a fantasztikus tranzisztorsűrűségre egyelőre nincs sziklaszilárd magyarázat.
Ennek ellenére a lapka mérete hosszú idő után biztató lehet az AMD számára, az összesen 8 processzormagot és 20 megabájt (nyolcszor 0,5+2 MB) gyorsítótárat kínáló Zennél nagyjából 28 százalékkal nagyobb a 10 processzormagot (+25%) és összesen 27 megabájt gyorsítótárat (+35%) kínáló legkisebb Broadwell-E(P), tehát hasonló gyártási költségekkel kalkulálva közel lehet egymáshoz az azonos lapkaméretre levetített előállítási költség. Az egy lapkára levetített pontos kiadás természetesen hétpecsétes üzleti titok, ezt sem az AMD, sem pedig az Intel nem árulja el.

Cserébe a Zent tervező cég részletesen beszélt a végleges szilíciumlapka egyes paramétereiről. Egyetlen négymagos Core Complex (CCX) építőelem 44 mm2 alapterületű, amelyben négyszer 1,5 mm2-t, azaz összesen 6 mm2-t foglalnak el a magonkénti az 512 kB-os másodszintű gyorsítótárak és 16 mm2-t a 8 MB-os L3 cache. Ebből könnyen kiszámolható, hogy egyetlen másod- és harmadszintű gyorsítótár nélküli Zen mag 5,5 mm2-nyi szilíciumot emészt fel. (Érdekesség: a hasonló gyártástechnológián készülő Apple A9 egyetlen Twister magjának területe körülbelül 4,3 mm2.)
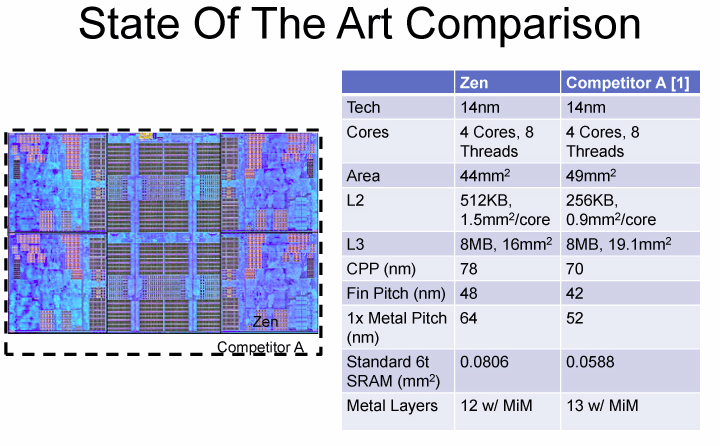
Összehasonlítás gyanánt az AMD egy meg nem nevezett (Intel) konkurens termékkel helyezte párhuzamba fejlesztését. A vélhetően Broadwellt takaró adatok szerint az Intel L2 és L3 gyorsítótára a jobb tranzisztorsűrűséget biztosító gyártástechnológia ellenére is nagyjából 20 százalékkal több helyet foglal, miközben egyetlen Intel mag 6,575 mm2 területet emészt fel. Ezekből elsősorban a gyorsítótárak értékeit lehet összevetni, ahol az AMD előnyét az esetleges lassabb SRAM-mal vagy a már feljebb említett HDL eljárással lehetne magyarázni, a kérdésre a teszteredmények adhatnak majd választ. Mindent egybevéve az AMD négymagos blokkjánál körülbelül 11,4 százalékkal nagyobb az Intel ugyanennyi magot tartalmazó szekciója, miközben abban 1 megabájttal kevesebb L2 cache található.
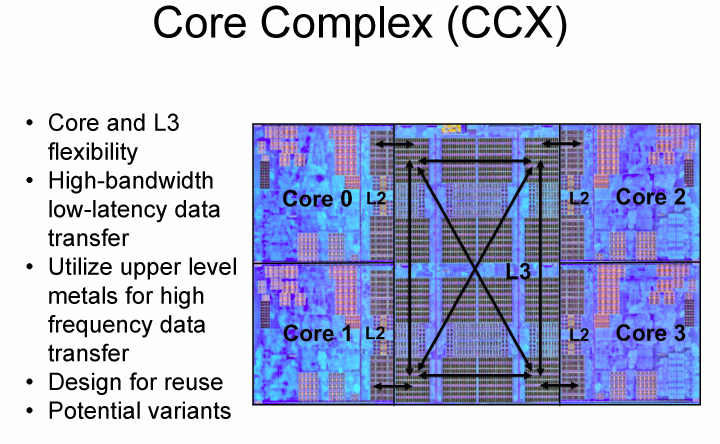
Az eddig ismert egyetlen, Zeppelin (ZP) kódnevű lapkadizájnba az AMD két CCX-et pakolt, jelen állás szerint a cég az asztali PC-k és a szerverek piacát is ezzel próbálja lefedni. A legelső Zenre épülő dizájn összesen kétszer négy processzormagot és kétszer nyolc megabájt harmadszintű gyorsítótárat tartalmaz, amely alapvető felépítésében leginkább az Xbox One-nál és PlayStation 4-nél látottakat idézi, ahol szintén négy-négy különálló (Jaguar) mag osztozik egy-egy nagy (ott másodszintű) gyorsítótáron.
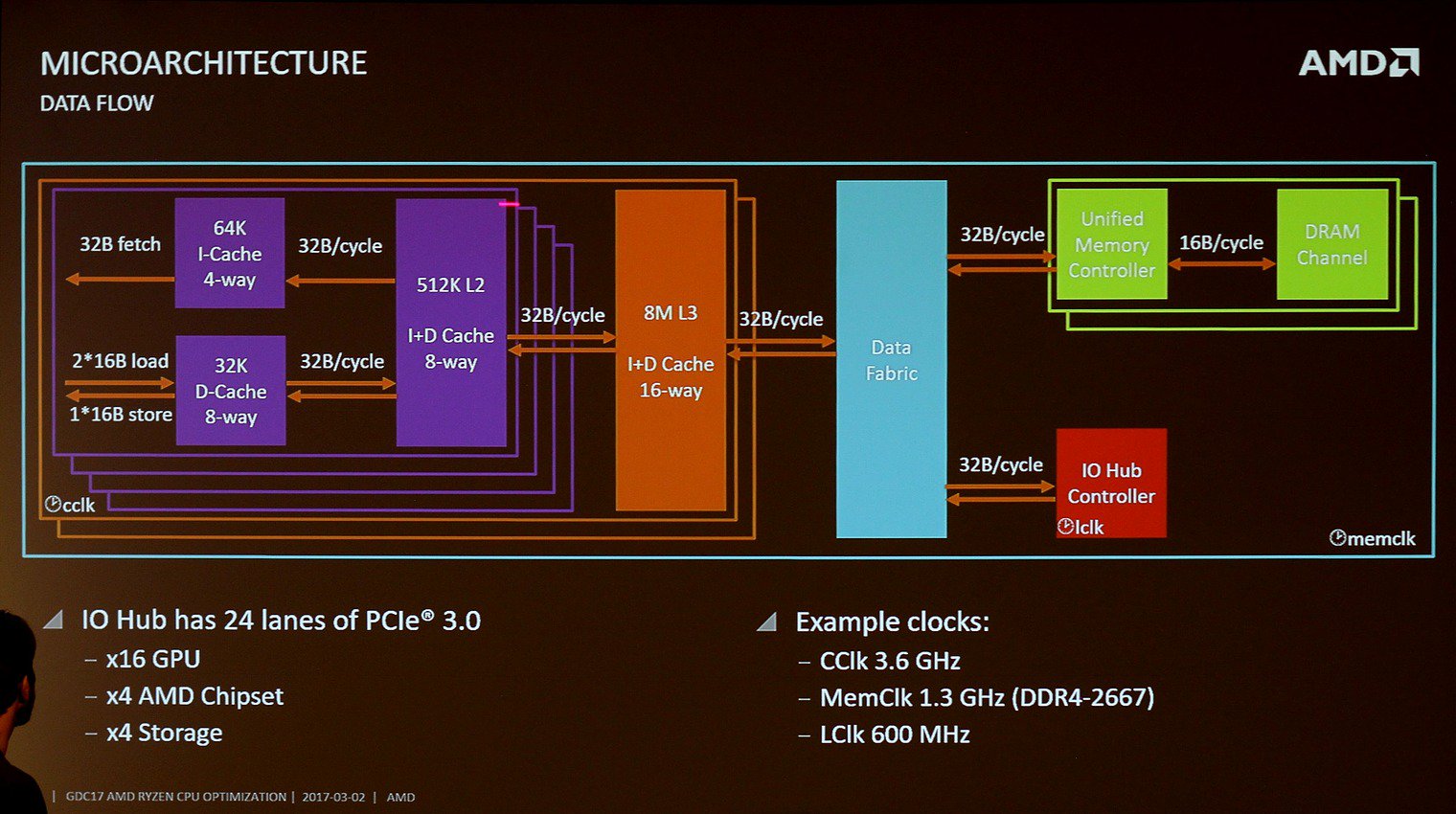
A Zeppelin esetében egy darabig nem volt egyértelmű, hogy közös gyorsítótár híján pontosan hogyan cserél adatot egymással a két négymagos CCX. Az AMD dokumentációja szerint a két complexet egy – egyelőre nem részletezett – koherens 32 bájt/ciklus sebességű busz köti össze. A processzorok bemutatását követően világosság vált, hogy a kapcsolat nem közvetlen, az egy-egy CCX a Data Fabrichoz kapcsolódik, amelynek mindenkori órajele egyezik a rendszermemória órajel-frekvenciájával (MemClk). Ennek megfelelően a hivatalosan támogatott leggyorsabb, DDR4-2667-es memóriák mellett 40,67 GB/s a két magkomplexum közötti sávszélesség, amely a memória órajelének növelésével párhuzamosan emelkedik.
A sávszélesség az esetek többségében nem eredményez komoly limitációt, a hosszabb adatút miatti magasabb késleltetés azonban bizonyos szituációkban számottevően befolyásolhatja a processzor számítási teljesítményét. A jelenség okát jól szemlélteti a PC Perspective részletes elemzése, amely szerint a CCX-en belüli magok között 40-45 nanoszekundum a késleltetés, ami a két CCX között ingázva ennek több mint háromszorosára, körülbelül 140 nanoszekundumra nő.
Windows frissítés kellhet
Az rendhagyó elrendezéssel több processzoros rendszerek esetében akár ötszintű is lehet a topológia (foglalat->lapka-> CCX->mag->szál), amelynek optimális használata megfelelő ütemezést kíván az operációs rendszer oldaláról. Egy egyszerűbb, nyolc magos processzort feltételezve első körben egyetlen CCX magjait célszerű terhelni, ezzel kiiktatva a két complex közötti kommunikáció szűk keresztmetszetét, miközben így a másik CCX-et az energiamenedzsment teljesen lekapcsolhatja, a felszabadult fogyasztási keretből pedig turbóval maximalizálhatja az aktív magok órajelét.
Hasonlóan fontos, hogy az operációs rendszer először a processzormagok páros szálait terhelje (0, 2, 4, 6, stb.), az SMT miatt ugyanis két egyetlen magon belüli szál jóval lassabb végrehajtást kínál mint két mag egy-egy szála (kb. 2x60% vs. 2x100%). Az Intel Hyper-Threading támogatott processzorainál ez Windows 7 óta így működik, arról viszont egyelőre nincs információ, hogy a Zen-alapú termékekhez elkészült-e már a Microsoft optimalizációja, mindenesetre a fejlesztés létjogosultságát mutatja, hogy 4.10-es Linux kernel már a rendhagyó topológiát szem előtt tartva kezeli majd az AMD új processzorait.
Energiamenedzsment
A rendelkezésre álló mindenkori TDP keretet több technológiával próbálja a lehető leghatékonyabban kiaknázni az vezérlés. Ehhez az AMD számos ügyes trükköt dolgozott ki az elmúlt években, a másodvonalbeli gyártástechnológiák mellett a cég rá volt utalva az alternatív megoldásokra, amiket a Zennél újra fel tudott használni, ezzel javítva a hatékonyságon. Így a lapkában a Carrizóval bemutatott, majd a Bristol Ridge-dzsel továbbfejlesztett AVFS (Adaptive Voltage and Frequency Scaling) is helyet kapott, amely ezzel már harmadik verziónál jár.
A lapka több pontján elhelyezett apró AVFS modulok folyamatosan mérik a pillanatnyi frekvenciát, feszültséget, hőmérsékletet, illetve az ezekből fakadó disszipációt, az értékek birtokában pedig a rendszer valós időben, gyorsabban és pontosabban képes reagálni az egyes körülményekre, azaz beállítani a pillanatnyi optimális működéshez szükséges kritikus paramétereket (feszültség, órajel), amivel például maximalizálható a turbó órajele, ezzel pedig javítható a fogyasztás/teljesítmény mutató. Ugyancsak ezen segít, hogy a frekvenciát 25 MHz-es fokozatokban képes adagolni a vezérlés, ami 100 MHz-es referenciaórajel mellett tört szorzókat használ (pl. 20,75x).

Szintén az energiamenedzsmentet szolgálja, hogy az egyes magok feszültsége és órajele is külön-külön állítható, az L2 és L3 cache pedig különálló fázist kapott. A feszültségszabályzóról viszont nem beszélt az AMD, a vállalat bő két éve még azt tervezte, hogy beépít az Intel Haswellben látott integrált megoldást, erre viszont úgy fest egyelőre nem került sor, igaz időközben ettől az Intel is visszalépett.
Azt ugyan csak az AMD tudná megmondani, hogy az évek alatt felépített technológiák pontosan mennyit tesznek hozzá a Zenhez, mindenesetre a végeredmény felülmúlja a piac várakozásait, a nyolcmagos asztali csúcsprocesszor ugyanis 95 wattos TDP keret mellett 3,6 GHz-es alapórajelet és 4 GHz-es turbót kínál, ami kétség kívül versenyképes, az elmúlt 10 évben látottakkal ellentétben erős kezdést ígér. Talán ennél is érdekesebb lesz, hogy a szerverekbe szánt 32 magos Zenből mekkora órajelet tud majd kisajtolni a cég, az eddig látottak alapján ott is van esély a meglepetésre.
Kigyúrt rendszerchip GPU nélkül
A két, processzormagokat tartalmazó CCX mellé egy egész vezérlőarmadát pakolt be az AMD, a GPU hiányától eltekintve a Zeppelin lapka rendszerchipnek nevezhető, amire elsősorban most is a szerveres felhasználás miatt van szükség. A már évek óta alapfelszereltségnek számító memóriavezérlő kétcsatornás, az 3200 MHz-en is támogatja a DDR4 modulokat, de a kiszolgálók miatt a Flash/NV DIMM-ek is támogatottak. Ezek mellé összesen 32 darab Gen3-as PCI Express sáv került, amiből igény szerint legfeljebb 8 darab SATA portként is konfigurálható. Ugyancsak a szerverek miatt került be egy 4 darab 10Gb Ethernet port kiszolgálására képes vezérlő a lapkába, amit asztali környezetben nem vezet ki az AMD, szemben a négy USB 3.0 porttal, ami alapértelmezetten elérhető mindkét területen. Ezek mellett még a rendszer alapvető működéséhez szükséges ACPI, RTC, LPC, SMBus, SPI, illetve az órajelgenerátor is a lapka része, amelyben az egyes elemeket a Scalable Data Fabric kapcsolja össze.

A Zeppelin lapka fotója, jól kivehető a két különálló CCX
A szerveres verziók esetében az AMD több, legfeljebb négy Zeppelin lapkát tehet az SP3 foglalatos processzorok tokozásába, ilyenkor az egyes vezérlők összeadódnak, így például a memóriacsatornák száma 8, a PCI Express sávok száma akár 128, az Ethernet portokból pedig 16 darab is kivezethető. Az egyes különálló lapkákat, illetve az alaplapon lévő esetleges több processzorfoglalatot egy teljesen új interkonnekttel drótozták össze a tervezők, a HyperTransportot váltó Global Memory Interconnect (GMI) lapkánként négy 16 bites linket kapott, de hogy ezek pontosan mekkora átviteli sebességre képesek, azt az AMD egyelőre nem árulta el.
A több lapkából összelegózott szerveres processzorok koncepciójának számos előnye van. Ily módon lényegesen egyszerűbb a gyártás, négy kisebb lapkát sokkal könnyebb (jól) legyártani, mint egy nagy monolitikusat, a kisebb egységekből pedig viszonylag rugalmasan alakíthatóak ki az egyes, különféle piacokat célzó termékek - nem véletlen, hogy az IBM POWER sorozatú lapkák is évek óta használják ezt a megközelítést. A hátrányok közzé sorolható a megfelelően gyors, alacsony késleltetésű interkonnekt kifejlesztése és üzemeltetése, valamint a bonyolultabb, és így drágább tokozás. Utóbbiak ellenére az irány mellett több érv szól mint ellene, amit mi sem bizonyít jobban, mint hogy a jövőben a konkurens Intel is rálép az útra, ezzel pedig a hatalmas, akár sok milliárd tranzisztoros monolitikus CPU-k kora leáldozik.
Mit hozhat a jövő?
Látható tehát, hogy a Zen struktúrája alapvetően egy nagy ugrás – talán a legnagyobb a cég történetében – a megelőző generáció(k)hoz képest, gondoljunk csak a K7-K8-K10 vonal inkrementális, lassú és megfontolt fejlesztésére, amelyektől a Bulldozer-família is sok koncepciót megörökölt (amelyeket nem, azoknak egy része sajnos visszalépésnek tekinthető). Ezzel az AMD egy csapásra beérni látszik az Intel jelenlegi processzorait, azonban ne legyenek illúzióink: a cég – méretéből és fejlesztési potenciáljából adódóan még nagyon messze áll az Intel pozícióitól.
Az Intel eddig képes volt folyamatosan és kiszámíthatóan fejlesztéseket, átalakításokat eszközölni termékvonalában, hogy választ adjon a (közel)jövő kihívásaira (pl. tranzakcionális memóriakezelés, 256 és 512 bites vektorokon végzett műveletek vagy az Atom-termékek teljes out-of-order megújulása), addig a másik véglet a VIA, amely egyetlen nagyobb léptékű fejlesztés alkalmával kidolgozott alapkoncepcióját (Nano) kénytelen akár 10 évig is csiszolni, alakítani, és több-kevesebb sikerrel a mindenkori jelenben elhelyezni azt egy adott ár- és teljesítménypozícióban.
Az AMD ugyan képesnek látszik rendszeresen kifejleszteni megújult alapokon nyugvó termékpalettát (Bulldozer, Bobcat/Jaguar, Zen), de látva milyen sokáig tartott, amíg a Bulldozer-termékek után valóban versenyképes, egyszerre teljesítmény- és fogyasztásorientált fejlesztést mutattak be, felismerhető, hogy a Zen az AMD következő legalább 5 évének meghatározó fejlesztése lesz. Jelenleg nehéz megmondani, hogy erre az időre milyen inkrementális fejlesztéseket tartogat tarsolyában az AMD – illetve milyen szűk keresztmetszetek jelentkeznek majd, lásd a Bulldozer L1I-jét –, de a most bemutatott megoldást néhány helyen biztosan kiegészítik a következő generációkban:
- az egymást követő összehasonlító+ugró utasítások fúzióját bizonyára ki fogják egészíteni az Intel CPU-iban látott szintre, hiszen az a számolt lefutású ciklusok végrehajtására van pozitív hatással
- az L1D bár 3 hozzáférésre képes órajelenként, egyelőre 2 AGU számolja a címeket hozzá, ezt a kissé kiegyensúlyozatlan helyzetet egy harmadik AGU bevezetésével (amint azt a Haswell tette) kezelni lehet
- a 256 bites AVX/AVX2 végrehajtás nem esszenciális fontosságú napjainkban, illetve az AMD egyféle maggal akarja lefedni egyszerre a legnagyobb (szerver), a közepes (asztali) és a legkisebb energiakeretű (notebook) portfólióját is; valamint az APU-széria továbbfolytatása miatt is érdemes volt minél kisebb méretű és étvágyú processzormagot alkotni, kihagyva a nem általánosan szükséges részegységeket. Így kétes kimenetelű lépés lett volna beépíteni, majd az energiahatékonyság érdekében a termékek nagy részében letiltani a 256 bites végrehajtást az első iterációban. Mindenesetre ha a jövőben némiképp diverzifikálódik a termékpaletta és több, némileg eltérő magdizájnt is alkalmazni fog az AMD, talán találkozhatunk egyes felső kategóriás termékeiben a kiszélesített vektorvégrehajtókkal.
Mike Clark, a Zen vezető tervezője a tavaly augusztusi Hot Chips konferencián elmondta, hogy a határidők tartása miatt végül számos fejlesztést kellett kihagyjanak a Zenből. Ezek egy részét sikerült más módszerrel helyettesíteni, a megmaradt másik adagot pedig lehetőség szerint igyekeznek beépíteni a következő iterációkba, a szakember szerint újabb ötletekből nincs hiány, megfelelő fejlesztési potenciállal rendelkezik a Zen.
A mikroarchitektúra második és harmadik verzióján már dolgozik a cég, de hogy azok pontosan mikor kerülhetnek piacra, arról az AMD egyelőre nem beszélt. A vállalatnak nincs vesztegetni való ideje, az Intelhez képest lényegesen szerényebb költségvetése ellenére teljes gőzzel, az ütemtervet szigorúan betartva kell fejlesztenie, máskülönben a történelem (újra) megismétli önmagát.