Kimagasló tempót diktál a Google saját gyorsítója
Kiderült, hogy milyen technológia lapul a gépi tanuláshoz tervezett egyedi TPU-ban, ami számítási teljesítményben minden jelenlegi alternatívát lemos.
Először beszélt nyíltan közel egy éve felbukkant egyedi gyorsítójáról a Google. A kifejezetten a TensorFlow gépi tanulásos algoritmusok gyorsításához tervezett ASIC, azaz alkalmazás specifikus áramkör gyakorlatilag egy mátrixokkal dolgozó CISC processzornak tekinthető. Az egyedi áramkörnek hála jelentősen sikerült felgyorsítani a Google rendszerének tempóját, a cég mérése szerint a TPU 35-ször gyorsabb az Intel korábbi csúcs Xeonjánál, miközben fogyasztása alacsonyabb, tehát a kritikus fontosságú fogyasztás/teljesítmény mutató is számottevően jobb, mint CPU (vagy akár GPU) esetében.
A TPU-n (Tensor Processing Unit) lassan négy évvel ezelőtt kezdett el dolgozni a Google, a projekt egyik atyja pedig az a Norman Jouppi lett, aki korábban a MIPS processzorok vezető tervezője volt. A szakmai kiválóság elmondta, hogy a projekt indulásakor a FPGA lehetőségét is számításba vették, ugyanakkor ezt viszonylag hamar elvetette csapata, ugyanis a programozható kapumátrixok túl nagy áldozatot hoznak a teljesítmény oltárán, a chipek bár nagy rugalmasságot kínálnak, cserébe relatíve alacsony órajelre képesek és kicsi a tranzisztorbüdzsé, fogyasztás/teljesítmény mutatójuk pedig emiatt gyenge. Az ASIC a másik véglet, ezek az áramkörök bár számítási teljesítményben és hatékonyságban is kimagaslóak, cserébe korlátok közé helyezik fejlesztőket. Jouppi szerint igyekeztek megtartani valamennyi rugalmasságot, a TPU egy sztenderd CPU-hoz vagy GPU-hoz hasonlóan programozható, az a gépi tanulásos rendszerek és műveletek egész sorát képes gyorsítani.
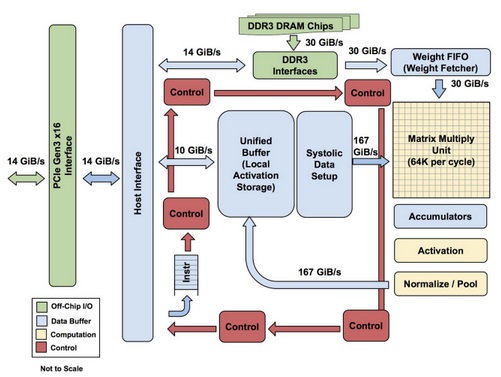
A TPU egy CISC (Complex Instruction Set Computer) megoldásnak tekinthető, ami vektorok vagy skalárok helyett mátrixokat használ primitívként. A CISC felépítés ellenére maga az áramkör nem tekinthető komplexnek, az sokkal inkább hasonlít egy digitális jelfeldolgozóra, amelynek speciális architektúrája bizonyos (lebegőpontos vagy egészszámos) műveletekre van kihegyezve. Jouppi ezt meg is erősítette, a szakember szerint a TPU a mátrixszorzó egységek tömkelege ellenére sokkal inkább hasonlít egy FPU-hoz, mint egy GPU-hoz.

Az egyedi processzor semmiféle programrészletet nem tárol, az egyszerűen végrehajtja a gazdaprocesszor felől beérkező műveletek. A CPU és a TPU közötti összeköttetésről nem beszélt a Google, ugyanakkor ennek szerepét valószínűleg egy egyszerű PCI Express busz látja el. A TPU kétféle memóriát tartalmaz: a processzor gyorsítótára mellett található DRAM is, utóbbiban többek között az aktuális gépi tanulásos modell paraméterei vannak, amelyek közvetlenül a mátrixszorzókba töltődnek be. A chip szerepét egy DDR3-as komponens tölti be, és bár Jouppi szerint a rétegzett, HBM memória egyértelműen javítana a rendszer hatékonyságán, ez a fajta memória továbbra sem jöhet számításba a magas költségek miatt.
Kimagasló hatékonyság
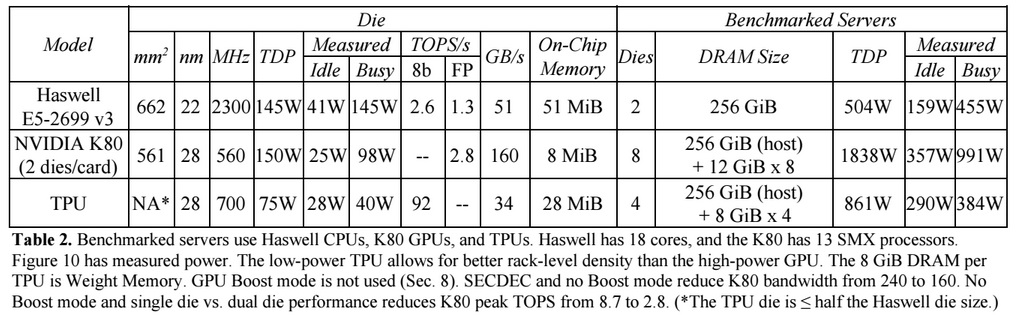
A Google saját, gépi tanulásra kihegyezett rendszerében található CPU-kkal (és GPU-kkal) vetette össze a TPU-t. Előbbi a csúcs Haswell-alapú Xeont, tehát a tizennyolcmagos E5-2699 v3-at takarja, amely a gépi tanulásos rendszerek által leginkább használt nyolcbites integer (INT8) műveletek esetében 2,6 TOPS (Tera Operations Per Second) tempóra képes, 51 GB/s memória-sávszélesség, 145 wattos TDP, valamint (256 GB memóriával) 455 wattos rendszerszintű fogyasztás mellett.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Ezzel szemben a TPU-val szerelt rendszer 92 TOPS-ra képes 34 GB/s memória-sávszélesség, illetve (ugyancsak 256 GB memóriával) 384 wattos rendszerszintű fogyasztás mellett, azaz a nagyjából 35-ször magasabb számítási teljesítményt alacsonyabb fogyasztás mellett biztosítja az egyedi gyorsítóval felvértezett rendszer.
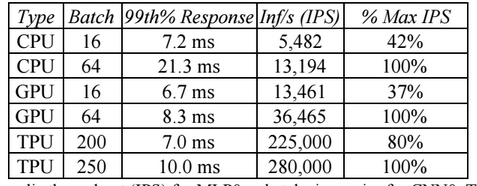
A gépi tanulásos rendszerekben a számítási teljesítmény mellett fontos a válaszidő is, amire szintén kitért a Google. Az említett Haswell-alapú Xeon körülbelül 7 (pontosan 7,2) milliszekundumon belül elméleti teljesítményének 42 százalékát, azaz 5482 IPS-t (Inferences Per Second) produkált, a maximális tempóra "felpörgéshez" a késleltetés majd háromszorosára, 21,3-ra nőtt. Ezzel szemben a TPU-val szerelt rendszer 7 milliszekundum alatt 225 000 IPS-t produkált, ami az elméleti teljesítmény 80 százaléka, a maximális tempóhoz pedig nem sokkal több időre, 10 milliszekundumra van szüksége, azaz minden szempontból kiemelkedő az egyedi ASIC produkciója.
Felmerülhet a kérdés, hogy a legújabb processzorokkal és grafikus gyorsítókkal milyen eredmények születnének. Az egy éve megjelent Broadwell-E azonos órajelen átlagban 5 százalékkal gyorsabb a Haswellnél, miközben 22 százalékkal több magot kínál, így Google által használt modellhez képes legfeljebb 25-30 százalék körüli lehetne az előrelépés. Érdekesebb kérdés a Pascal-alapú GPU-k tempója, a Google ugyanis még a meglehetősen koros, Kepler-alapú K80-at alkalmazza rendszerében.
A Pascal már rendelkezik a gépi tanulásos rendszerek hatékony gyorsításához szükséges INT8 támogatással, a GP102 kódnevű GPU-ra épülő kártyák 44 TOPS-ot produkálnak, ami a Google-féle processzor értékének szinte pont a fele, ráadásul ezek a Pascal-alapú megoldások csak tavaly nyár óta érhetőek el, a keresőóriás pedig már lassan két éve futtatja adatközpontjaiban saját fejlesztését.