Ezekből épülnek fel a Facebook adatközpontjai
Igazi meglepetésekkel bombázta az Open Compute Project héten zajló konferenciáján a Facebook a közönséget: a cég kidobja kétutas szervereit, helyette egyedi Xeonokra bízza az oldal kiszolgálását. Lássuk az izgalmas újdonságokat!
Rengeteget tanult a Facebook az adatközpontok hatékony működtetéséről az elmúlt néhány évben. Ez szűrhető le abból, hogy ugyan már hosszabb ideje saját tervezésű szervereket és tárolókat gyártat a cég saját adatközpontjai számára, a generációváltások még most is hoznak alaposan újragondolt hardvereket és látványosan előrelépő megoldásokat. Idén pedig nem is kis váltás jön, a cég a szerverektől a tárolókig és a GPU-s kiszolgálókig áttervezi az adatközponti gépeket.
A különböző szerepet ellátó szerverek között átívelő logika mára meglehetősen letisztult: néhány multifunkciós, hűtést és tápot tartalmazó kasztni, amelyekkel a belső modularitásnak köszönhetően sok szerep lefedhető. És ugyanilyen átjárhatóság a cél e belső modulok között is, például a webszerverek és a tárolószerverek ugyanazt a CPU-t, memóriát, alaplapot tartalmazó modult használják újra. Mindennek a skálázódásban van hatalmas hozadéka, a közös alkatrészekkel, kicserélhető, szabványos elemekkel a költségek is minimalizálhatóak, de a fenntartási költségek is nagyot esnek.
Mono Lake - egy foglalat mind felett
A Facebook webes felületét kiszolgáló szerverek esetében a tervezést vezérlő elv az energiahatékonyság volt: míg a korábbi években a fejlődést az egyre erősebb (és energiaéhesebb) CPU-k beépítése hozta, a cég mára beleütközött a fogyasztási korlátba, a rack szekrényenként nagyjából maximum 11 kilowattos fogyasztási limitbe. Az idei generációban tehát a feladat: ebből a keretből kihozni a maximális elérhető számítási kapacitást.

Az első döntés pedig a kétfoglalatos szerverek kidobása volt. A cég ugyanis úgy ítélte meg, hogy ez a felépítés már korlátozza a teljesítménysűrűséget, helyére érdemesebb egyfoglalatos, alacsony fogyasztású CPU köré épített szervereket tenni, amely jóval hatékonyabban látja el a webszerverekre eső feladatokat.
Ahhoz, hogy megértsük a Facebook problémáját, érdemes megnézni, mi is fut ezeken a gépeken. A webes felület kiszolgálását gigantikus, 10 ezer gépből álló szerverfürtök végzik, amelyeken HHVM, a Facebook saját fejlesztésű, Hack és PHP kódot futtató szoftvere fut. A lényeg, hogy az egyes szerverektől az infrastruktúra egyszerre vár alacsony válaszidőt és magas feldolgozási sebességet, ehhez mind a jó egyszálú teljesítmény, mind a jó párhuzamosság (sok mag) elengedhetetlen (ezért az Atom-alapú architektúrák nem jönnek szóba a hyperscale rendszerekben). De fura igényei vannak a memória-alrendszer oldalán is, a teljesítményt inkább a sávszélesség, és nem a RAM kapacitás fogja vissza.
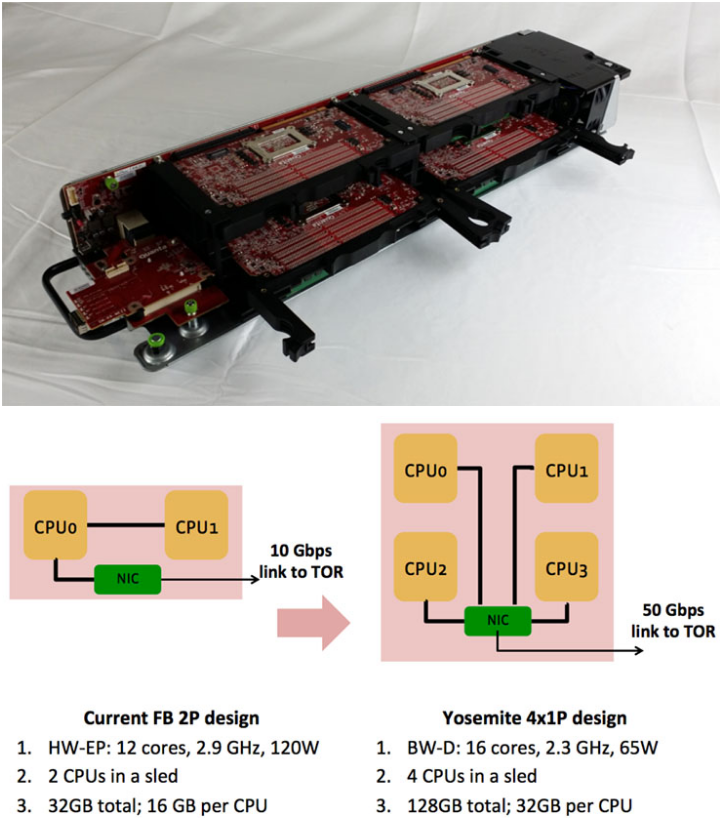
A különleges igényekkel az Intel is tisztában volt, a két cég kooperációjának eredményeképp jött létre a Broadwell-D processzorcsalád, amelynek érkeztét mi is meglepetésként kezeltük. Nem véletlenül, a Xeon D márkájú lapkák ugyanis sehogyan nem illeszkednek a hagyományos Xeonok közé, a chip fura kombinációja az asztali processzormagoknak, a noteszgépekben jellemző SoC-felépítésnek és a hagyományos szerveres képességeknek.
Ezek a jellemzők mind értelmet nyernek a Facebook igényeinek fényében: a komplex és nagy fogyasztású QPI interfészek (amelyek a Xeonok összekötéséért felelnek a több foglalatos rendszerekben) elhagyásával jelentősen csökkenthető a fogyasztás. Az SoC-felépítéssel egyszerűsíthető és miniatürizálható a lapkát fogadó alaplap, nem mellesleg a platformszintű fogyasztás is drámaian visszavágható, a támogatott DDR4-es memória pedig a sávszélességet emeli. Az eredmény pedig magáért beszél: a 16 magos, 65 wattos új lapkákkal a szekrényenként 60 CPU-s limit 120 CPU-ra tornázható fel, ahogy a 30 kétutas egység helyére 120 apró szerver kerül.
A lapkát fogadó szervermodul neve Mono Lake, egy miniatűr egység a standard Facebook-kiszolgáló. A hálózati vezérlőt is tartalmazó SoC mellé négy RAM-foglalat (32 gigabájt memória) és a bootolásra illetve naplózásra befogható helyi tároló (32+128 gigabájt) kerül. A következő egység a négy Mono Lake-et összefogó Yosemite sín, amely egy hálózati interfészt kínál a külvilág felé, ezzel a szerverek PCI Express csatornán kommunikálnak, a 2x25 gigabites sávszélességet a NIC dinamikusan osztja szét a négy Mono Lake között.
Big Basin - GPU-k, halomban
Az érdekesebb fejlesztés a Big Basin, amely a Facebook infrastruktúrájában a korábbi GPU-s egységet, a Big Sur nevűt váltja. A Big Sur a Facebook egyik első próbálkozása volt a GPU-gyorsított szerverek területén, a gépet a mesterséges intelligenciát alkalmazó tanulási algoritmusok gyorsítására építette a cég. A Big Basin már erősen épít az előddel szerzett tapasztalatokra, ezek között a legfontosabb a modularizáció: az új koncepcióban a CPU és a GPU már külön házban kap helyet - a Big Basin kizárólag grafikus egységeket tartalmaz.
A moduláris felépítés nagy előnye a Facebook szerint, hogy a külön fejlődési ciklussal rendelkező CPU-k és GPU-k külön-külön is cserélhetőek, így mondjuk GPU-s generációváltás esetén könnyebben bevethetőek az új chipekre épülő szerverek. Szintén pozitív hatás, hogy a két komponens aránya immár nem fix, vagyis a CPU-s és a GPU-s számítási teljesítmény tetszőlegesen vegyíthető - a Big Sur esetében 2 CPU és 8 GPU aránya fix volt.

A fentieknek megfelelően a Big Basin kompatibilis a Facebook következő generációs Tioga Pass hardveres architektúrájával is, illetve a GPU-s fiókok cserélhetőek, így nem csak a GPU-k, hanem az interconnect is frissíthető/cserélhető a teljes keret kidobása nélkül. A vezérlő node és a GPU-s node-ok közötti kapcsolatot kábeles PCI Express látja el, ebben a felállásban a Big Basin egyszerű "JBOG" (just a bunch of GPUs) módban működik. A leválasztás előnye, hogy a hűtési rendszer is hatékonyabb tud lenni. Az egymás mögé tett CPU-GPU tandemmel szemben a Big Basin nyolc GPU-ja jobb hűtést kap két sorban egymás mögött, némi eltolással.
Hogy a teljesítményről is essen szó: a Big Basinban nyolc Nvidia Tesla P100 dolgozik, amelyeket NVLink fabric drótoz 2x4-es egységekbe - pontosan úgy egyébként, ahogy az Nvidia saját DGX-1 szerverében is. A rendszer 10,6 teraFLOPS-os teljesítményt nyújt GPU-nként. Nem elhanyagolható előrelépés a Facebook szerint, hogy a memória 12 gigabájtról 16-ra emelkedett, ezzel párhuzamosan ugyanis a gépi tanulásos modellek mérete is 30 százalékkal növelhető - összességében éles feladatok alatt, a ResNet-50 képosztályozó algoritmussal tesztelve a teljesítmény duplázódott a Big Surhoz képest.
Bryce Canyon - merevlemezek halomban
Míg a GPU-s technológiákkal még viszonylag kevés tapasztalata van a Facebooknak, tárolók dolgában már roppant érett a cég. Az új Bryce Canyon már sok-sok évnyi tapasztalatra épül, az első, 2013-as Knox generáció óta a cég rengeteget tanult saját üzemeltetési igényeiről. Ennek eredménye az új tárolós node, amely kimondottan a hatékonyságra, teljesítményre és a sűrűségre helyezi a hangsúlyt.

Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Ennek megfelelően a közvetlen előd Open Vaulthoz képest a 4U magas Bryce Canyon 20 százalékkal több merevlemezt képes fogadni, de ezzel párhuzamosan erősebb processzorokat és több memóriát is tartalmaz, javított hatékonyságú hűtéssel együtt. A Big Basinhoz hasonlóan a tároló is fiókos kialakítású, így a keretben lévő egységek is könnyen cserélhetőek, így az egység a jövőben is tud idomulni a Facebook igényeihez - például erősebb CPU-kkal vagy még több memória beépítésével.
Jelenlegi formájában a Bryce Canyon 72 darab 3,5 hüvelykes HDD-t fogad, ezek lehetnek 12 gigabites csatlakozót használó SAS modellek vagy 6 gigabites SATA meghajtók. A tároló viselkedhet egyetlen 72 meghajtós tárolóként is, de szükség esetén konfigurálható két, redundás, független tápellátással rendelkező 36 meghajtós szerverként is. Sőt, ugyanaz a kasztni lehet "buta", 36/72 meghajtós JBOD is, ebben az esetben a vezérlő szerepét egy közeli szerver látja el. A tárolószerver agya egyébként a Facebook frontend szervereiben is használt Mono Lake modul - ez önmagában négyszeres számítási kapacitást nyújt az előző generációhoz képest.
A tárolóhoz persze tartozik egy fejlett I/O modul, amely a fent említett SAS és SATA csatlakozókat nyújtja, a többi szerver felé pedig 25/50 gigabites hálózati interfészt kínál. Az I/O modulból több változat létezik, ez teszi lehetővé hogy a tárolót speciális feladatokhoz (JBOD, Hadoop, cold storage) szabják az üzemeltetők.
Így a tároló kihegyezhető teljesítményre, 2x36 meghajtóra osztva, dupla Mono Lake modullal és két M.2 formátumú SSD-vel (gyorsítótár szerepében). Kiegyensúlyozottabb konfigurációban egyetlen Mono Lake és 72 meghajtó dolgozik, a kapacitásra kihegyezett verzió pedig egy storage head mögé bekötött több JBOD-ként konfigurált Bryce Canyont jelent.
Újratervezni az adatközpontot
A fent említett három hardverelem mellett a Facebook még rengeteg további részegységet bejelentett, a 100 gigabites optikai csatlakozótól a szerverek felügyeletét ellátó új generációs szoftverekig. A jó hír, hogy ahogy az előző terveket, az újakat is megosztja a cég az Open Compute Project keretében, így a gyártáshoz szükséges összes tervrajz letölthető és változatlanul (vagy módosítva) gyártásba küldhető. A kezdeményezéstől a résztvevők azt várják, hogy hosszabb távon létrejön egy nyitott hardveres ökoszisztéma, amely minden, sok százezer szervert üzemeltető cég számára csökkenti majd az adatközpont-építési költségeket.