Tervezési szempontok egy eseményvezérelt szoftverarchitektúrában
Az eseményvezérelt és event streaming technológiák alapjainak áttekintését követően körüljárunk néhány szoftvertervezési szempontot, melyekre egy eseményalapú elosztott rendszer megvalósítása során ügyelnünk kell.
Korábbi cikkünkben röviden áttekintettük az eseményvezérelt architektúra (EDA) és az event streaming technológia alapjait, és ennek megvalósításaként az Apache Kafka és IBM Event Streams platformokat. Cikkünk folytatásában körüljárunk néhány szoftvertervezési szempontot, melyekre egy eseményalapú elosztott rendszer megvalósítása során ügyelnünk kell.
Eseménymodellezés
Általánosan fogalmazva: egy adott eseménnyel a rendszer állapotában történő valamilyen változás jelzünk. De mi kerüljön bele az egyes eseményeket leíró adatcsomagba?
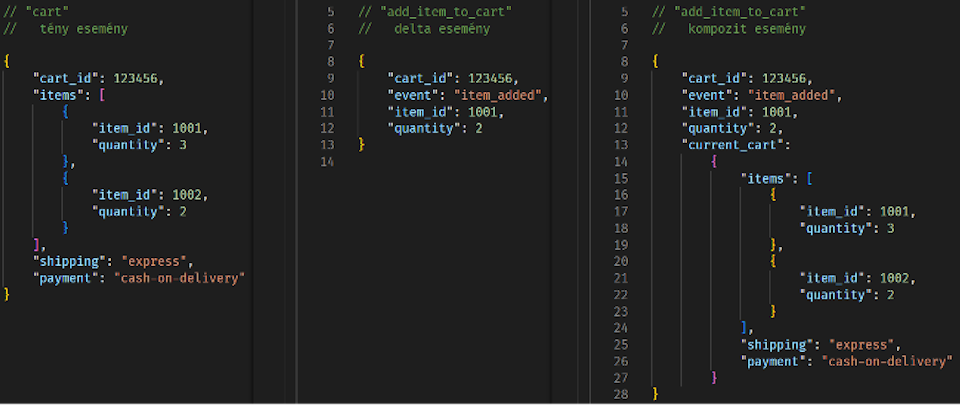
Tény és Delta típusú események
„Tény” típusú esemény esetén az adatcsomag az egész aktuális állapot tartalmazza, mintegy pillanatfelvételként. Például egy webshop alkalmazásban egy adott ügymenet során a vásárlói kosár aktuális teljes tartalmát.
„Delta” típusú eseménynél az adatcsomag csak a változás leírását tartalmazza. A webshopos példánál maradva: ha az esemény az, hogy a kosár tartalma változott, akkor csak az éppen hozzáadott tétel jelenik meg az esemény adatmezői között.
Mindkét megközelítésnek vannak előnyei és hátrányai:
A tény típusú eseménymodellnél az adott eseményfolyamra feliratkozó szoftverkomponens nagyon egyszerűen reprodukálhatja, hogy az esemény forrása milyen állapotban volt az esemény küldésének időpontjában. Összetett alkalmazásnál viszont a teljes állapotleírás túl nagy adatmennyiség küldését igényelheti. Ráadásul, ha az eseményt fogyasztó szolgáltatás arra is kíváncsi, hogy pontosan mi változott, akkor ahhoz el kell tárolnia az előző állapotot és különbséget kell kalkulálnia.
A delta típusú eseménymodellnél ezzel szemben a változás azonosítása egyszerű, hiszen az esemény valójában pontosan ezt modellezi. Viszont, ha a fogadó oldalon szükség van a küldő teljes állapotára, akkor ahhoz az elemi változások összeadódó hatását fogadó oldalon is le kell modellezni.
A fenti két alaptípus ötvözhető is, például egy olyan kompozit eseményleíró modellel, mely az előző és az új állapotot egyaránt tartalmazza. Alternatív megoldás lehet, ha az adat az új állapotot és az ehhez vezető legutolsó változást is leírja.
Normalizált és denormalizált eseménymodellek
Adatbázis tervezésnél megszokhattuk, hogy a relációs adatbázisok tipikusan normalizált táblákat tartalmaznak, csökkentve az adatredundanciát. Például egy vásárlói kosarat leíró adatbázis rekord a kosárban lévő árucikkeknek csak az azonosítóját tartalmazza idegen kulcsként, míg az árucikkek részletes adatai (megnevezés, gyártó, súly, stb.) egy másik, a cikktörzset tartalmazó táblában van. Egy SQL lekérdezésben persze egy megfelelő JOIN klauzulával pontosan azokhoz az adatokhoz juthatunk hozzá, amire szükségünk van, az adatbázis motor hatékonyan elvégzi mindazt, ami ehhez szükséges.
Ha az eseményeink egy az egyben megfelelnének az eseményforrásnál lévő adattáblák szerkezetének, akkor az eseményfogyasztó oldalon ez többletmunkát eredményezhet, mert az idegen kulcsok feloldását ott is minden egyes eseménynél el kellene végezni. Ráadásul így az esemény forrását jelentő és az azt fogyasztó microservice-ek között egy túlságosan szoros logikai kapcsolódást hoztunk létre: ha bármiben változik a forrás belső adatmodellje, akkor minden egyes fogyasztó szolgáltatás kódját is módosítani kell.
Ezért az eseménymodellezésnél érdemes némi denormalizálást, egyfajta „adatgazdagítást” alkalmazni a nyers adatbázis táblák struktúrájához képest. Így az esemény tartalmazza mindazon adatokat, ami a fogyasztásához szükséges, és a külső eseménymodell elválik a belső adatmodelltől.


A részletes tervezés során még számos technikai szempont felmerül: Pontosan mely adatokat denormalizáljuk? Elvégezhető-e egyáltalán a forrás oldalon a denormalizálás, vagy erre külön köztes microservice-t készítsünk, ami az esemény(ek)ből egy új, módosított adattartamú eseményfolyamot állít elő? Ha különböző eseményfogyasztóknak hasonló, de nem pontosan ugyanazon adatokra van szüksége, akkor tervezzünk mindenki számára külön eseménymodellt, vagy öntsünk be minden adatot ugyanabba az eseménytípusba és majd a fogyasztó kiválogatja az őt érdeklő mezőket? Hogyan biztosítsuk a tranzakcionális működést?
Egyszerű vagy összetett eseményfolyamatok
Az event streaming platformok, mint az Apache Kafka biztosítja az eseményeket továbbító infrastruktúrát. De hogyan rendeljük az egyes eseménytípusokat az eseményfolyamokhoz, stream-ekhez?
A legegyszerűbb esetben minden eseménytípushoz önálló eseményfolyam (pl. Kafka topic) tartozik. Például a webshopos kosár esetén külön (delta típusú) esemény az „elem hozzáadva”, az „elem törölve”, vagy a „promóciós kód hozzáadva”. Az alkalmazás azon részei, amelyeknek a kosárállapot változására reagálniuk kell, mindegyik elemi delta folyamra feliratkoznak. Azonban, ha az események sorrendje fontos, akkor külön gondoskodnunk kell az helyes sorrendben történő feldolgozásról, például egy időbélyeg mező alkalmazásával, de ez elosztott környezetben, különböző források esetén egyáltalán nem triviális.
A másik megoldás, ha egyetlen eseményfolyamban többféle delta esemény is megjelenik. Ekkor a helyes sorrendiség fenntartása magától értetődik, de cserébe bonyolultabbá válik az adatmodell és megint szorosabbá válik a csatolás az esemény forrása és fogyasztói között.

Tény típusú eseményeknél tipikusan célszerű a teljes állapotot egyetlen eseményfolyamban, egyetlen eseményként kezelni.
Folyamatos vagy diszkrét eseményfolyamok
A webshop vásárlói kosár példában jól meghatározható, hogy mikor változik az és mikor szükséges emiatt eseményt generálni állapot (pl. a felhasználó a felületen kattintott). Az üzleti folyamatunk modellje gyakran egy állapotgép, mely erős kapcsolatban van a megtervezett eseményfolyam modelljével. Tipikusan eseménynek nem szabad elvesznie el és az esetleges duplikáció is problémás.
Egy eltérő használati minta, amikoregymástól függetlenek az események, például egy szenzor által mért értékek idősora. Ezt tipikusan egyszerű eseménytípus jellemzi és a fogyasztók nem érzékenyek egy-egy esemény elvesztésére vagy akár duplikációjára.
További tervezési szempontok és az „event governance”
Egy komplex nagyvállalati környezetben számos alkalmazás vagy microservice együttműködése szükséges az üzleti működés zökkenőmentes fenntartásához. Az eseményorientált architektúra alkalmazásának elterjedésével az eseménytípusok és eseményfolyamok száma is átléphet egy olyan határt, amikor azok fenntartható kezelése már egyre nehezebbé válhat, különösen egy gyorsan változó, agilis szoftverfejlesztési környezetben.
Ekkor előtérbe kerül az egységes kezelés és a belső iránymutatások, az ún. governance kérdése. Szükséges az alapok megfelelő lerakása, miközben az egyes fejlesztési projektek továbbra is megkapják azt a döntési autonómiát, ami a hatékonyságuk fenntartásához szükséges.
Ilyen közös nevező lehet az egyes eseménytípusok sémákkal, szabványos leíró nyelvekkel történő definiálása (pl. JSON Schema, Apache Avro, Protobuf) és a sémák vállalati szintű sématárban (event schema registry) történő tárolása. Ez nem csak dokumentációs vélt szolgál, hanem egyes event streaming platformok képesek a beküldött események séma szerinti automatikus validálására is.
Szintén fontos a névkonvenciók rögzítése, legyen szó az eseményekben reprezentált üzleti objektumokról vagy maguknak az eseményfolyamok (Kafka topic-ok) nevének struktúrájáról. Feleslegesen terheli a fejlesztőket és elkerülhető hibákra ad lehetőséget, amikor ugyanazt az adat-elemet különböző eseménytípusokban teljesen máshogy nevezzük.
Bár az egyes eseménytípusokhoz eltérő adatmodell tartozik, lehetnek olyan metaadatok, amik minden eseménynél felmerülhetnek, mint például a publikálás időbélyege, vagy az eseményhez rendelt egyedi azonosító. Ezeket érdemes egy külön fejléc szekcióban csatolni az üzenethez, a fejléc előírt struktúráját pedig szintén a belső fejlesztői útmutatónkban vagy a governance dokumentumban rögzíthetjük.
Zárszó
Cikkünkben terjedelmi okokból épp csak érintettünk az event streaming technológia használata során felmerülő néhány eseménymodellezési szempontot. Az Intalion Rendszerintegrátor Kft. szakértői tevékenységgel támogatja nagy- és középvállalati ügyfeleit korszerű szoftvertervezési feladataikban. De nem állunk meg a tervezésnél: egyedi szoftverfejlesztéssel meg is valósítjuk az esemény-vezérelt architektúrájú alkalmazást, infrastruktúra oldalon pedig bevezetjük és támogatjuk az event streaming alaprendszert, legyen szó az Apache Kafka-ról, vagy annak nagytestvéréről, az IBM Event Automation platformról.
[Az Intalion Kft. IBM Gold Partner megbízásából, az Arrow ECS Kft támogatásával készített, fizetett anyag.]