Siralmas a helyzet az MI-modellek átláthatósága terén
A legnépszerűbb MI-modellek legjobb pontszámai is gyengének mondhatók a stanfordi kutatók új jelentése szerint, a fejlesztőknek sokkal több információt kellene szolgáltatniuk.
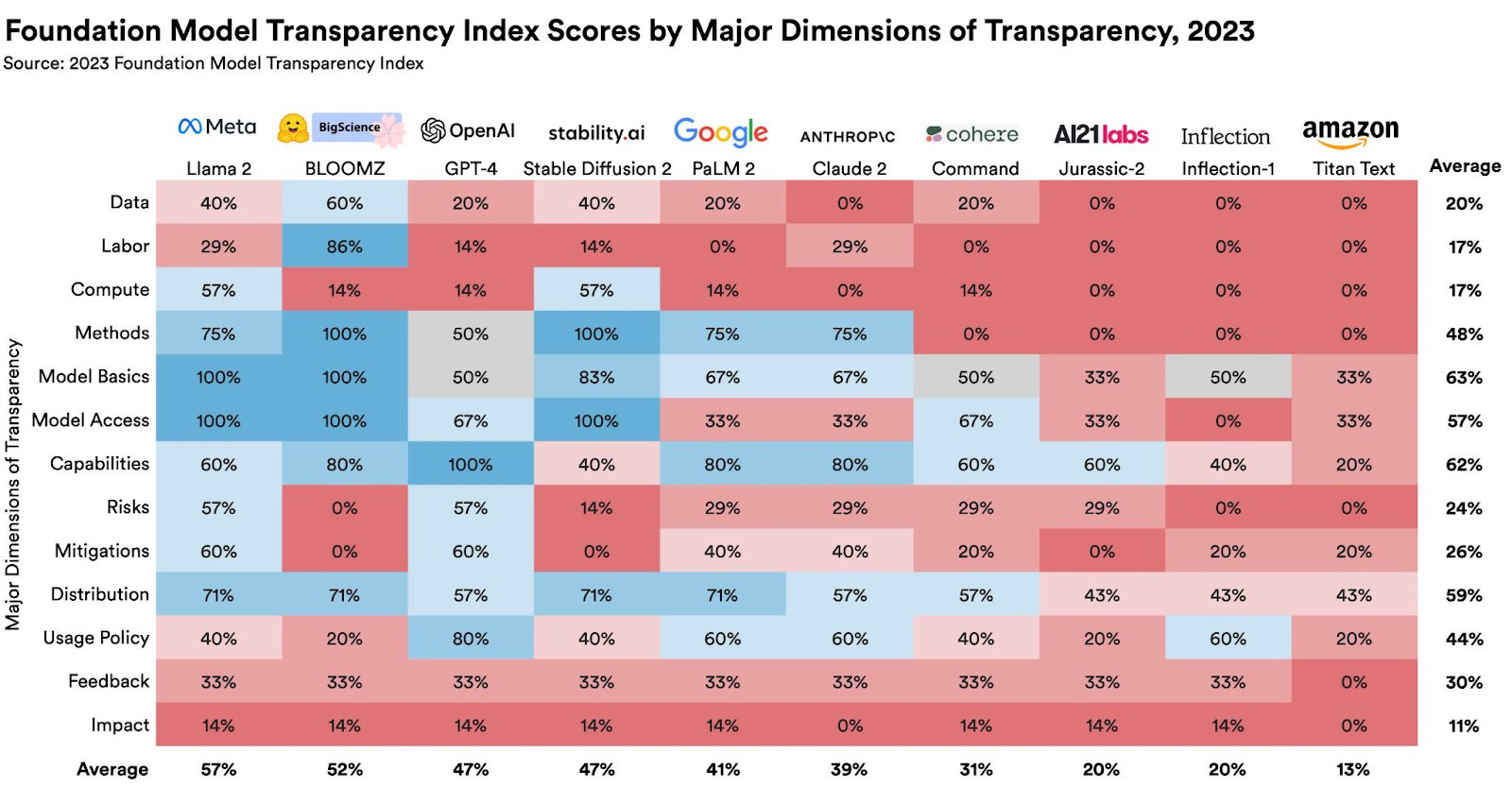
A Stanford Egyetem kutatói szerdán publikálták friss, egyben első jelentésüket a napjainkban legelterjedtebbnek számító fejlett mesterségesintelligencia-modellek átláthatóságáról, ami egyelőre lesújtó helyzetet mutat. Az akadémikusok szerint átláthatóságra azért is van szükség, hogy a cégek reálisan tudják megítélni, építhetnek-e biztonságosan alkalmazásokat a kereskedelmi modellekre, ugyanez vonatkozik a kutatókra és egyes döntéshozókra, illetve a fogyasztókra, akik támpontot kaphatnak ahhoz, hogy megértsék a modellek korlátait és jogorvoslatot kérhessenek a felhasználás során keletkezett esetleges károkért.
A "The Foundation Model Transparency Index" című jelentés az OpenAI, a Google, a Meta, az Anthropic és a piac többi meghatározója szereplője által fejlesztett modelleket vizsgálja, többek közt a modellek képzéséhez felhasznált adatokra és a cégek által foglalkoztatott munkaerőre vonatkozóan is átláthatóságot kérve a fejlesztőktől. A szakemberek a tíz legnépszerűbb modellt 100 különböző mutató alapján vizsgálták, beleértve a képzési adatokat és a fejlesztés során használt számítási kapacitást, a felhasználási módokat, és hatásokat vizsgálva.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A jelentésben szereplő modellek összesített pontszámai siralmas képet festenek: a legjobb értékeléssel rendelkező Llama 2 nyelvi modell 54 pontot kapott az összesen 100-ból, a többi eredmény ennél csak gyengébb, az Amazon Titan modellje ráadásul a legalacsonyabb, 12-es pontszámot kapta meg. A legelterjedtebbnek számító GPT-4-nek pedig mindössze 48 pontot sikerült elérnie, aminek annak fényében aggasztó, hogy a többek közt a ChatGPT-t is hajtó modellről van szó.
Dr. Percy Liang docens szerint az elmúlt pár év jól mutatja, hogy míg a modellek és az MI-alkalmazások képességei rendkívül gyors ütemben fejlődnek, addig az átláthatóság romlik, ami főleg a nagy tech cégek közti versenynyomás eredménye. Liang szerint a jövőben érdemes lehet megfontolni a nyílt forráskódú MI-modellek lehetséges előnyeit, felhozva a nyílt kezdeményezések pozitív eredményeinek példájaként például a Wikipédiát és a Linuxot.
A jelentés szerzői remélik, hogy az eredmények nemcsak a vállalatokat ösztönözhetik átláthatóságuk javítására, hanem erőforrásként is szolgálhat a kormányok számára, amelyek éppen azzal küzdenek, miként szabályozhatnák ezt a gyorsan fejlődő területet. Ilyen téren jelenleg az Európai Unió jár élen a közelgő AI Act-tel, ami többek közt az átláthatóságot szeretné garantálni, bár ezt több cég is ellenzi a technikai nehézségekre hivatkozva.