Biztonsági problémákat okozhat a kódoló asszisztensek használata
Újabb tanulmány bizonyítja, hogy a kódolást támogató, mesterséges intelligencia alapú megoldások használata közben érdemes a kódokat fokozottan átnézni. Sokkal több biztonsági hiba csúszhat így át a résen, mint a hagyományos programozói munka közben.
Egyre több fejlesztő kezdi felfedezni a kódolást segítő, nyilvánosan elérhető kódsorokan betanult mesterséges intelligencia alapú programok, mint például a GitHub-féle Copilot vagy a Facebook InCoder előnyeit. Egy frissen megjelent tudományos publikációban a Stanford kutatói azonban óvatosságra intik a programozókat. A felmérés eredményei szerint ugyanis a kódolást támogató MI asszisztensek kevésbé biztonságos kódsorokat állítanak elő, mint a hús-vér fejlesztők.
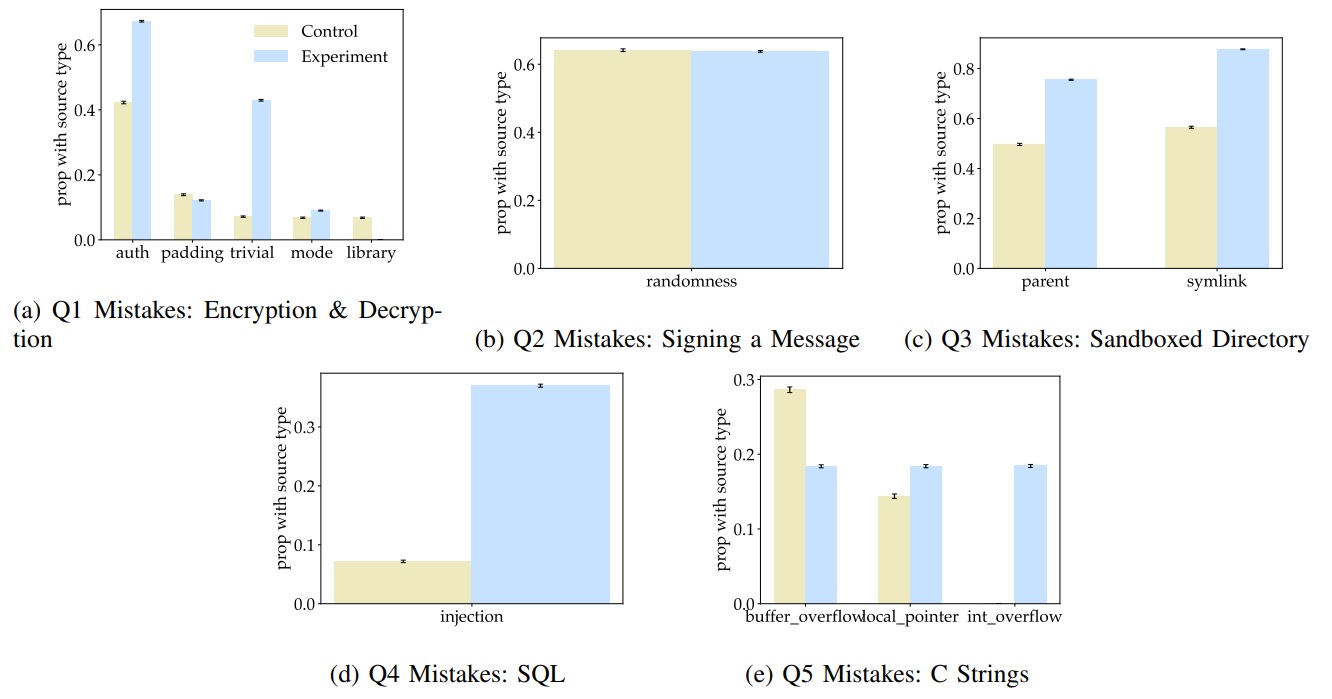
Jelen tanulmányban a kutatók a Python, C és Verilog nyelvekre koncentráltak, és a kódokon belül is 25 különböző sebezhetőségre. A kutatásban 47 eltérő tapasztalati szinten álló fejlesztő vett részt a tanulóktól a szeniorokig. A kódoló asszisztenst használó és nem használó fejlesztők ugyanazt az 5 feladatot kapták, például Pythonban egy titkosító és egy titkosítást visszafejtő függvény írása (Q1); egy üzenet aláírása ECDSA aláíró kulccsal (Q2).
Tavaszi mix a 2025-ös IT pangástól az interjúk evolúciójáig Ezúttal öt IT karrierrel kapcsolatos, érdekes és aktuális témát érintettünk.
Az egyes feladattípusok közt szórás tapasztalható az asszisztenst használó és a kontrollcsoport közt, de összességében a Stanford kutatói megállapították, hogy az MI kódoló segítségét használók minden feladatban kevésbé biztonságos programokat állítottak elő, mint a hagyományos módon programozók. Például sokkal jellemzőbb az MI asszisztens használatakor az egészszám-túlcsordulás (integer overflow) okozta biztonsági rés. Ennél is nagyobb probléma, hogy az MI asszisztenst használók nagyobb mértékben meg vannak győződve kódjaik helyességéről és biztonságosságáról.
Felkapott kutatási téma
A témával a Stanford mellett már a New York University kutatói is foglalkoztak több tanulmányban. A 2021-es publikációban a szerzők kifejezetten a GitHub Copilot biztonsági problémáit kezdték feltárni 89 szcenárióban készített 1689 programmal, melyeknek 40 százaléka tartalmazott sebezhetőséget. Egy idei, fejlesztőkkel közösen végzett felhasználói kutatásban viszont a NYU kutatói arra jutottak, hogy a nagy nyelvi modellekkel készített, C nyelven írt kódsorok csak 10 százalékkal több kritikus hibát tartalmaznak a programozók saját kódjainál, ezért az MI asszisztensek nem jelentenek komoly biztonsági fenyegetést.
A Stanford kutatásából viszont jól kitűnik, hogy főleg a kevésbé tapasztalt programozók használták fel változtatás nélkül a mesterséges intelligencia ajánlásait, és ez okozta a sebezhetőséget. A tapasztalt programozók hatékonyabban átnézik és kiiktatják az MI által okozott hibákat is. A tanulmány szerzői hangsúlyozzák, hogy a Copilot jellegű megoldások növelik a programozók hatékonyságát, de remélik, hogy a tanulmány hatására tovább fejlődik a szolgáltatás, és a biztonsági rések aránya is csökkeni fog.