Túl kevés könyvtárhasználó vesz igénybe tudományos adatbázisokat
Sokaknak a Google a legnagyobb barátja, pedig a könyvtárosok szerint legalább az egyetemi hallgatóknak és oktatóknak jobban kellene ismernie a tudományos adatbázisokat. Egyelőre még főleg az alapszintű digitális felhasználóképzésnél tartunk, miközben vannak, akik szerint már a mesterséges intelligencia lehetőségeit kellene szélesebb körben bemutatni.
A mesterséges intelligencia használata, a digitális íráskészség fejlesztése és az adatbázishasználat népszerűsítése is témái voltak többek közt a Magyar Könyvtárosok Egyesülete, Kaposváron megrendezett vándorgyűlésének. Minden évben ez az a négy napos fórum, amelyen az ország különböző pontjairól nagyjából hatszáz könyvtáros gyűlik össze, és vitatja meg a munkakört aktuálisan érintő kérdéseket. A témák között rendszerint megjelenik az informatikahasználat is, hiszen a szakmát is már több mint egy évtizede informatikus-könyvtárosnak hívják az információhordozó eszközök változása miatt.
Keresés a Google-on túl
Az informatikus-könyvtárosok tudnak többek közt segíteni a digitális íráskészség fejlesztésében, amelynek az egyetemeken is bőven van tere a tapasztalatok szerint. A vándorgyűlésen az ELTE és a MATE könyvtárosai is beszámoltak róla, hogy az intézményben a hallgatói igényfelmérést követően milyen képzéseket indítottak, amelyek közt mindkét esetben megjelennek például az internetes keresési technikák, a különböző tudományos adatbázisok és repozitóriumok használata, a hivatkozáskezelés (pl. Zotero) vagy a források értékelése.
A tudományos adatbázisok használatának alacsony mértékét a könyvtárvezetők különösen problémásnak tartják. A PTE Műszaki és Informatikai Kar könyvtárvezetője, Csehné Kardos Zita interjús elemzése szerint a PhD-hallgatók többsége elsősorban a Google-t választja publikációk keresésére a könyvtáron keresztül elérhető adatbázisok, mint például a Web of Science, a SpringerLink vagy a Scopus helyett.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
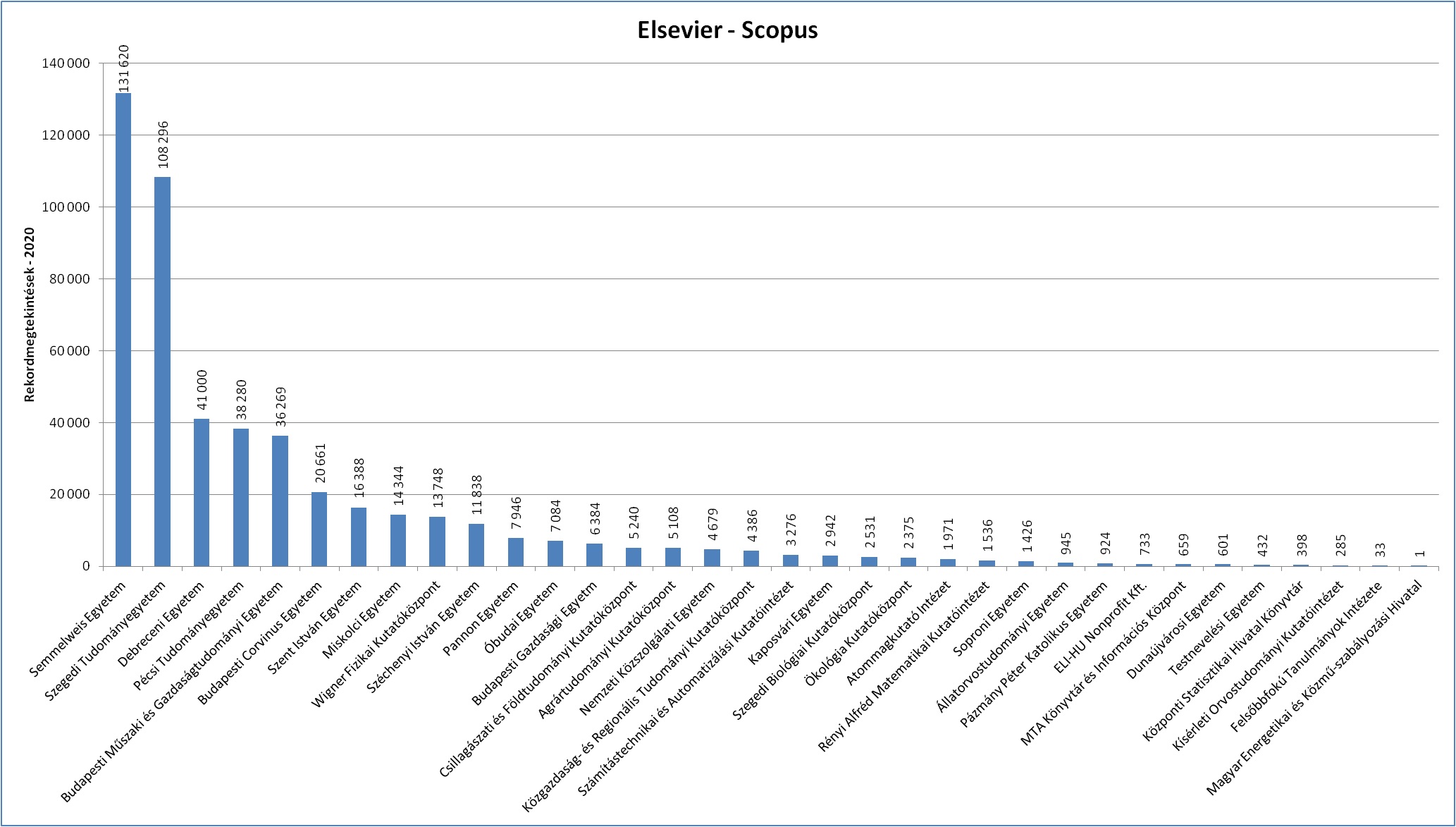
A hallgatók adatbázishasználati ismereteinek hiányosságánál nagyobb problémát jelent, hogy sokszor az oktatók sem látják be eléggé a tudományos adatbázishasználat fontosságát - tette hozzá Kötél Emőke, a Neumann János Egyetem könyvtárigazgatója. Ennek ellenkezőjét jól mutatta, mikor az egyik kar oktatói egységesen az Akadémiai Kiadó Magyar Referenciamű Szolgáltatásán (MeRSZ) keresztül elérhető folyóiratokba kezdtek publikálni, és a cikkeket ilyen formában adták fel kötelező olvasmányként. Így a MeRSZ adatbázisból 2019-ben az egyetem felhasználói több mint 41 ezer tételt töltöttek le, ami az összes adatbázisletöltés 92 százalékának felelt meg az intézményben elérhető 14 adatbázis közül.
Könyvtárakba is kopogtat az MI
A mesterséges intelligencia részterületei több kapcsolódási pontot is nyújtanak az informatikus-könyvtárosok számára, amelyről Winkler Bea, az ÁTE Hutÿra Ferenc Könyvtár, Levéltár és Múzeum könyvtárvezetője beszélt részletesebben. A háttérmunkát például a természetes nyelvi feldolgozás eszközei segíthetik az olvasótermi polcpakolásban, de léteznek egyébként már teljesen automatizált robotraktárak is (hasonlóan a gyógyszertári robotokhoz).
Az olvasói kapcsolattartást kézenfekvő módon chatbotok, digitális asszisztensek, a gépi tanulásra építő könyvajánlók támogatják. Utóbbi kategóriában egy következő lépésként jelenhetnének meg a recepciós robotok, de ahogy az előadó is hozzátette, például Pepper 14 ezer dolláros összköltsége (alapdíjjal és kötelező havidíjakkal) nem fér bele egy könyvtár költségvetésébe. Több egyéb megoldás viszont már jelenleg is elérhető a könyvtárakban - jellemzően a chatbotok -, annak ellenére, hogy nem minden felhasználó ismeri fel az MI-t használat közben, mert nincsenek tisztában annak pontos jelentésével. Pedig a jövőben várhatóan egyre több, mesterséges intelligenciára épülő eszköz lesz elérhető a könyvtárakban is.