Egyre nehezebb lesz a kódolási plágium felismerése
Elkezdhetnek aggódni az egyetemi oktatók és az informatikusok fejvadászai, mert már a programozási feladatok sem feltétlen bizonyítják a jelölt tudását. Az egyszerűbb kérdésekre algoritmikusan generálható a plágiumszűrőket átverő kód.
Egy újonnan megjelent tanulmány bemutatja, hogy a neurális háló alapú nyelvi modellek már olyan hatékonyan tudnak belépő szintű programozói feladatokat elvégezni, hogy azt a kódolási plágium felismerésére szakosodott eszközök sem tudják kiszűrni. A publikáció szerzői, Stella Biderma és Edward Raff, mindketten a Booz Allen Hamilton IT tanácsadócég szakértői és az EleutherAI nyílt forrású mesterséges intelligencia projekt kutatói, jelenlegi kísérletükben a GPT-J nyelvi modellt használták a hipotézisüket alátámasztó kód előállításához. A modellt egyáltalán nem tanították be a feladatok megoldására, és példát sem adtak a munka elvégzéséhez.
Maga a programkódok lemásolása régóta egészen általános problémának számít, amelynek meg is vannak a maga eszközei. A kutatásban is használt, nyílt forrású Measure of Software Similarity (röviden MOSS) már 1994 óta segíti a szakértőket a másolt vagy valamilyen szempontból hasonlónak tűnő kódok felismerésében. A mesterséges intelligencia alapú megoldások, vagyis jelen esetben neurális háló alapú nyelvi modell viszont egyre fejlettebbé válnak, és a felhasználásukkal létrehozott kódok plágiumvizsgálata még egy egészen új területet jelent.
A kutatók hét feladatot adtak, amely egy bevezetés a programozásba órán szerepelhetett volna, és a feladatokhoz tanársegédek által Java nyelven írt megoldásváltozatokat csatoltak. Minden feladathoz 15 nem plagizált és 49-54 közötti plagizált megoldás változat készült, utóbbi 1-6 skálán pontozva a plágium összetettsége szerint. A feladatok közt szerepelt például egy személy BMI értékeinek kiszámítása súly és magasság alapján, mérföld-kilométer átváltó táblázat készítése, 10 egész szám befogadása és megjelenítése fordított sorrendben.
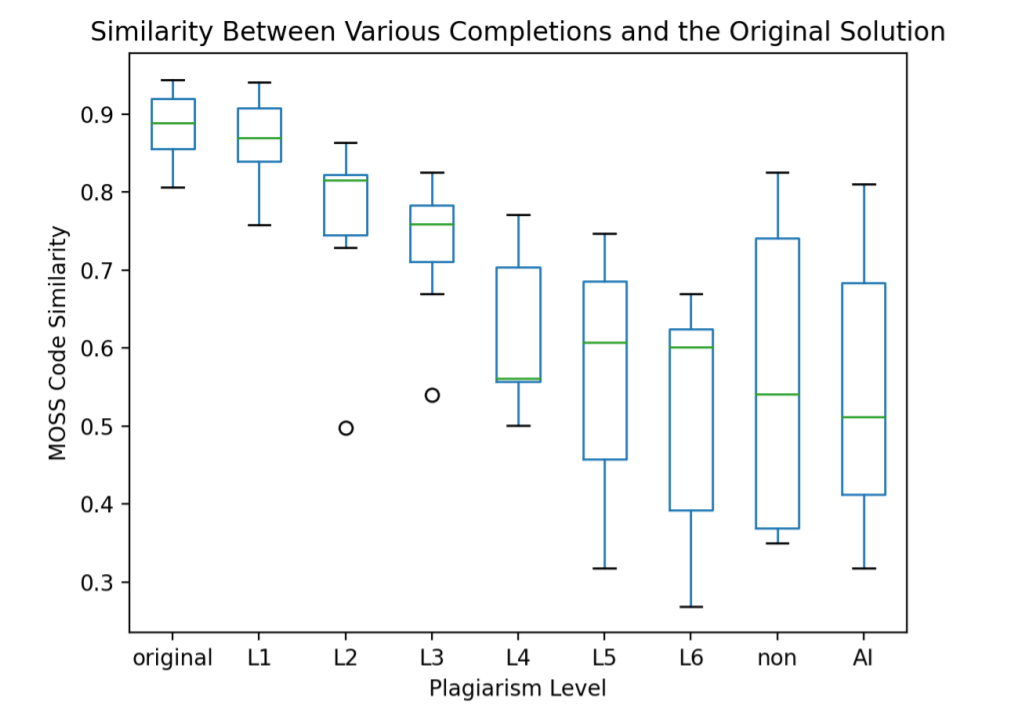
Forrás: Stella Biderma és Edward Raff tanulmánya
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A kutatók megállapítása szerint a GPT-J által előállított kód olyan változatos felépítéssel készült, hogy mind a hét feladatban átcsúszott a MOSS szűrőjén, a nem-plágium megoldásokhoz hasonló értékekkel. Mindössze minimális változtatásokra volt szükség, hogy a "syntax error" jellegű egyszerű hibákat javítsák. Minderre a szerzők szerint egy programozói tudás nélküli személy is képes lett volna, hogy elindítsa a kód generálást, majd Google segítségével javítsa a hibakódokat.
HOL OKOZ PROBLÉMÁT?
A tanulmány szerzői elsősorban az egyetemek oktatóinak figyelmét igyekeztek felhívni a várhatóan egyre nagyobb nehézséget jelentő problémára. A kutatók szerint már nem elég a MOSS alapú eszközökre támaszkodni a plágiumok kiszűrésében. Azonban a GPT-J vagy más modellek még nem olyan fejlettek, hogy egy eszközzel minden egyetemi feladatot meg lehessen oldani, és így diplomához jutni.
Emellett viszont az informatikusokat felvételiztetők figyelmét is érdemes felhívni a minőségi jelöltek kiszűrését nehezítő körülményre. Bár a következő interjúkörre feladott kérdéseket más formában is meg lehet kerülni, például ismerősök segítségével. A kiválasztást végző szakemberek pedig jelenleg sem egyszerűen csak a kódok átnézéséből vonnak le következtetéseket. Egyrészt a népszerű, élő kódolásos interjúk közvetlen bizonyítékot mutatnak a fejlesztő készségeiről. Másrészt pedig a jelölteknek el is kell tudni magyarázni, miért használták az adott megoldást, ami rávilágíthat az esetleges csalásra.
Egyelőre azonban nem kell félni az interjúkra tömegesen algoritmikusan plagizált kódokkal jelentkező jelöltektől a VentureBeatnek nyilatkozó szakember szerint, mert ha már itt tartanánk, akkor fejlesztőkre sem lenne szükség. Jelenleg viszont a modellek csak egyszerűbb feladatok megoldására képesek a tanulmány szerint. A kutatók a továbbiakban a MOSS-tól eltérő eszközökkel is próbálkoznak majd a plágium felismerésében, és összetettebb feladatokat is adnak majd a GPT-J modellnek.