Itt vannak az ARM vadiúj processzormagjai
Három új processzormag-dizájnról rántotta le a leplet az ARM: a tavaly bemutatott Cortex-X1 és az A78 egyaránt utódot kapott, sok év után pedig a Cortex-A55-öt is leváltja a tervezőcég.
A processzortervező vállalat a frissen bemutatott Cortex-X2 maggal a lehető legnagyobb számítási teljesítmény elérésére fókuszál, disszipációt és méretet nem kímélve. Az A78-at váltó Cortex-A710 az arany középutat követi, vagyis viszonylag alacsony fogyasztás mellett jó teljesítményt igyekszik nyújtani a friss maggal. Végül, de nem utolsó sorban a Cortex-A510, amely a hatékonyságra, ezzel pedig a minél hosszabb akkus üzemidőre fókuszál.

Mindhárom újdonság a közelmúltban bejelentett Armv9 architektúrára épít. Ez a 64 bites végrehajtást hozza még inkább előtérbe, 32 bites (AArch32) kódok futtatására ugyanis már nem képes az Armv9. A tervezőcég azonban egyes piacok (elsősorban Kína) igényeit szem előtt tartva a Cortex-A710-nél még megoldotta a 32 bites alkalmazások futtatásának lehetőségét.
X2: TELJESÍTMÉNY MINDENEK FELETT
Ahogy az előd Cortex-X1 esetében, úgy az X2-nél is a teljesítmény maximalizálását tűzte ki első számú célul az ARM. Nem csoda, hogy az kigyúrt magot elsősorban nagyobb képátlójú eszközökbe, táblagépekbe és notebookokba szánja az ARM. A tervezőcég partnereivel (Qualcomm, Samsung) továbbra sem tette le arról, hogy a Windows 10 ARM hátán szabad szemmel jól látható részesedést szerezzen a PC-piacból. Ennek ellenére a csúcskategóriás okostelefonokból is visszaköszönhet majd az X2, bár a méret és a disszipáció okán vélhetően csak erősen limitált darabszámban kerül be a piacot célzó chipekbe a dizájn.

Introvertáltak az IT-ban: a hard skill nem elég Már nem elég zárkózott zseninek lenni, aki egyedül old meg problémákat. Az 53. kraftie adásban az introverzióról beszélgettünk.
A tervezőmunka során kiemelt figyelmet kapott az elágazásbecslés továbbfejlesztése, amellyel nem csak a számítási teljesítményt, de a hatékonyságot is javítani lehet. A futószalag hossza 11-ről 10 ciklusra csökkent, az utasítás-kibocsátás pedig 2-ről 1 ciklusra apadt. Mindemellett 30 százalékkal, 224-ről 288-ra nőtt a ROB (re-order buffer) mérete. Ezek komoly változások, melyek számottevően befolyásolják az elérhető üzemi frekvenciát, így érdekes lesz látni, hogy a partnerek milyen órajeleket érnek majd el az X2-vel.
A mikroarchitektúra sematikus ábráján lejjebb haladva megjelenik Armv9-cel bemutatott SVE2. Ez a vektoros műveletek gyorsabb és hatékonyabb végrehajtásához beépített SVE (Scalable Vector Extensions) második iterációja, amely többek között adatpárhuzamosság terén jelent előrelépést. Az elődhöz hasonlóan a SVE2-nél a vektorok hossza az aktuális igényeknek megfelelően rugalmasan, 128 bites lépcsőkben variálható a 128 és 2048 bit közötti tartományban. A célpiacnak megfelelően az X2 128 bites vektorhosszt támogat négy FP/NEON futószalaggal.
A struktúra alján az MLP-re (Memory Level Parallelism) hatékonyságának javítására utaló fejlesztéseket látni. A LOAD/STORE ablak mérete harmadával nőtt, az L1 dTLB kapacitása pedig 20 százalékkal, 40-ről 48 bejegyzésesre bővült.
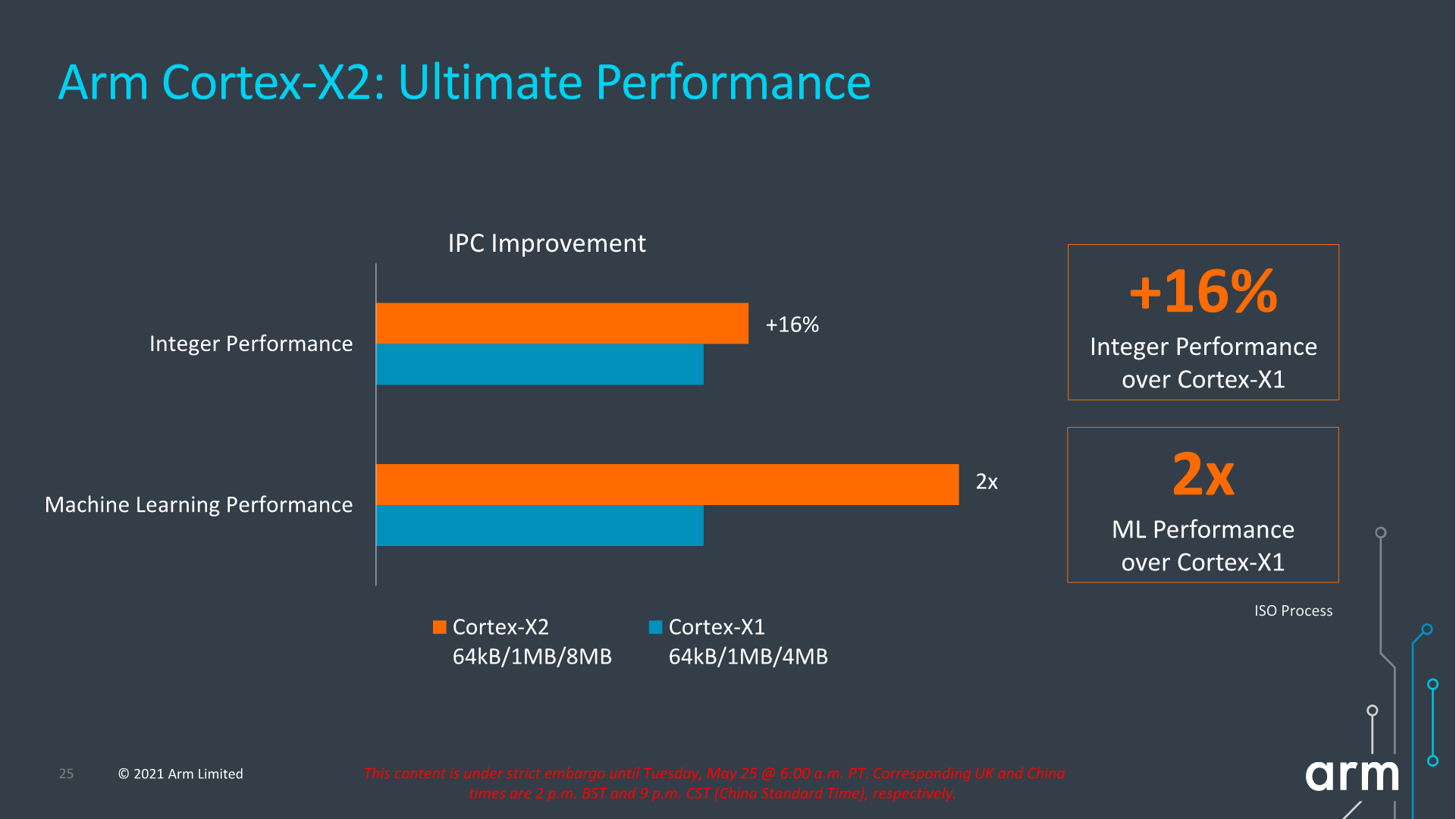
Az ARM belső, SPECint2006-ra alapozó mérésre alapján az IPC-t, vagyis egységnyi órajel alatt végrehajtott műveletek mutatóját tekintve 16 százalékot javult az X2 az elődhöz mérten, habár előbbi esetében 4 helyett 8 megabájt L3-as gyorsítótárat alkalmazott a cég. Mindezért cserébe nem csak a mag területe, hanem annak disszipációja is nőtt, ám ennek pontos mértéke a komplett lapkadizájnon, illetve a gyártáshoz használt csíkszélességen fog múlni.
A710: AZ ARANY KÖZÉPÚT
A Cortex-A710 az Austin mikroarchitektúra-család immár negyedik iterációja, amely a korábban megismert A78-A77-A76 vonalat folytatja. A mag a cégtől eddig megismert tervezési filozófiát viszi tovább, kiemelt hangsúlyt helyezve a teljesítmény, fogyasztás és a méret egyensúlyára.

Az A710-be néhány, az X2-nél sikerrel implementált fejlesztést emelt át a tervezőcsapat. Az egyik ilyen a szinte végtelenségig javítható elágazásbecslés, amelynek minél nagyobb pontossága a teljesítményre és a hatékonyságra egyaránt jótékony hatással van. Emellett az L1I TLB 50 százalékkal, 32-ről 48 bejegyzésesre nőtt, a macro-OP cache kapacitása azonban változatlan maradt. Érdekes lépés, hogy utóbbi, a dekódolt utasításokat tartalmazó tár, valamint az utasítás-kibocsátás áteresztőképességét 6-ról 5 szélességűre szűkítette az ARM, így csökkentve a disszipációt. Ezzel szemben a futószalag hossza itt is 11-ről 10 ciklusra csökkent, amely valószínűleg bőven kompenzálja a szűkítése miatt szenvedett csorbát.
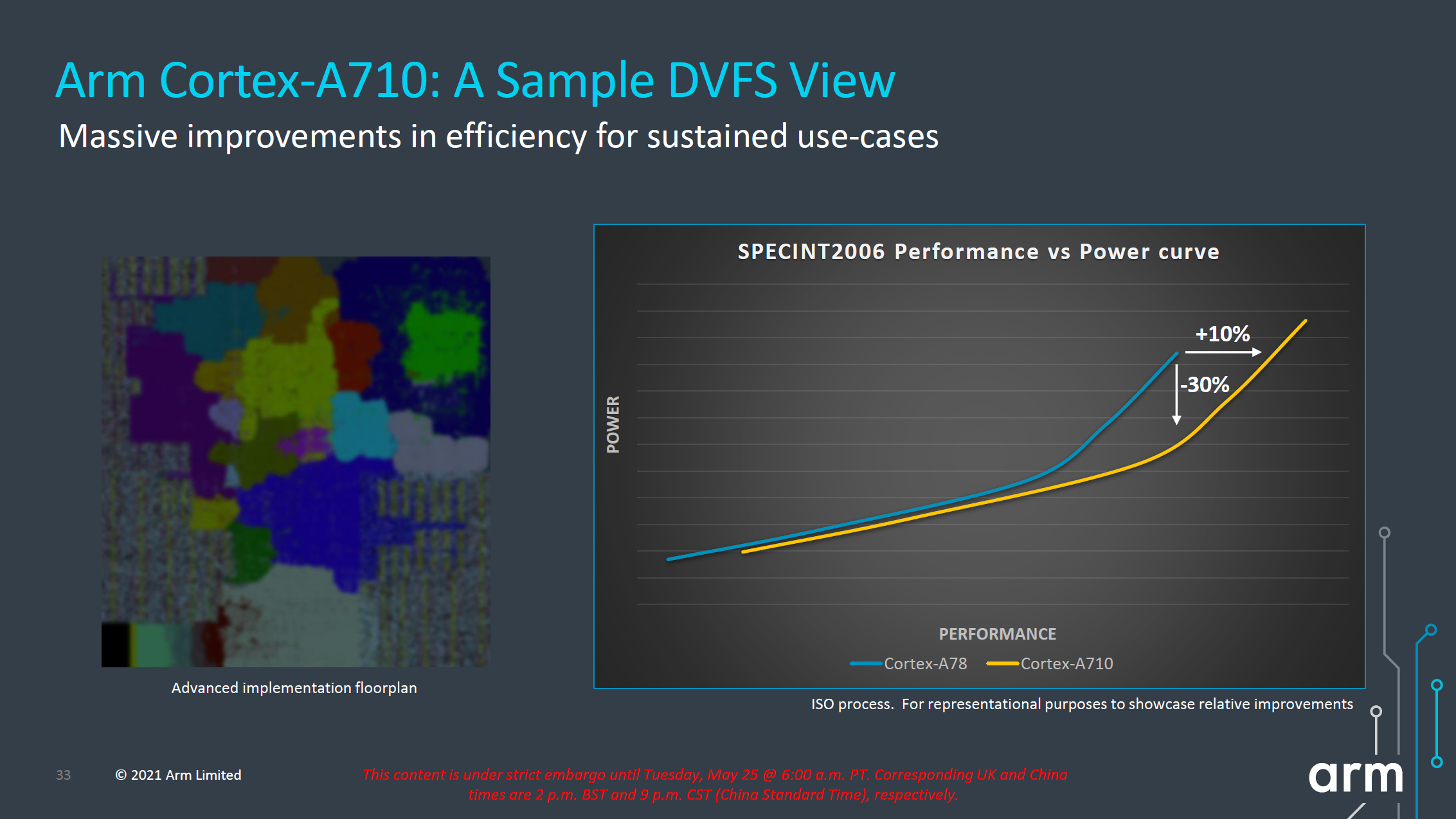
Az ARM szerint mindezzel 10 százalékos IPC növekedést értek el, azonban ahogy az X2 esetében, úgy itt is fennáll a nagyobb L3 cache esete, amely valamelyest befolyásolhatja az eredményt. A disszipáció ennél nagyobb mértékben, 30 százalékkal csökkent, amely lényegesen jobb hatékonyságot ígér.
A510: KICSI ÉS HATÉKONY
A bemutatott három fejlesztés közül a Cortex-A510 a legérdekesebb, amely a négy éve bemutatott A55-öt váltja. Az A510-es mikroarchitektúra az előddel kitaposott úton megy tovább, elsősorban a számítási teljesítményt növelését szem előtt tartva. Bár a feladat elsőre egyszerűnek tűnhet, a tempó növelését a tranzisztorbüdzsé és a fogyasztás számottevő emelkedése nélkül kellett megugrani, hisz az A5xx család feladata a lehető leghatékonyabb működés, ezzel pedig a minél hosszabb akkus üzemidő biztosítása.
Érdekes tervezői döntés, hogy ezért még az in-order végrehajtást sem volt hajlandó beáldozni a cég, így maradt a piacon egyre ritkább feldolgozási mód. A 3 utasítás széles dizájn még ennél is érdekesebb része az úgynevezett Merged-Core felépítés, amely kísértetiesen hasonlít az AMD egykori hírhedt Bulldozerénél látottakra. A cég által azóta mélyen eltemetett CMT (Cluster-based Multithreading) lényege, hogy egy komplexumom (vagy magon) belül a végrehajtószálak osztoznak bizonyos erőforrásokon A többmagos megoldásokkal (multi-core) szemben – mely több önálló, teljes értékű magot kapcsol egy lapkába a hatékonyság növelése érdekében – ezen eljárás fő célja a már rendelkezésre álló erőforrások optimális kihasználása.

A Cortex-A510 esetében egyetlen komplexumom belül két integer mag egyetlen lebegőpontos egységen (FP/NEON/SVE), illetve egy legfeljebb 512 kilobájtos másodszintű gyorsítótáron és TLB osztozik. Az AMD egykori megoldásához képest azonban fontos különbség, hogy a két integer mag saját, dedikált front-enddel, L1 cache-ekkel, illetve back-endekkel rendelkeznek, vagyis "csak" a lebegőpontos back-enden és az L2-es hierarchián osztozkodnak a magok. Ezzel a megközelítéssel disszipációt és lapkaterületet egyaránt megtakaríthat az ARM, a kérdés csupán az, hogy milyen áron.
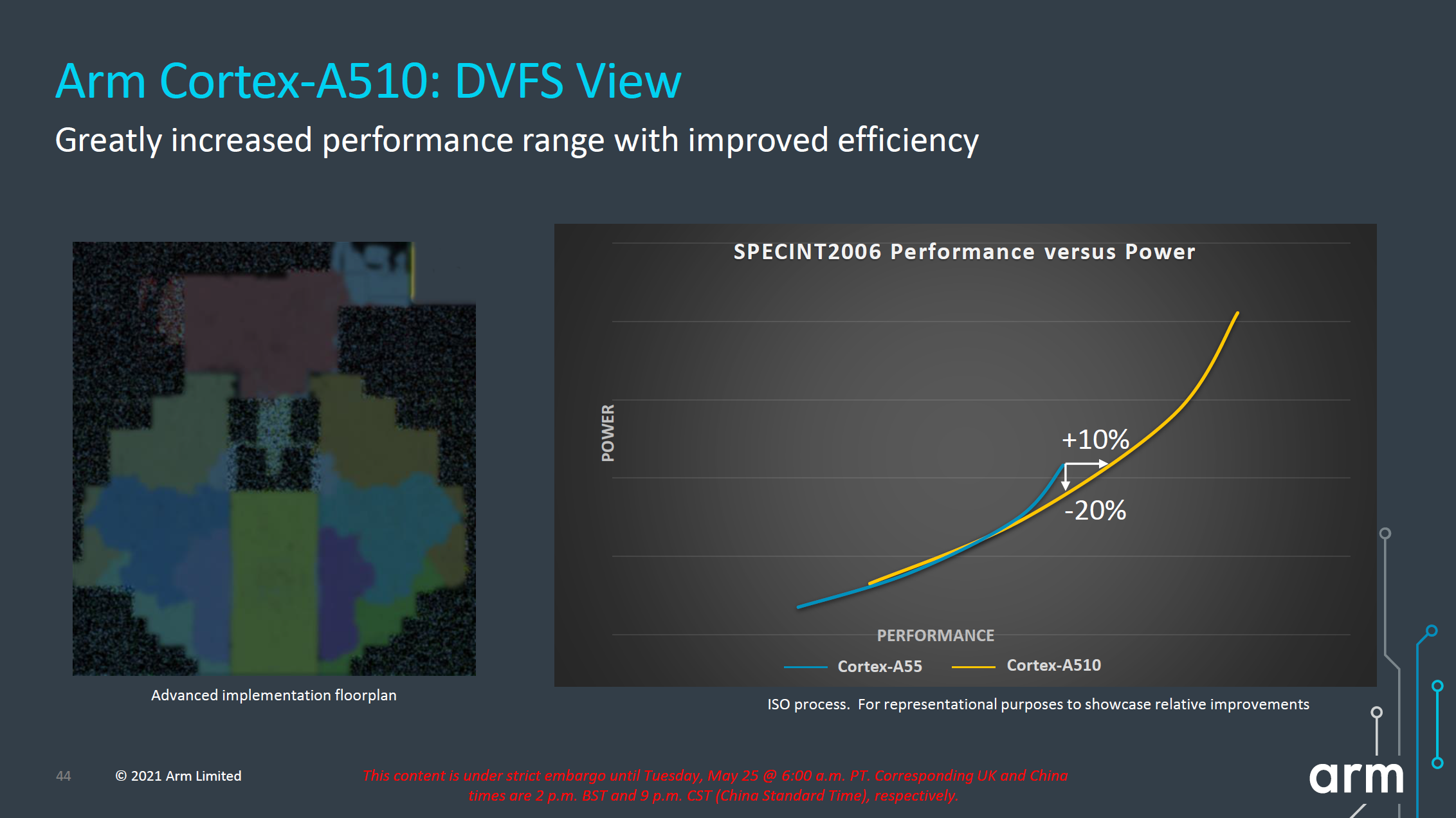
A tervezőcég szerint integer műveletekben 35, lebegőpontos végrehajtásban pedig 50 százalékos az A510 előnye a közvetlen elődhöz képest. Érdemes azonban szem előtt tartani, hogy az összevetésben mind az L2, mind pedig a L3 mérete az A55-ös konfiguráció kétszerese volt, vagyis 256 kilobájt és 8 megabájt. Ezt, illetve az előd bemutatása óta eltelt 4 éves figyelembe véve szerény előrelépésről beszélhetünk. Disszipációt tekintve sem tűnik megváltónak az A510, amely 20 százalékos mérséklődést vetít előre az A55-höz képest. Bár a konklúzióval ebben az esetben is érdemes lesz megvárni a végleges chipeket, jelen állás szerint úgy fest, az AMD-hez hasonlóan az ARM-nak sem sikerült igazán maradandót alkotni a CMT alapjain. Érdekes adalék, hogy független mérések szerint az Apple hatékonyságra kihegyezett Icestorm magja hasonló fogyasztás mellett nagyjából négyszer(!) gyorsabb az A55-nél.
A három új magra épülő első alkalmazásprocesszorokat valamikor az utolsó negyedév során jelenthetik be a nagyobb tervezőcéget, az első chipek pedig 2022 első felében kerülhetnek piacra.