A Huawei is saját gépi tanulásos gyorsítókat készít
A Huawei is előrukkolt házon belül tervezett gépi tanulásos gyorsítójával. A tréninghez fejleszett Ascend-Max sorozat három taggal indul, melyek közül a leggyorsabb, 910-es modell rendkívül magas számítási teljesítményre képes. A specifikációk alapján félpontosságú lebegőpontos műveleteknél a csúcsmodell közel kilencszer gyorsabb az Tesla V100-nál, miközben a Huawei fejlesztésének TDP-je csupán 40 százalékkal magasabb. A chipek mellé saját fejlesztésű, nyílt forráskódú keretrendszert is készít a vállalat, amely jövő év elején válik elérhetővé.
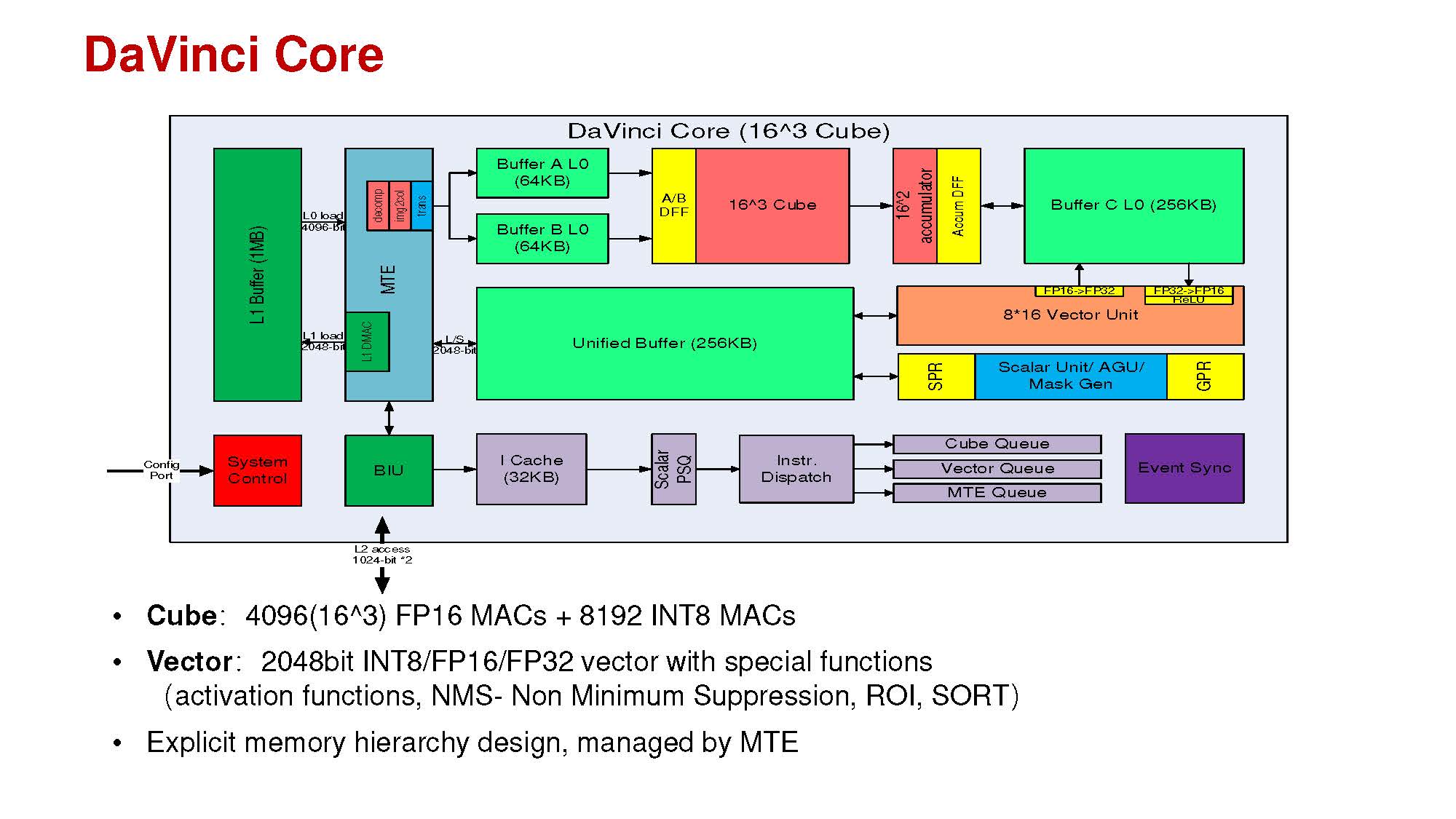
A Huawei gépi tanulásos gyorsítóinak alap építőkockáját a DaVinci mag jelenti, amellyel egészen kicsi, IoT Edge-es felhasználástól a teljesítményre kihegyezett legnagyobb kapacitású gyorsítókig skálázható a kínálat, viszonylag egyszerűen. A magokból ugyanis három típust tervezett a Huawei. A számítási tempóra kihegyezett dizájnokba a DaVinci Max-ot szánja a cég, amely egyetlen órajelciklus alatt 8192 úgynevezett Cube Ops végrehajtására képes 256 Vector Ops mellett. A középutat képviselő DaVinci Lite ennek pontosan a felére, azaz 4096 Cube Ops és 128 Vector Ops végrehajtására képes. A belépőszintű és/vagy kifejezetten alacsony fogyasztásra fókuszáló környezetekhez a DaVinci Tiny dukál 512 Cube Ops és 32 Vector Ops teljesítménnyel.
Introvertáltak az IT-ban: a hard skill nem elég Már nem elég zárkózott zseninek lenni, aki egyedül old meg problémákat. Az 53. kraftie adásban az introverzióról beszélgettünk.
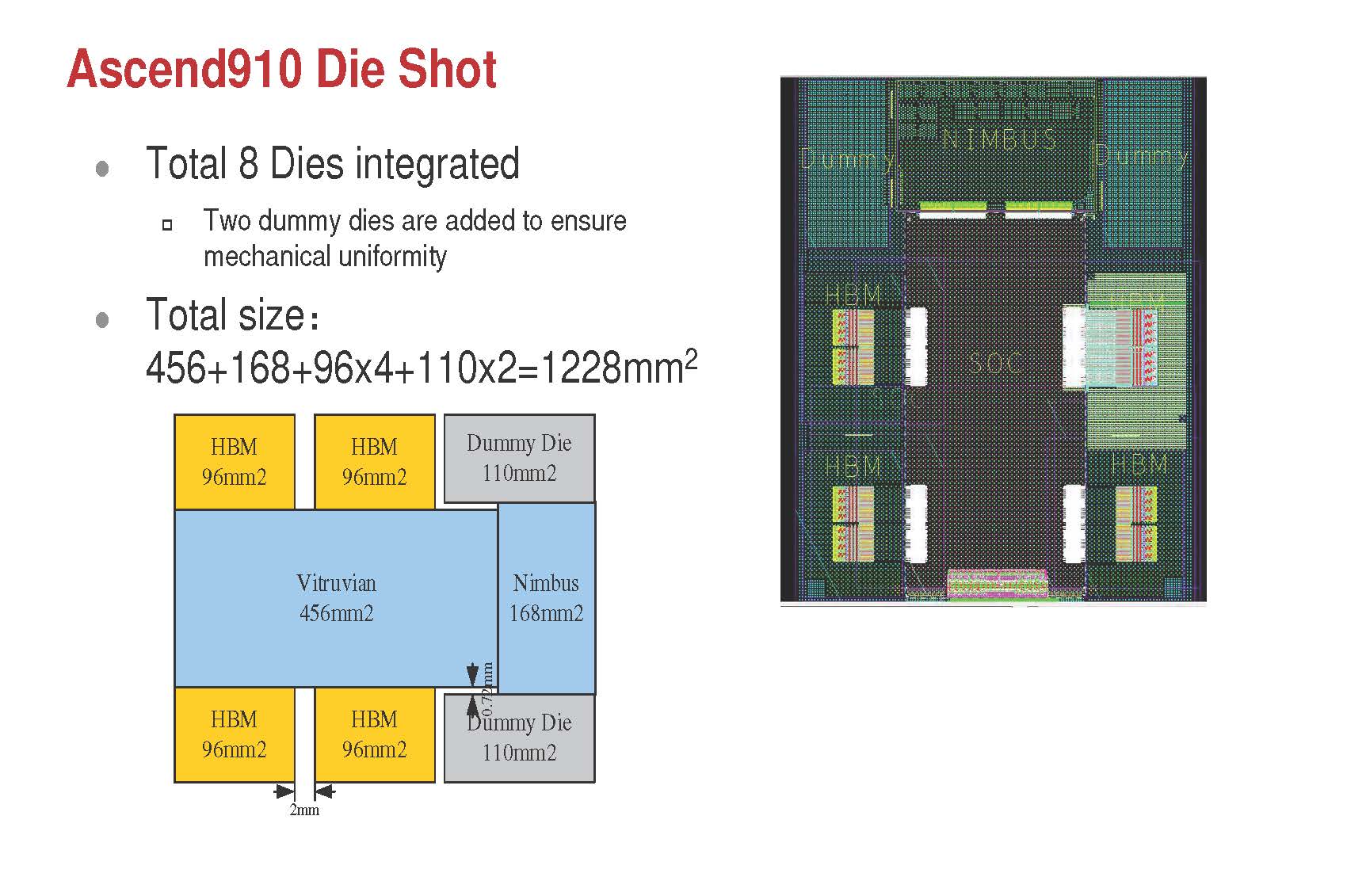
A jelenlegi csúcsot képviselő Ascend 910-ben összesen 32 darab DaVinci Max mag kapott helyet. A végrehajtóegységeket háló topológiával (mesh) kapcsolták össze a Vitruvian kódnevű lapkában, a végrehajtást pedig 32 megabájt megosztott gyorsítótár segíti. A magok mellé fixfunkciós dekódolók is kerülteket, melyek segítségével valós időben dolgozható fel 128 különálló videócsatorna adatfolyama, amely például különféle megfigyelőrendszereknél jöhet kapóra. A lapkában található memóriavezérlőhöz négy darab HBM 2-es memória kapcsolódik. Az aggregált sávszélesség 1,2 terabájt, amely aranyat ér a jellemzően memóriaigényes gépi tanulásos tréningnél. A kapacitásról nem beszélt a cég, azonban a chip opcionális DDR4-es modulok kezelésére is képes.
A Vitruvian mellé egy külön, Nimbus V3 kódnevű lapkába kerültek a csíkszélesség szempontjából kevésbé igényes áramkörök, így például a különféle buszok (PCIe, CCIX) és alrendszerek. Bár a Huawei erről egyelőre nem beszélt, kisebbik a lapkát vélhetően nagyobb (16 nanométeres?) csíkszélességgel gyártatja, mint az élvonalbeli, 7 nanométeres EUV eljárással készülő Vitruviant. (A megközelítés nem új, az AMD gyakorlatilag ugyanezt alkalmazza a Zen 2-es processzoroknál.) Terület szempontjából a nagyobb chipek közé sorolható az Ascend 910, a Vitruvian ugyanis 456, a Nimbus pedig 168 mm2-es, miközben az előbbihez néhány darab 96 mm2-es HBM 2 memória is kapcsolódik. A mechanikai stabilitáshoz további két darab üres, úgynevezett dummy die-t tervezett a processzorára a Huawei, melynek szerepe a hűtőblokk széleinek megtartása. Az utóbbival együtt összesen 1228 mm2 szilícium található a tokozáson.
Az Ascend 910 félpontosságú lebegőpontos műveleteknél (FP16) 256 TFLOPS-os, INT8 (8 bites integer) műveleteknél pedig 512 TOPS a csúcs. Ezek nagyon magas értékek, a Tesla V100-as gyorsítója ugyanis FP16 esetében 31,4 TFLOPS-ra, INT8-nál pedig 125 TOPS-ra képes. Az Nvidia GV100-as chip jelentős hátrányának egyik oka a klasszikus GPU-s felépítés, hisz míg az Ascend 910-et már kifejezetten gépi tanulásos műveletekre hegyezték ki, addig az Nvidia lapkája grafikus megjelenítésre is képes. Szintén a Huawei oldalára billenti a mérleget a fejlettebb, 7 nanométeres gyártástechnológia, amelyre az Nvidia csak a következő évben tér át. A számok azt mutatják, hogy a jövő a dedikált, kifejezetten gépi tanulásos műveletek gyorsítására kihegyezett áramköröké, így nem lenne meglepő, ha az Nvidia is ebbe az irányba mozdulna el, már akár 2020-ban.

Az Ascend 910-ből összesen 8 darab fér el egyetlen, vízhűtéses node-ban, amely így legfeljebb 2 PFLOPS számítási kapacitást nyújthat. Az egyes node-okból összesen 256 darab rendezhető egyetlen klaszterbe, amellyel 512 PFLOPS-os számítási teljesítmény érhető el. Az Ascend 910 Clustert az Nvidia DGX Superpodja inspirálhatta, amely nagyon hasonló módon épül fel.
Az Ascend gépi tanulásos fejlesztései mögött részben a Huawei függetlenedési törekvései állhatnak, az USA és Kínai közötti kereskedelmi háború miatt ugyanis továbbra is bizonytalan, hogy meddig vásárolhat chipeket amerikai beszállítóktól a kínai vállalat.
MindSpore számítási keretrendszer
A gyorsítók mellé egy dedikált keretrendszert is készít a Huawei. A vállalat szerint a MindSpore kialakítási koncepciójának köszönhetően a fejlesztők könnyen fejleszthetnek gépi tanulásos alkalmazásokat, modelljeiket pedig gyorsabban taníthatják. A tipikus, természetes nyelvi feldolgozással (NLP) foglalkozó neurális hálózatokban a MindSpore húsz százalékkal kevesebb kóddal rendelkezik, mint a piac más vezető keretrendszerei, ezért a fejlesztők hatékonyságát akár ötven százalékkal is képes növelni. Az Ascend processzorok mellett a MindSpore a GPU-kat, CPU-kat és más típusú processzorokat is támogat, a keretrendszer elérhetőségét pedig 2020 első negyedévére ígéri a Huawei.