Még egy lapáttal rátesz az ARM: jön a Cortex-A77
Tavaly bemutatott útitervének megfelelően jelentette be legújabb CPU-s mikroarchitektúráját, illetve az arra épülő első processzormagot az ARM. A brit tervezőcég Cortex-A77-es fejlesztése tovább növeli a tempót, amely az ígéret szerint 20-35 százalékkal múlja felül az idei év egyik slágerének számító Cortex-A76-ot.
Tavaszi mix a 2025-ös IT pangástól az interjúk evolúciójáig Ezúttal öt IT karrierrel kapcsolatos, érdekes és aktuális témát érintettünk.
Bár legfrissebb fejlesztésénél az ARM nem eszközölt fundamentális módosításokat, az A77 több ponton eltér az épp egy éve bemutatott elődtől, amely számottevő gyorsulásban nyilvánulhat meg. A tavaly még Deimos kódnéven elhintett fejlesztés a Cortex-A76 által újonnan lefektetett alapokra építkezik, amivel a cég egy több generációra szóló családnak ágyazott meg. Ennek a vásárlópartnerek szempontjából egyik nagy előnye, hogy viszonylag könnyű rá frissíteni, a körítéshez nem kell hozzányúlni, maradhat a DynamIQ-ra felfűzött kialakítás a jól hatékonyságra kihegyezett Cortex-A55 magokkal együtt.
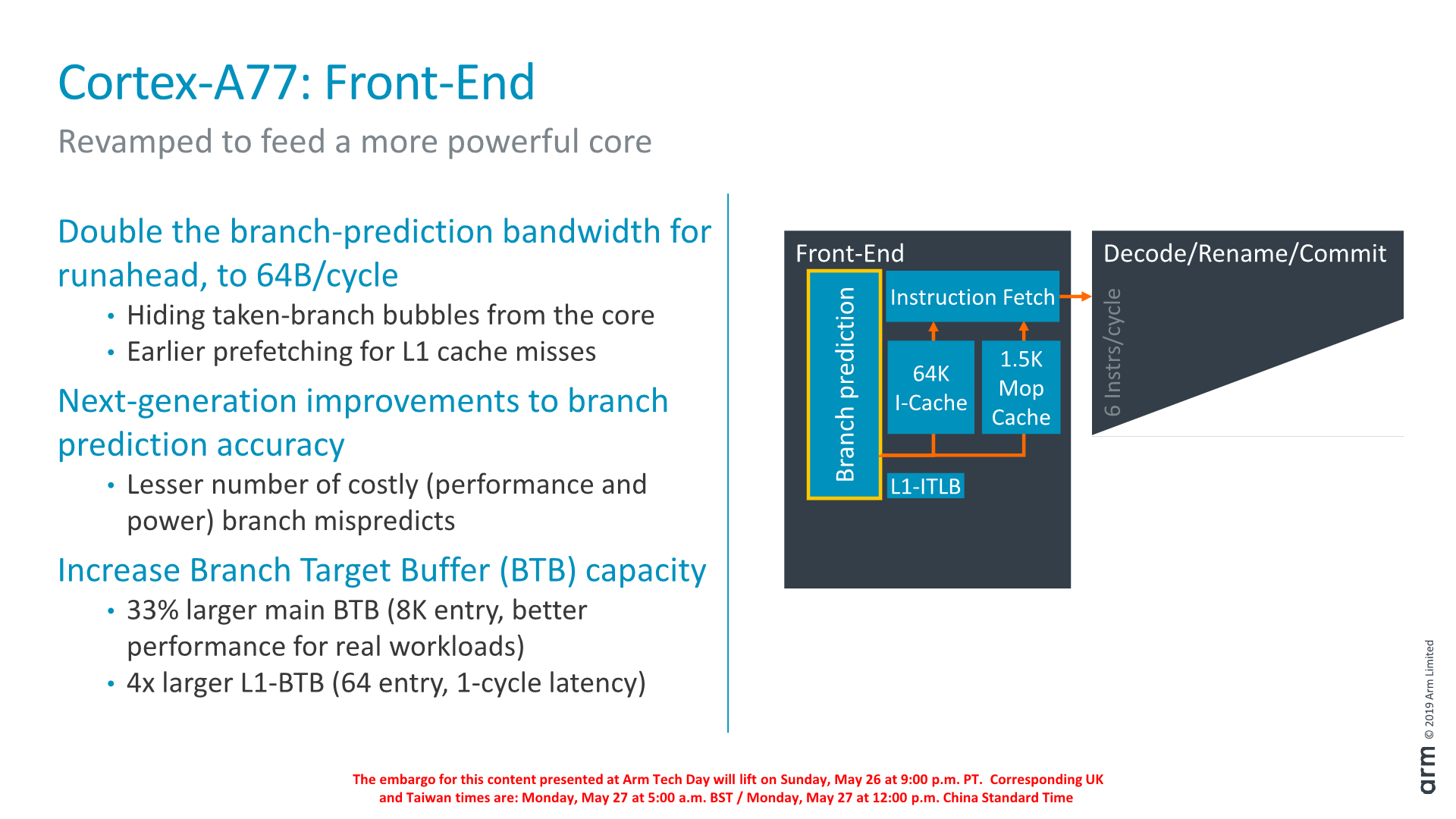
Az ARM a klasszikus gyorsítótárakhoz nem nyúlt, így az L1-es tárak kapacitása továbbra is 64 kilobájt, az L2 mérete pedig igénytől függően 256 vagy 512 kilobájt lehet. Megjelent azonban a front-endben az Intelnél a Sandy Bridge, az AMD-nél pedig a Zen óta jelen lévő micro-op cache. Ebbe a már lefordított utasítások micro-opjai kerülnek, amelynek pozitív következményei nyilvánvalóak: találat esetén nincs szükség az utasítás cache olvasására, sem pedig utasításdekódolásra, így az utasításoknak kettővel kevesebb futószalag-lépcsőn kell áthaladniuk, továbbá a téves elágazásbecslés büntetése is ennyivel kevesebb. A tár 1536 uop-ot képes befogadni amely egyezik a Skylake, de elmarad a Zen 2048, valamint a tegnap bemutatott Sunnycove 2304 micro-op-os kapacitásától. Az ARM szerint ez arra elég, hogy a hit-rate (vagyis annak az aránya, hogy a bekért adat már a gyorsítótárban hever) 85 százalékos lehet, amely mind a végrehajtás sebességére, mind pedig a disszipációra kedvező hatással lehet.
A front-endél maradva: Az utasítások betöltésének sávszélessége ciklusonként nőtt, a késleltetés pedig csökkent. Az elágazásbecslés most is fejlődött, amelynek egyik kulcsa a ciklusonként 32-ről 64 bájtra növelt áteresztőképesség, még tovább redukálva a lehetséges hibás predikciók számát. Szintén ezt szolgálja a megnövelt Branch Target Buffer (BTB), amely 6000 helyett már 8000 bejegyzést képes tárolni. Ezzel, illetve a feljebb említett micro-op cache közreműködéssel a téves elágazásbecslések büntetése 11-ről 10 ciklusra csökkent. Ugyancsak javult a már amúgy is rendkívül hatékony előbetöltés, amelyet a mérnökök további egységekkel értek el. Ehhez társul az úgynevezett rendszertudatos működés, amely a platformonként változó memóriakarakterisztikához igyekszik hozzáigazítani a rendszert.
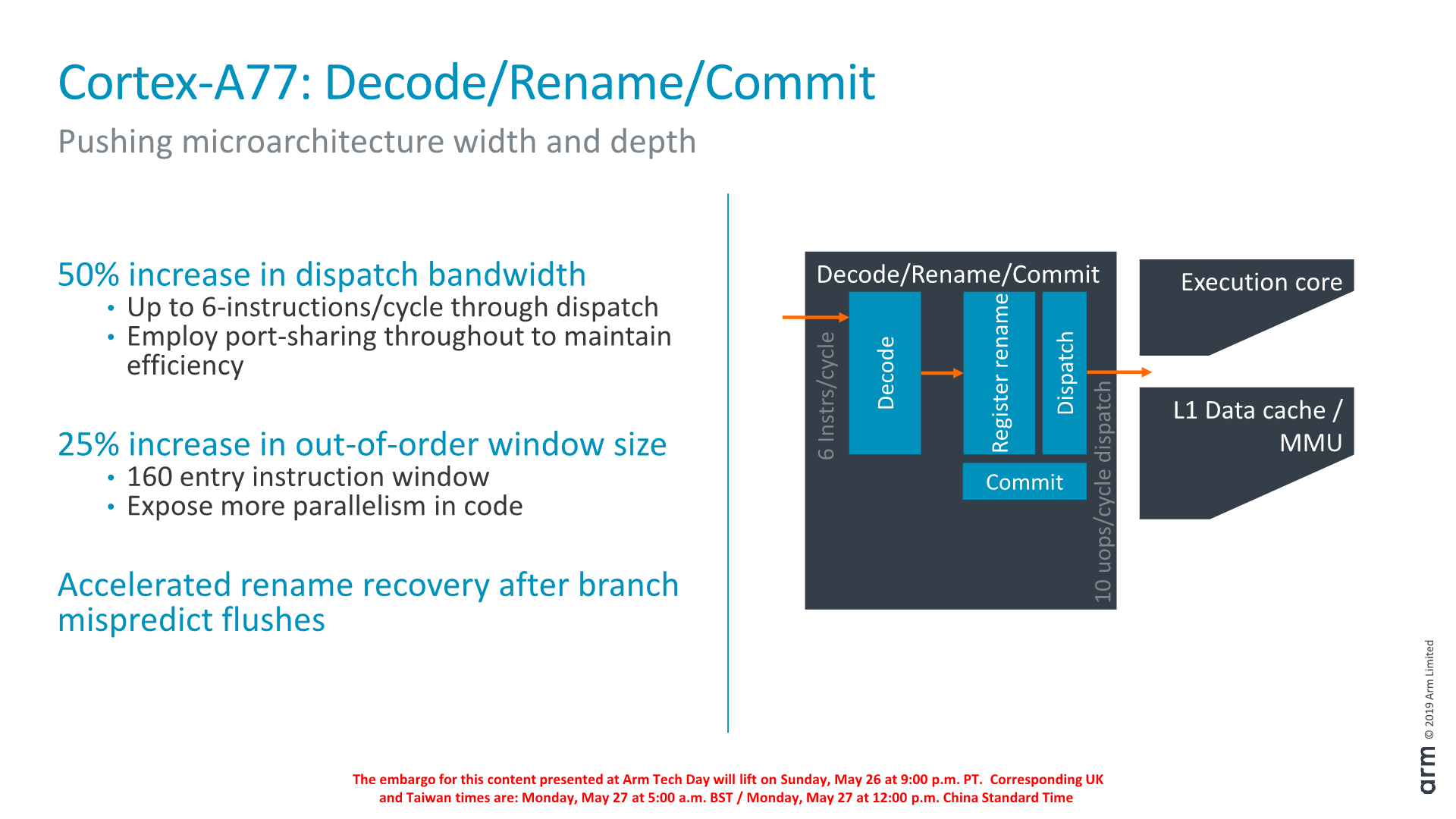
A dekódoláshoz is hozzányúlt az ARM, ahol felbukkant a legutóbb az Nvidia Denver kódnevű szakadár magjánál látott dinamikus kódoptimalizáció. A fejlesztés nem csak a nevében hasonlít, annak ugyanis az a feladata, hogy optimális sorrendbe állítsa a végrehajtásra váró utasításokat. A modern processzorokban ugyanis az áramkörök egy számottevő része nem az utasítások konkrét végrehajtásával foglalkozik, hanem azok átrendezésével, hogy a végrehajtóegységek a legmagasabb kihasználtsággal működhessenek. Anno ezt az Nvidia azért vetette be, hogy elég legyen egy egyszerűbb, in-order elven működő áramkört megtervezni. A Cortex-A77 azonban out-of-order logikát alkalmaz, amelyhez a Denverrel ellentétben nem egy kvázi szabadon programozható, hanem egy fix kódoptimalizációt társítottak a tervezők, ezzel növelve a hatékonyságot.
Az ARM a dekódert 50 százalékkal szélesítette ki, amely ezzel már 6 utasítás széles. Az A77 tehát egy ciklus alatt 6 utasítást képes lefordítani, amely a felsőkategóriás magok aktuális mezőnyében magas értéknek számít. Összevetés gyanánt: a Samsung M4 ugyancsak 6, az Intel Skylake 5, az AMD Zen 4 darab utasítás dekódolására képes. Ezzel párhuzamosan a ROB (ReOrder Buffer), tehát az átrendez körpuffert kapacitása is nőtt, 128-ről 160-ra. Ezen a téren láthatóan továbbra is takarékoskodik az ARM, a Samsung M4 ugyanis 228, az Intel Skylake pedig 224 bejegyzésre van felkészítve.
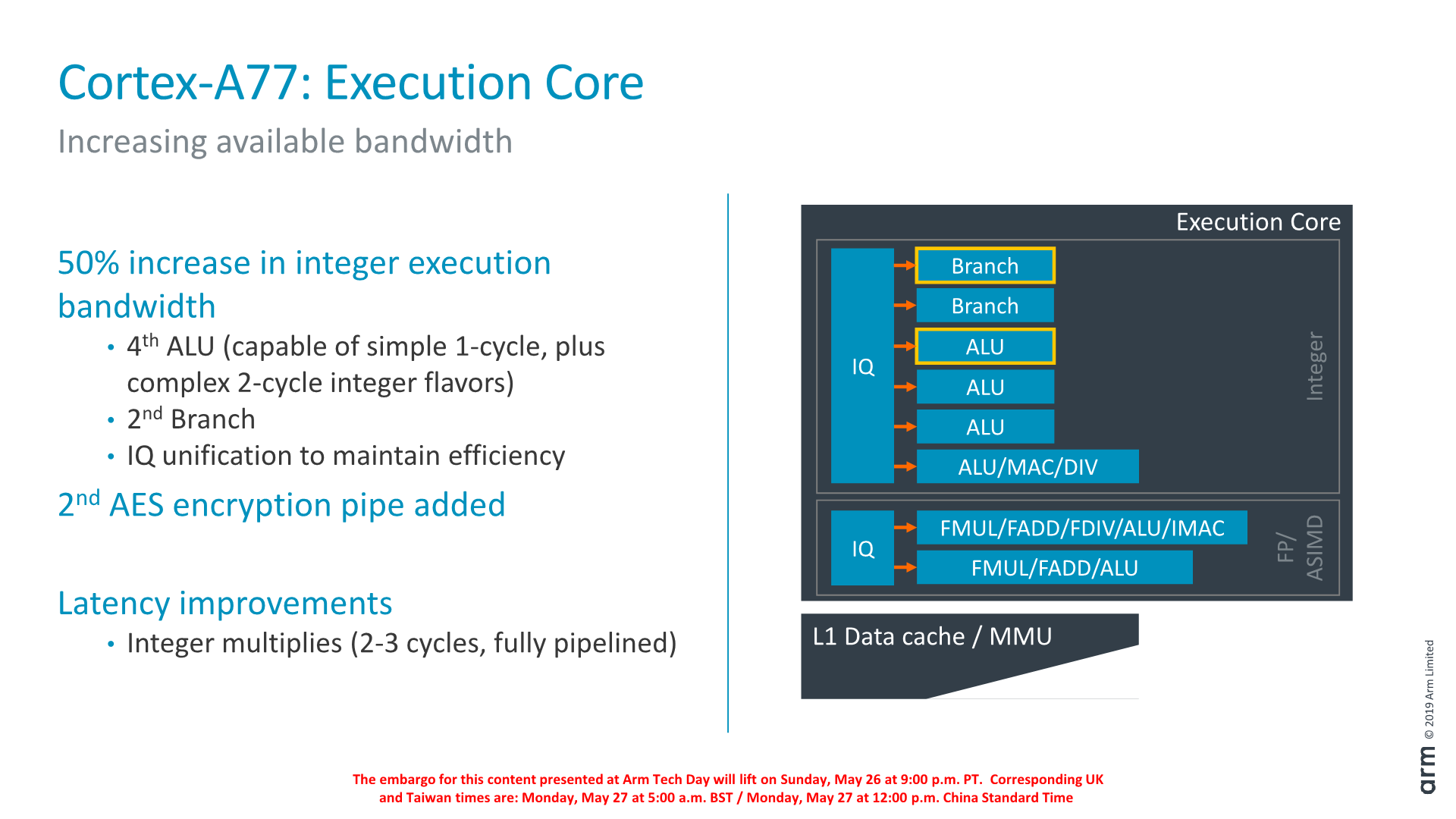
A front-end és a dekóder egyes fejlesztései most is a végrehajtók hatékonyabb etetését szolgálják. Az ARM ezen a fertályon is bővített, a további egy darab ALU-val az integer műveletek elvégzéséhez már 4+2 darab port áll rendelkezésre, amelyből kettő az elágazásbecslés működését szolgálja. A beépített plusz ALU képes egyciklusos, illetve a komplexebb kétciklusos művelet végrehajtásra is, ez pedig a tervezőcég szerint komoly előrelépést jelent számítási teljesítményben. Ugyancsak említésre érdemes, hogy immár két port képes AES műveletek elvégzésére, mely a titkosítást alkalmazó szoftverek esetében hozhat jelentős gyorsulást.
Mire lesz ez elég?
Összességében elmondható, hogy az ARM mindössze egy év után szokatlanul sok mindent átrajzol az A76-on. (Az Intel egykori, rendkívül sikeres stratégiájában ez a lépcső egyértelműen "takknak" számított volna.) A munkálatok természetesen jóval korábban elkezdődtek, mely alapján a tervezőcég nagyon komolyan gondolja, hogy pár éven belül számítási teljesítményben (is) faképnél hagyja az x86-os CPU-kat.
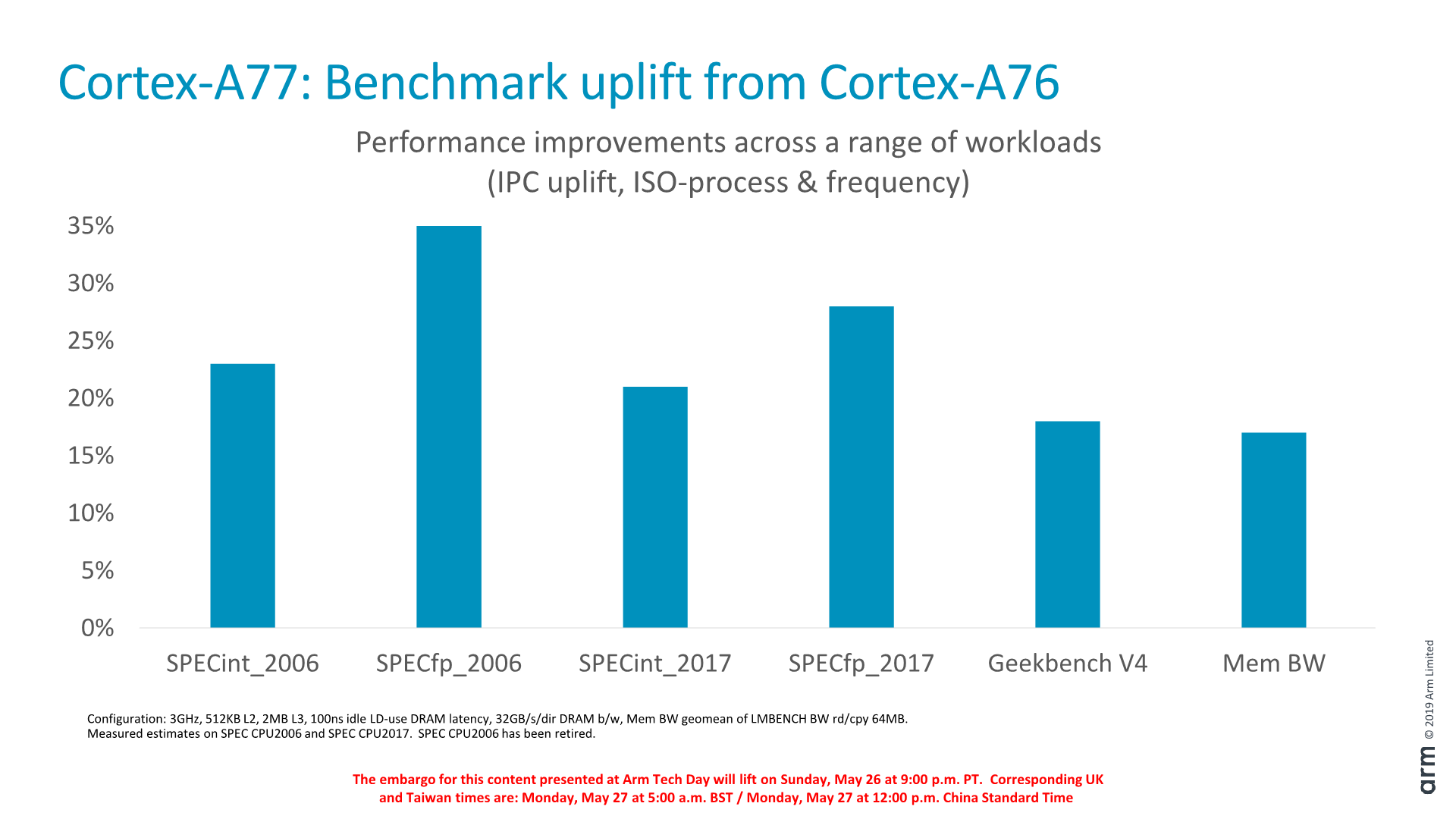
Ezt támasztja alá, hogy belső SPEC benchmarkok alapján 20-35 százalékos IPC növekedést mért a brit tervezőcég, vagyis azonos órajelen ennyivel volt gyorsabb az A76-nál az A77, amely a változatlan, 7 nanométeres csíkszélességet, illetve a 17 százalékos területnövekedést tekintve tetemes ugrás. Összevetés gyanánt: az Intel szűk 4 év alatt csak 18, az AMD pedig bő 2 év alatt 13-15 százalékos előrelépést ért el.