Paradigmaváltásban az Nvidia: itt a GeForce RTX széria
A korábbi pletykáknak megfelelően a tegnapi Gamescomon rántotta le a leplet legújabb GeForce sorozatáról (pontosabban annak egy részéről) az Nvidia. A bemutatott három videokártya a szintén újdonságnak számító RTX jelölés alá sorakozik be, amely egy részről az új felsőházat, más részről pedig az Nvidia ray tracing népszerűsítésére irányuló erőfeszítéseit szimbolizálja.
Ez utóbbi összességében nagyobb jelentőséggel bír mint az új termékek, a kapcsolódó fejlesztésekkel ugyanis egy nagyjából 10 éves folyamat első gyümölcsét ízlelgetheti majd a nagyközönség. Az Nvidia nyilvánvaló célja egy paradigmaváltás a PC-s játékok megjelenítésében, amely közelebb hozza egymáshoz valóságot és a grafikus megjelenítést. A tegnapi bemutató alapján úgy fest, hogy a piac vevő az új irányra, hamarosan nagyjából egy tucat játék érkezik valamilyen szintű ray tracing támogatással, amely megfelelő kiaknázásához természetesen GeForce RTX kártyára lesz szükség.
Az új kártyák alapját a Quadrókkal már meglebegtetett Turing grafikus mikroarchitektúra adja. Ennek egyik legfontosabb újítása az úgynevezett Hybrid Rendering. Ez a globális bevilágítási rendertechnikán alapuló ray tracing (sugárkövetés), illetve a hagyományos raszterizált grafika egyvelegét jelenti. Utóbbival egyre nehezebb látványos előrelépést felmutatni, egyes vélemények szerint a technika már elérte lehetőségeinek határait. Ezt vallja az Nvidia is, amely a minőség javításához a ray tracinget hívta segítségül. A vállalat egy több epizódból álló, fényekre, megvilágításra, árnyékokra, illetve visszaverődésekre kihegyezett bemutatón igyekezett szemléltetni a hibrid renderelés látható előnyeit.

Bár a ray tracing bár szabad szemmel jól látható különbségeket eredményezett, lélegzetelállító előrelépéséről nem beszélhetünk, legalábbis egyelőre. Az Nvidia igyekezett kiemelni, hogy a hangsúly a valósághű megjelenítésen van, illetve azt is, hogy az új lehetőségek kiaknázásához most is időre lesz szükség. Emellett vélhetően üzleti szempontból is jobb, ha lassan, generációról-generációra csepegteti a ray tracing előnyeit a cég, így téve vonzóbbá a következő generációs termékeket. A chiptervező egyébként szorosan együttműködik a stúdiókkal, amelynek köszönhetően olyan, csőben lévő húzónevek is megkapják a támogatást mint a Battlefield V, Metro Exodus vagy a Shadow Of The Tomb Raider. Az Nvidia jelenlegi, rendkívül erős piaci pozícióját tekintve nem csoda, hogy felsorakoztak a nagy stúdiók a cég mögé, amelynek hála véghez is viheti paradigmaváltását a cég.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A hardver és a szoftver (jelen esetben a játékok) mellett persze egy, a kettő közé beékelődő, megfelelő API is szükséges. Az Nvidia még márciusban beszélt a lassan tíz éves OptiX API-járól, amely mellé hamarosan, a Windows 10 őszi frissítésével érkezhet DirectX Raytracing, illetve majd a sugárkövetést ugyancsak támogató jövőbeni Vulkan verzió.
Fontos megjegyezni, hogy a ray tracinges fejlesztésekből a technológiát nem támogató játékok semmit sem profitálnak majd, illetve az is könnyen elfordulhat majd, hogy kikapcsolt állapotban (már amennyiben erre lesz lehetőség) számottevően megugrik majd a tempót. Mindez ugyanakkor látszólag nem aggasztja túlságosan az Nvidiát, amely mostanra akkora előnyt halmozott fel az egyetlen rivális AMD-vel szemben, hogy felvállalja a kockázatot. Ezzel ugyanis optimális esetben a sebesség mérlegének serpenyője mellett a képminőségét is saját oldalára billentheti a cég, még inkább differenciálva magát tehetetlen konkurenséről.
Gyorsító-gyorsító
Részben ehhez gyúrta ki a Turingot a chiptervező, amely dedikált végrehajtókat kapott az RT (Ray Tracing) magok formájában. A fejlesztésről egyelőre csupán néhány mondatban beszélt a cég, amely szerint a blokkok az úgynevezett ray-triangle intersection checks és bounding volume hierarchy (BVH) manipulation műveleteket hivatott jelentősen gyorsítani. Az Nvidia ígérete szerint ezzel a legerősebb Turing GPU (TU102) másodpercenként 10 milliárd sugár (gigarays) feldolgozására képes, amely a nyers tempót nézve óriási, huszonötszörös gyorsulást jelent a legerősebb Pascalhoz viszonyítva. Az effektív gyorsulás ennél persze szerényebb lehet, az Nvidia hatszoros szorzóról beszélt az említett elődhöz képest.
Az új grafikus mikroarchitektúra azonban nem csak ebben hoz előrelépést. A Turingba bekerült a Voltában debütált Tensor mag is, egészen pontosan annak egy továbbfejlesztett variánsa. Ez eredetileg a gépi tanulásos műveletek során használt tipikus utasítások gyorsítása miatt jött világra, a Turinggal viszont ezt igyekszik a grafikában, azon belül pedig elsősorban ray tracingben kamatoztatni a cég. A Tensor magok ugyanis befoghatóak a megjelenítés gyorsításához is, gépi tanulásos algoritmussal ugyanis az egyes jelenetekből a felesleges sugarak (rays) "kivághatóak". Ehhez az NVIDIA NGX formájában egy új SDK-t is kiad a cég, amellyel a Tensor magok különféle képfeldolgozási segédműveletekre is befoghatóak lesznek, az ígéret szerint például egy minden eddiginél jobb minőségi élsimítási eljáráshoz.
Shadow of the Tomb Raider: Exclusive Ray Tracing Video
Még több videóItt érdemes pár szóban kitérni az Nvidia kvázi új tervezési filozófiájáról, amely egyre több (fél)fixfunkciós egységet (RT és Tensor core) tartalmaz a klasszikus grafikus feldolgozók mellett. Az ilyen típusú végrehajtók rendkívüli hatékonysággal képesek végrehajtani bizonyos műveleteket, a gyakorlatban a specializált grafikus gyorsítók további specializációjáról van szó. A hangsúly itt a bizonyoson van, a hatékonyságért cserébe ugyanis rugalmatlanság jár, fixfunkciós egységek jellemzően korlátolt számú művelettípussal boldogulnak. Az Nvidia ezért igyekszik a lehető legtöbb területen kamatoztatni a szilíciumba (drágán) beépített egységeket, amely próbálkozás eddig (látszólag) sikeres.
A specializált egységek mellett az alap építőelemnek számító, általánosabb számításokra képes Streaming Multiprocessor (SM) is továbbfejlődött. A fejlesztés keretében a Turing megörökölte a Volta eddigi egyik sajátosságát, az integer és a lebegőpontos végrehajtók ugyanis immár két külön blokkban, elszeparáltan vannak jelen, amely független (és teljesen párhuzamos) végrehajtást tesz lehetővé. A Voltánál látottak alapján ezzel például gyorsítható a címgenerálás és az FMA (Fused Multiply Add) műveletek végrehajtása. Bár az Nvidia egyelőre nem erősített meg, a Turing vélhetően a gyorsabb végrehajtással kecsegtető fast FP16-ot is támogatja. Ez dióhéjban azt jelentheti, hogy az Nvidia új üdvöskéje is támogatja az RPM-et (Rapid Packed Math). A konkurens AMD Vegával bemutatkozott képességgel több kisebb műveletet lehet egyetlen csokorba fogni és tempósabban végrehajtani. Ezzel egyes jelenetek jelentősen gyorsíthatóak, bizonyos esetekben ugyanis egyszerűen nincs szükség az egyszeres pontosságra (FP32) sem.
Az úgynevezett "unified cache architecture" fejlesztésről egyelőre hallgat az Nvidia, az egyik GPU-t ábrázoló képen azonban felbukkant az "Unified L1 cache" képesség, amely egységesített elsőszintű gyorsítótárra utal. Hasonlót a Voltánál is láthattunk, ott az L1-et a megosztott memóriával vonta össze az Nvidia, azonban egyelőre nem tudni, hogy jelen esetben is erről van-e szó. A tervezőcég csupán annyit árult el, hogy a gyorsítótár sávszélessége kétszerese az "előző generációénak", azonban arra nem derült fény, hogy itt a Pascalra vagy a Voltára céloztak a készítők. Végezetül variable rate shading képességet érdemes kiemelni, amelyről szintén csak pár mondatot közölt a cég. Ez alapján a lehetőséget meglovagolva egyes shaderek felbontása eltérhet, amellyel az erőforrások koncentrálhatóak a magasabb prioritású, részletgazdagabb, vagy a gyorsabb végrehajtást igénylő shaderekre.
Három új videokártya
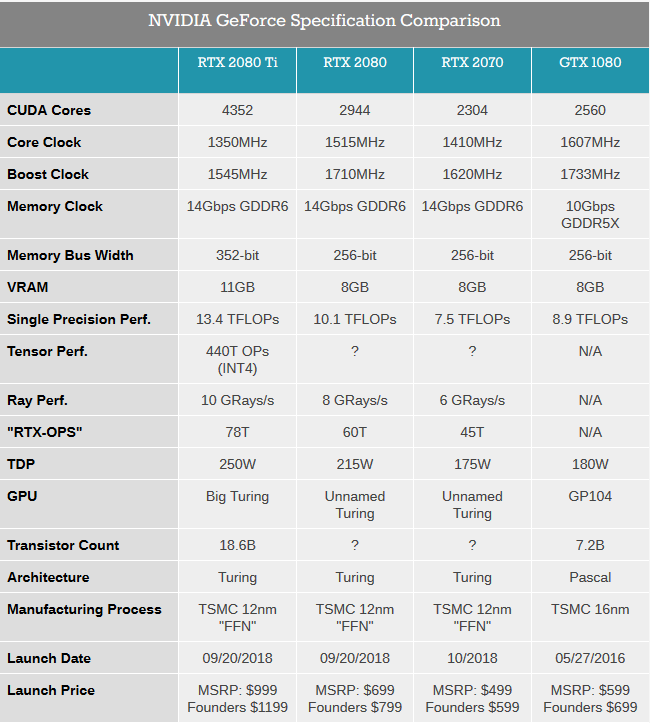
Az ray tracing korszak kezdetével kézenfogva három új terméket is bejelentett az Nvidia a GeForce RTX 2080 Ti, RTX 2080, illetve RTX 2070 kártyák formájában. Ezek közül természetesen most is a Ti jelülésű modell jelenti a csúcsot, és amennyiben nem jön újabb Titan, úgy ez jó darabig így is maradhat. A kártyára a legnagyobb, TU102 kódnevű Turing GPU került, amely óriási, 754 mm2-es alapterületén mintegy 18,6 milliárd tranzisztort vonultat fel, alig elmaradva a rekord nagy GV100 értékétől. A tetemes méret mögött a kvázi változatlan gyártástechnológia áll, a TSMC 12FFN kódnevű fejlesztése ugyanis gyakorlatilag az előző, Pascal generációnál alkalmazott 16 nanométer optimalizált variánsát jelöli, amely tranzisztorsűrűségben nem jelent előrelépést. Ez rendkívül fontos, hisz emiatt lényegesen kisebb mozgásterük volt a tervezőknek, akik egyébkénként a Maxwellel már bebizonyították, hogy csíkszélességváltás nélküli is el lehet érni tetemes előrelépést.

A gigászi GPU nem kevesebb mint 4352 darab CUDA magot rejt, amelyek alapórajele 1350 MHz, a turbó pedig kártyától függően 1545 vagy 1635 MHz lehet. A processzorhoz egy ritka szélességű, 352 bites buszon kapcsolódnak a Samsung 14 Gbps sebességű GDDR6-os chipek. A 352 bit páratlan számú, egészen pontosan 11 darab (32 bites) 1 gigabájtos chipet takar, amellyel igen magas, 616 GB/s-os maximális sávszélességet ért el az Nvidia a már említett memóriatípusnak hála. Ahogy arról korábban már többször írt a HWSW, a GDDR6 lényegesen nagyobb kapacitássűrűséget és sávszélességet kínál, amelyet kihasználva például azonos darabszám mellett növelhető a kapacitás és sávszélesség, vagy akár a korábbi értékek állíthatóak elő kevesebb chippel, kisebb komplexitás mellett - magyarán olcsóbban. Joggal merülhet fel a kérdés, hogy az Nvidia miért nem HBM2 chipeket választott a Turing mellé. A válasz prózai, a villámgyors rétegzett memória ugyanis nem csak rendkívül hatékony, de rendkívül drága is, a chipek mellett ugyanis a gyártási költség is tetemes az összeköttetéshez szükséges interpózer miatt.
A GeForce RTX 2080 Ti megjelenítési tempójáról egyelőre jóformán semmi konkrétumot nem árult el az Nvidia. Mindössze annyit tudni, hogy a nyers számítási teljesítmény 13,4 TFLOPS, amely papíron alig 16 százalékkal magasabb az előd értékénél. Az egyszeres tempó mellé ugyanakkor további két paramétert is megnevezett a cég a ray tracing teljesítmény és a RTX-OPS formájában. Előbbire a már említett 10 GRays/s-os értéket, utóbbira pedig 78T-t adott meg a tervezőcég, amely az előző generáció ezen képességeiről nem beszélt, így összehasonlítási alapnak ez nem használható.
 forrás: AnandTech
forrás: AnandTech
Az Nvidia által tervezett Founders Edition kártya TDP-je 260 watt (a gyártópartneri verzióké 250 watt lesz), amely maximális disszipáció elvezetéséért egy vadiúj tervezésű, két ventilátoros hűtés gondoskodik. A tervezőcég szerint ez minden helyzetben sokkal halkabb (és hatékonyabb) mint a hosszú évekig használt hajszárítószerű koncepció, amelynek ugyanakkor vitathatatlan előnye volt, hogy kiterelte a házból a hűtőbordáról leváló meleg levegőt. A hátoldalra négy DisplayPort 1.4, illetve egy VirtualLink csatoló került, amely VR-headsetek szabványos csatlakozója. Az USB Type-C portra alapozó megoldásnak hála az eszközökről eltűnhetnek a zavaró "kábelcopfok", és a szemüvegek egyetlen vezetéken csatlakozhatnak majd a számítógéphez.
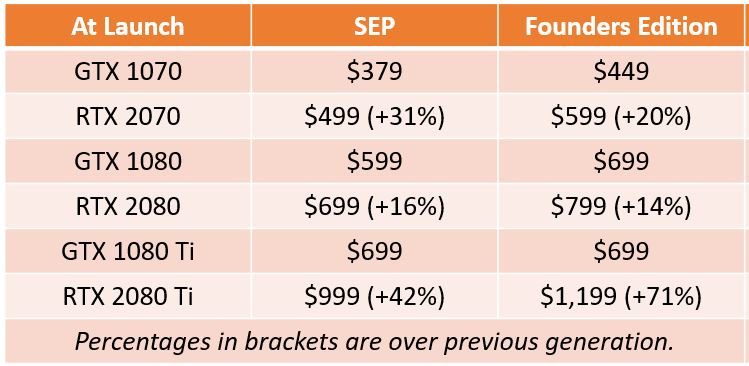
Mindezért cserébe igen mélyen zsebbe kell nyúlni, a közvetlen elődhöz képest ugyanis 43-71(!) százalékkal kerülhet többe a Ti kártya, amelyért az Nvidia nettó 1200, a partnerek pedig nettó 1000 dollárt kérnek (vagy inkább kérhetnek) majd. Arról egyelőre csak találgatni lehet, hogy a masszív áremelkedésért cserébe mekkora lökést kaphat majd a vásárló, mennyire lesz párhuzamban a felár és a megjelenítési tempó gyorsulása. Azt egyelőre nem tudni, hogy a hivatalos tesztek pontosan mikor láthatnak napvilágot, az RTX 2080 és 2070-re leadható előrendeléseket viszont szeptember 20-tól kezdi teljesíteni az Nvidia, így várhatóan legkésőbb egy hónap múlva fény derül az igazságra.
 A csúcsmodell mellé két, várhatóan sokkal népszerűbb kártyát is bejelentett a GTX 1080 és GTX 1070 közvetlen utódjai személyében. A kártyák egyaránt a kisebb, TU104 GPU-ra épülnek, amelyről mindeddig semmit nem árult el az Nvidia. Az RTX 2080 specifikációk alapján vélhetően legfeljebb 2944 CUDA mag lapulhat a lapkában, amelyből egy jó adagot letiltva 2304 darab maradt az RTX 2070-hez (~-22%). A két kártya között van némi órajelkülönbség is, hisz míg az RTX 2080 1515 MHz-es alapot és 1710 MHz-es turbót kapott, addig az RTX 2070-nél be kell érni 1410/1620-szal. Ennek hatására a 2080-as modell 10,1, a 2070 pedig 7.5 TFLOPS nyers számítási teljesítményre képes, ami a GTX 1080-hoz viszonyítva rendre +13,5 és -15,7 százalékos különbséget jelent egyszeres pontosság mellett. A memóriát tekintve nincs különbség a két modell között, az RTX 2080-ra és 2070-re is 8 gigabájt GDDR6 került, amely a 256 bites busznak hála 448 GB/s sávszélességet eredményez.
A csúcsmodell mellé két, várhatóan sokkal népszerűbb kártyát is bejelentett a GTX 1080 és GTX 1070 közvetlen utódjai személyében. A kártyák egyaránt a kisebb, TU104 GPU-ra épülnek, amelyről mindeddig semmit nem árult el az Nvidia. Az RTX 2080 specifikációk alapján vélhetően legfeljebb 2944 CUDA mag lapulhat a lapkában, amelyből egy jó adagot letiltva 2304 darab maradt az RTX 2070-hez (~-22%). A két kártya között van némi órajelkülönbség is, hisz míg az RTX 2080 1515 MHz-es alapot és 1710 MHz-es turbót kapott, addig az RTX 2070-nél be kell érni 1410/1620-szal. Ennek hatására a 2080-as modell 10,1, a 2070 pedig 7.5 TFLOPS nyers számítási teljesítményre képes, ami a GTX 1080-hoz viszonyítva rendre +13,5 és -15,7 százalékos különbséget jelent egyszeres pontosság mellett. A memóriát tekintve nincs különbség a két modell között, az RTX 2080-ra és 2070-re is 8 gigabájt GDDR6 került, amely a 256 bites busznak hála 448 GB/s sávszélességet eredményez.
 forrás: TPU
forrás: TPU
Az előző generációhoz hasonlóan az 80-as és 70-es végű modellekből is készült Founders Edition variáns, amelyeket felárral kínál az Nvidia. Ennek megfelelően saját tervezésű RTX 2080-ért nettó 800, RTX 2070-éért pedig nettó 700 dollárt kér a cég, a gyártópartneri verziók ennél (elvileg) 100 dollárral olcsóbban kerülnek majd forgalomba. Mindez ugyancsak számottevő (100-120 dolláros) áremelkedést jelent, hisz a GTX 1080 bő két éve 700/600, a GTX 1070 pedig 380 dolláros árcédulával debütált. Ahogy a csúcsmodell, úgy a két kisebb kártya esetében sem tudni, hogy a konkurenciaharc kvázi teljes hiánya, vagy inkább a gyakorlati előrelépés indokolja az áremelkedéseket, amely kérdésre hamarosan, pár héten belül megérkezhet a konkrét válasz.