Leggyorsabb processzormagját mutatta be az ARM
Az ARM szerint a bivalyerős Cortex-A76 csupán 10 százalékkal lassabb az Intel Skylake magjánál, így a fejlesztéssel már a PC-piacot is célba vehetik majd a partnerek.
Leleplezte eddigi legizmosabb processzormagját az ARM. Az angliai központú tervezőcég Cortex A76 fejlesztése egy vadi új mikroarchitektúrára épül, amelynek tervezését nulláról kezdték a mérnökök nagyjából négy esztendővel ezelőtt. Ennél érdekesebb, illetve piaci szempontból fontosabb, hogy vadiúj magjának teljesítményét csak a "laptop-class" jelzővel illette az ARM, amely IPC-ben (egy órajelciklus alatt elvégzett műveletek száma) 10 százalékon belül van az Intel Skylake-hez képest. A tervezőcég szerint az acélos számítási teljesítmény ellenére maradt az ARM magjaira jellemző alacsony energiaigény, amely kimagasló hatékonyságot sejtet.
Az AnandTech beszámolója szerint a már említett "laptop-class" kifejezés többször előkerült az A76-ot bemutató prezentáció során. Mindez arra utal, hogy legújabb fejlesztésével elsősorban (vagy első körben) nem az okostelefonokat, hanem az egyelőre pályafutásuk hajnalán járó ARM-os PC-ket célozhatja a tervezőcég. Ezekből egyelőre meglehetősen limitált a kínálat, a Qualcomm platformjára épülő, Windows operációs rendszerrel szerelt rendszerek tempója pedig a hírek szerint számos esetben egy reumás csigáéhoz hasonlítható, amely magyarázza az ARM fejlesztésének létjogosultságát.

Ezzel együtt az A76 bizonyosan beszivárog majd az okostelefonokba is, hisz az ARM legalább kettő további generáció erejéig tartaná meg, illetve finomhangolná a texasi Austinban felépített mikroarchitektúrát. Ennek tervezésekor a számítási teljesítmény állt az első helyen, tehát az ARM célja egy kifejezetten erős mag elkészítése volt a hatékonysági mutatók szigorú szem előtt tartása mellett. A mérnökök ezért minden korábbi dizájn alapját sutba vágták, amely bár számottevően növelte a tervezési munkálatok idejét, cserébe lehetőséget adott a korábban felfedezett szűk keresztmetszetek és limitációk átvágására. A sok éves munka 35 százalékos teljesítménynövekedés, illetve 40 százalékkal jobb hatékonyság hozott a tervezőcég mérései szerint (az A75-höz képest).
Bár mindezért az ARM szerint nulláról rajzolták meg a mikroarchitektúrát, az első ránézésre nem mutat éles különbségeket a közvetlen elődökhöz képest. A front-end részét képző dekóder például a ma már kvázi sztenderdnek számító szélességet kapta, az 4 utasítást képes egy órajel alatt lefordítani, ezzel pedig az ARM eddigi legszélesebb megoldásának számít. Összevetés gyanánt: a Samsung M3 legfeljebb hat, az Intel Skylake öt, az AMD Zen négy, az ARM népszerű A72-es fejlesztése pedig három darab utasítás dekódolására képes. Mindez önmagában még nem meghatározó, a Zenhez hasonló szélesség ugyanakkor árulkodó, az AMD-nek ugyanis ezzel sikerült szorosan a Skylake mögé felzárkóznia.

Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Ennél egy fokkal érdekesebb az elágazásbecslés, a tervezőcég ugyanis állítja, az implementált hibrid indirekt (hybrid indirect predictor) becslő egyedülállónak számít. A szóban forgó elágazásbecslő különáll az előbetöltőtől, ennek hála pedig teljesen önállóan képes működni. Az ARM szerint ezzel a gyorsabb végrehajtás mellett az energiahatékonyság is növelhető, hisz az egység önmagában lekapcsolható, amennyiben éppen nincs rá szükség. Egyébként a tervezőcég szerint az A73 és az A75 elágazásbecslője is rendkívül hatékonynak bizonyult, az A76-tal viszont még ezt is sikerült felülmúlni.
Említésre érdemes még az L1 utasításcache, amely 64 kilobájtos. Ez megfelel a közvetlen elődök értékének, illetve a már említett AMD Zen is ugyanekkora gyorsítótárat alkalmaz, szemben az Intel Skylake fele ekkora, 32 kilobájtos L1I-jéhez képest. A végrehajtók hatékonyabb etetéséhez alkalmazott ROB (ReOrder Buffer), tehát az átrendező körpuffert kapacitása is nőtt, ugyanakkor ezen a téren láthatóan igyekezett takarékoskodni az ARM. A 128 bejegyzéses ugyanis szinte eltörpül a Samsung M3 228-as, illetve az Intel Skylake 224-es értékéhez képest. A tervezőcég szerint a látszólagos spórolás első számú oka, hogy a ROB nagyon rosszul skálázódik, 7 százalékkal több bejegyzés mindössze 1 százalékos növekedést hoz a számítási teljesítményben.
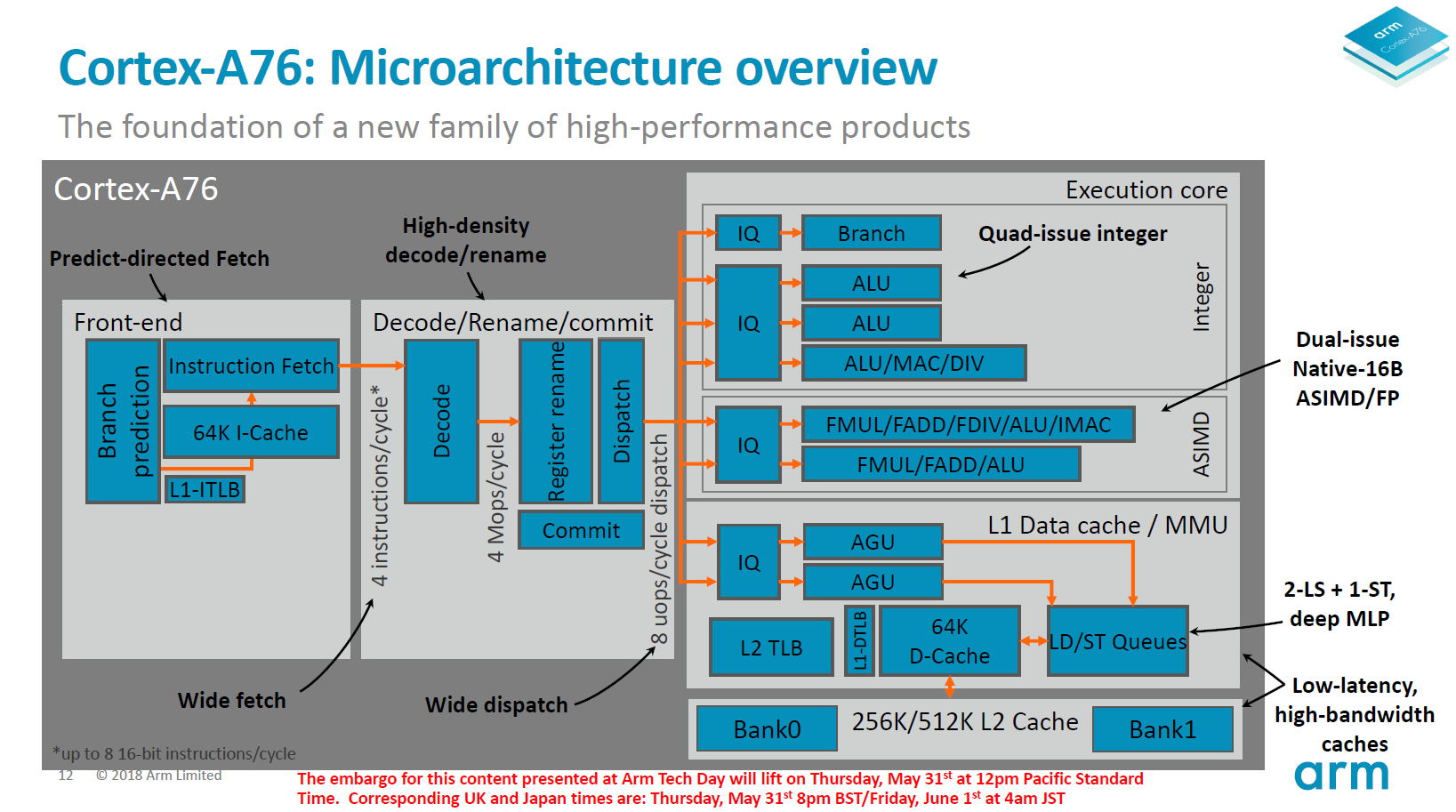
A back-endet tekintve is látható, hogy az ARM bár a számítási teljesítmény növelésére helyezte a hangsúlyt, a tervezők nem feledkeztek meg a hatékonyságról, illetve a tranzisztorszámról sem. Az A76 ugyanis mindössze 8 darab végrehajtóporttal rendelkezik, amely egyezik az Intel Skylake értékével, az AMD Zentől viszont kettővel, a Samsung M3-tól pedig néggyel marad el. Az A76-ban négy végrehajtó portot találunk az integer műveleteknek (ebből egy elágazás végrehajtás), kettő AGU-t a memóriaműveletek kezelésére, valamint további kettőt a lebegőpontos adatokon és/vagy vektorokon végrehajtandó műveleteknek (VX).
Az A75-höz képest számottevő javulás látható az AArch64 architektúrában található jó néhány utasítás végrehajtási késleltetésében. Az AnandTech összefoglaló táblázatában jól látható, hogy az egyes értékek számos esetben csökkentek, amelynek hála az érintett műveletek kevesebb ciklus alatt futhatnak le. Az ARM kihangsúlyozza, hogy a lebegőpontos FP és ASIMD műveletek esetében is jelentős előrelépést sikerült elérni, például az aritmetikai műveletek végrehajtásának késleltetése harmadával, háromról két ciklusra csökkent. Itt fontos megjegyezni, hogy az FPU immár két 128bites ASIMD vektoros egységből áll, amely dupla végrehajtási sávszélességet jelent az elődökhöz, többek között az A75-höz képest.

Végül, de nem utolsó sorban az adat gyorsítótárak. Az L1 adatcache kapacitása az L1I-jéhez hasonlóan 64 kilobájt, amely relatíve tágasnak számít, ugyanis mind az AMD Zen, mind pedig az Intel Skylake 32 kilobájtos tárral rendelkezik, igaz ezeket a dizájnokat 14 nanométerre tervezték, miközben A76-tal fejlettebb gyártástechnológiákat céloz az ARM. Az L2 cache kapacitása 256 vagy 512 kilobájt lehet, amely bár egyezik az említett AMD és Intel dizájnok értékével, sávszélesség terén jelentős előrelépés hoz az A76. Az elődhöz viszonyítva ugyanis helyenként duplájára nőtt a sávszélesség, miközben a késleltetés is csökkent. Az ARM ezért csak következő generációs gyorsítótár-hierarhiaként emlegeti a gyorsítótárakat együttesét, amelybe beletartozik a legfeljebb 4 megabájtos, exkluzív L3 cache is. A tervezőcég szerint ennek komoly szerepe van abban, hogy az A76 magra épülő processzorok teljesítménye a már többször említett Skylake közelében köthet ki.
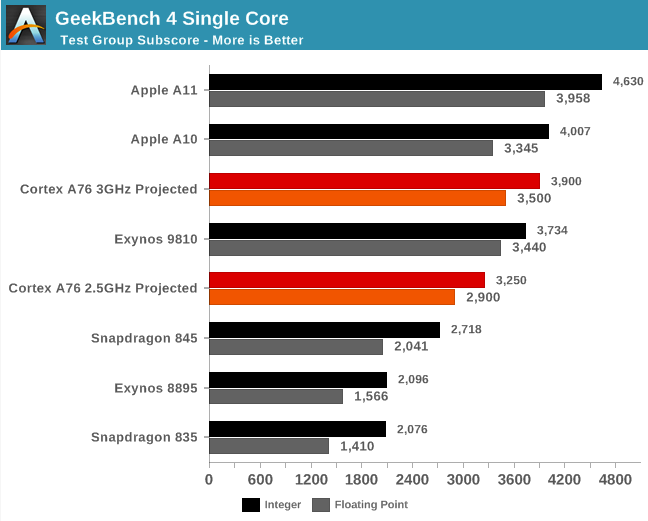
Az ARM ugyanakkor egyelőre csak saját korábbi fejlesztéseihez hasonlította az A76-ot. Ez alapján egészszámos műveletek esetében 25, lebegőpontosoknál pedig 35 százalékkal lehet gyorsabb az A75-höz képest az új fejlesztés, miközben memória-sávszélességben (ebben a cache is benne van) 90 százalékkal lehet jobb az A76. Az ARM saját mérései szerint ez Geekbenchben 28 százalékkal magasabb pontszámot, az ennél lényegesen fontosabb Javascript benchmarkban pedig 35 százalékkal magasabb teljesítményt nyújthat a legújabb mag. A teljes képhez ugyanakkor hozzátartozik, hogy az A76 teljesítményét 3 GHz-es órajel mellett vizsgálta a cég, amely nagyjából 7 százalékkal magasabb az A75 2,8 GHz-es értékénél.

Az AnandTech elemzése a többi ARM-os szereplő processzorával is igyekezett összevetni az A76-öt. Ez alapján a fejlesztés az Apple A10, illetve az Exynos 9810 tempóját hozhatja egyetlen szálon, amely bár acélos, de az Apple A11-től még így is messze van, arról nem is beszélve, hogy a küszöbön áll az A12, amely jó eséllyel már szeptemberben piacra kerül. Az ARM-nak ugyanakkor elsősorban nem az Apple-lel kell birkóznia (amely egyébként katonatiszt módjára fizeti a licencdíjat a tervezőcég utasításarchitektúrája után). Az első számú cél sokkal inkább az x86-os nagy magokhoz való felzárkózás, hisz a mag az ARM üzletpolitikájának megfelelően gyakorlatilag bárki számára elérhető lesz, ergo az A76-ra éppúgy építhet majd processzor a Huawei, mint a MediaTek, vagy a Qualcomm.
Az A76 szilíciumba "öntéséhez" ugyanakkor erősen ajánlott valamilyen élvonalbeli, 7 nanométeres technológia, a relatíve kigyúrt mag ugyanis csak így hozza a 40 százalékkal magasabb számítási tempót 0,75 watt mellett. Utóbbi azért fontos, hisz kettő, vagy akár négy A76-tal, plusz a körítéssel (2-4 A55 mag, buszok, vezérlők, stb.) már könnyen bele lehet futni 4-5 wattba, amely megfelelne az Intel Core M processzorok értékének, 10 nanométerrel pedig az érték értelemszerűen még magasabb lenne.
Azt egyelőre nem tudni pontosan, hogy mikor kerül piacra az első, A76-ot tartalmazó alkalmazásprocesszor, az ARM csupán annyit hintett el, hogy két partner már dolgozik a fejlesztésen, így optimális esetben akár az idei év végén megtörténhet a bemutató. Szélesebb körben azonban várhatóan inkább jövőre, illetve azt követően bukkanhat fel az A76, amelynek teljesítményére elsősorban Windows 10 on ARM alatt vagyunk kíváncsiak. Ez ugyanis megmutatná, hogy a tervezőcégnek mennyivel sikerült közelebb kerülnie a PC-piacot továbbra is szilárdan uraló x86-os megoldásokhoz.