Jönnek az ARM gépi tanuláshoz tervezett IP blokkjai
Bejelentette gépi tanuláshoz tervezett első fejlesztéseit az ARM. Az IP blokkok (szilíciumon implementált áramköri egységek) és az azokhoz készített szoftveres támogatás a Project Trillium keretein belül érkeznek, a brit tervezőcég pedig a jövőben folyamatosan bővíti majd a kínálatot. Első körben egy OD (Object Detection) és egy ML (Machine Learning) processzor érkezik, amelyek az ARM ígérete szerint a CPU-GPU párosánál nagyságrenddel hatékonyabban hajtják végre a gépi tanulásos műveleteket.
Az ML processzort a következtetés (inferencing) gyorsítására szabta a cég. A mikroarchitektúráról egyelőre nem árult el túl sok részletet az ARM, mindössze annyit tudni, hogy a tervezők nagy gondot fordítottak a memóriamenedzsmentre. Ez a gépi tanulásos műveletek hatékony elvégzésnek egyik kulcsa, a végrehajtásra ugyanis jellemző az adat-újrafelhasználás, ezért a ki- és bemenő forgalom (pl. az operatív tár hozzáférések) minimalizálásával jelentősen növelhető a számítási teljesítmény.

Tempó és hatékonyság tekintetében egy fokkal több információt közölt a tervezőcég. Az első ARM ML processzor 4,6 TOPS (Tera Operations Per Second) számítási teljesítmény kínál nyolcbites integer (INT8) műveletek esetében. Mindezt 1,5 watt fogyasztás mellet képes nyújtani a blokk, amennyiben az áramkört a TSMC 7 nanométeres technológiájával öntik szilíciumba. A processzor hatékonysága tehát 3 TOPS/watt, amely érték versenyképes fejlesztésre utal.
Összevetés gyanánt: A tizennyolcmagos Intel Xeon E5-2699 v3 CPU 2,6 TOPS tempóra képes 145 wattos TDP mellett, amely 0,018 TOPS/watt hatékonyságot jelent. Az ARM megoldása papíron még a Google TPU-ját, tehát az ugyancsak gépi tanulásos algoritmusok gyorsításához tervezett ASIC-ot is veri. A processzor ugyanis 1,23 TOPS/wattos mutatóval rendelkezik (92 TOPS, 75 watt TDP), ám a lapkát egy generációkkal régebbi, 28 nanométeres technológiával gyártatja a Google, vélhetően ebből ered a viszonylag nagy különbség.

Az ML processzor jóformán bármilyen ARM dizájnba integrálható. A blokk ACE interfésszel is rendelkezik, így alkalmazható big.LITTLE konfigurációkban, de a cég új irányát képviselő DynamiQ-val is kompatibilis. A tervezőcég hangsúlyozza, hogy legújabb fejlesztésére inkább önálló processzormagként, sem mint gyorsítóként tekint, amely utóbbi az ARM vezetéktanában lényegesen egyszerűbb (pl. hálózati csomagkezelő) áramköröket takar. Az ML processzort valamikor az év közepén kaphatják meg a partnerek, így legkorábban valamikor jövő év első felében érkezhetnek meg az első azt tartalmazó rendszerchipek.

A gépi tanulás mellett az objektumfelismeréshez is dedikált IP blokkal rukkolt elő az ARM. Az OD processzor egy közel két évvel ezelőtti felvásárlásából csírázott. A brit tervezőcég 2016 májusában szerezte meg a londoni székhelyű Apicalt, amely képfeldolgozáshoz kapcsolódó technológiák fejlesztésével foglalkozott. Joggal merülhet fel a kérdés, hogy az ML processzor és a GPU mellett mekkora létjogosultsága van egy dedikált objektumfelismerőnek. Nos, az ARM szerint meglehetősen nagy. Bár az említett áramkörök objektumfelismerésre is képesek, az OD processzor az ilyen műveleteket lényegesen gyorsabban, illetve hatékonyabban hajtja végre, amely például egy akkumulátorról működő okostelefonnál nem elhanyagolható szempont.
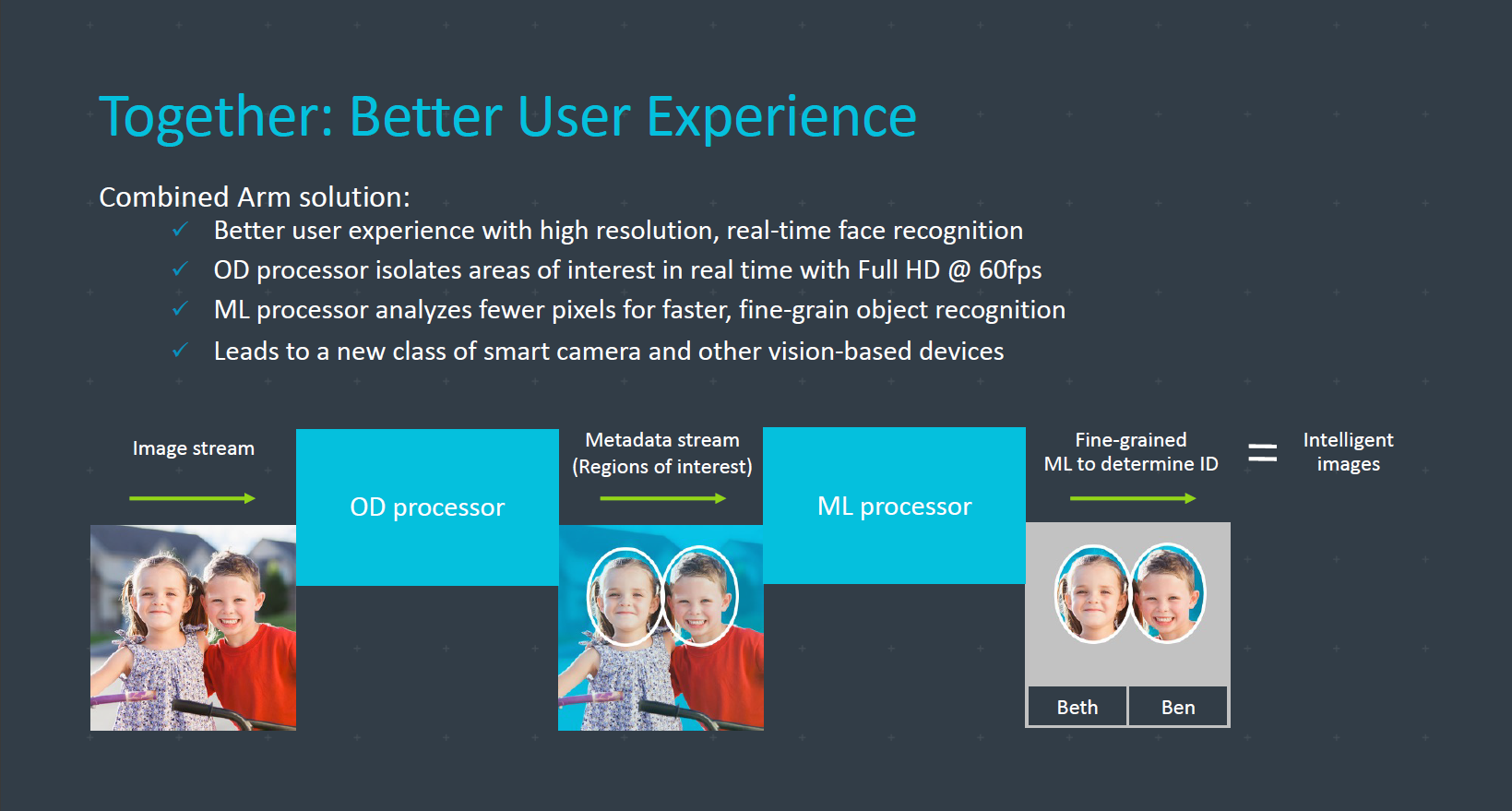
Az ARM szerint az ML és OD processzorok párban nyújthatják a legjobb felhasználói élményt: Utóbbi a sikeres objeketumfelismerést követően továbbítja az ML processzornak az eredményt, amely képes lehet behatárolni az objektumot, például egy arc esetében annak tulajdonosát. A megoldás okostelefonok mellett megfigyelőrendszereknél is kapóra jöhet, ahol bizonyos esetekben kritikus fontosságú a minél gyorsabb végrehajtás. Az OD processzor még ebben a negyedévben piacra kerül.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Végül, de nem utolsó sorban az ARM közölte, hogy a Project Trillium keretében szoftveres támogatást is nyújt a fejlesztőknek, amellyel például neurális hálózati modelljüket különféle keretrendszerekbe (TensorFlow, Caffe, Android NNAPI, stb.) implementálhatják.
Ez csak a kezdet
A rendszerchipekbe épített, gépi tanulásra kihegyezett áramkörök a tavalyi év második felében kezdtek el szivárogni. Elsőként a Kirin 970 állt elő integrált NPU-jával (Neural Processing Unit), amelyet kifejezetten a mesterséges intelligenciával kapcsolatos műveletek gyorsításához tervezett a HiSilicon. A tervezőcég szerint FP16-os, azaz félpontosságú lebegőpontos műveleteknél 1,92 TFLOPs tempóra képes az egység, ami körülbelül háromszor nagyobb, mint amit az előd GPU-ja tett le az asztalra. Ezzel az NPU körülbelül 2000 kép elemzését végzi el a egy perc leforgása alatt, miközben kizárólag CPU-val számoltatva ez a szám csupán 100 körül mozog, önmagában a GPU pedig csak nagyjából 400 fotót képes feldolgozni.
A HiSilicont (Huawei-t) az Apple követte, amely A11 Bionic fantázianevű rendszerchipjébe egy neural engine-t épített. A kétmagos dizájn másodpercenként 600 milliárd (félpontosságú lebegőpontos) műveletet hajthat végre, ami az ML-modellek gyors futtatásához szükséges. Az egység többek között az minél gyorsabb arcfelismerésért felel. A dedikált egységekkel megvalósítható a hatékony, helyben történő végrehajtás, így bizonyos funkciókhoz már nem szükséges felhő, illetve adatkapcsolat.
Ezek alapján a Project Trillium nem számít váratlan húzásnak az ARM-tól. Bár a cég az utóbbi időben igyekezett erősíteni CPU magjai és GPU-i gépi tanulásra (is) használható képességeit, nyilvánvalóan ez csak átmeneti megoldás volt, a dedikált egységekkel ugyanis az általános végrehajtásra tervezett architektúrák nem szállhatnak versenybe. Az ARM új termékeivel megindulhat a gépi tanulásos szolgáltatások szélesebb körű terjedése, pár év múlva valószínűleg a legtöbb okostelefonos rendszerchip szerves része lesz az ML processzor.