Magyar kutató sikere a mellrák deep learninges vizsgálatában
Második helyezést ért el a mellrákos szövetminták elemzését deep learing technológia segítségével megoldó versenyen Lányi Dávid, az IBM Research zürichi laboratóriumának munkatársa, valamint két kutatótársa. A megmérettetésről és a technológia jövőbeli lehetőségeiről a csapat magyar tagjával beszélgettünk.
Az elmúlt 5-8 évben a képfeldolgozás új szintre emelkedett a deep learning technológia elterjedésével, a hibaszázalékok a töredékükre csökkentek a korábbiakhoz képest és egyre nagyobb komplexitású hálózatokhoz használhatóak a megoldások. "Most tartunk ott, hogy egyszerűbb képfelismerési problémáknál a gépek többre képesek" - mondta kérdésünkre Lányi Dávid, az IBM kutatója és deep learninggel foglalkozó PhD hallgató. A megoldás használható például tárgyak vagy forgalmi táblák felismerésére, de akár orvosinformatikai területen is. A jelenlegi képfelismerési eredmények többé-kevésbé már összevethetőek az orvosok vonatkozó munkájával, ezért is váltak jelentőssé az orvosi területhez kapcsolódó versenyek, amelyek a további kutatásokat ösztönzik.
A mellrák kutatás előrehaladását segítette az a tavalyi digitális patológiával foglalkozó verseny, amelynek keretében Lányi Dávid és IBM-es kutatókollégái második helyezést értek el a deep learning technológián alapuló fejlesztésükkel. Az orvosinformatikai MICCAI (Medical Image Computing and Computer Assisted Intervention) konferenciát eddig 19 alkalommal tartotta meg a szervezőbizottság, és ennek keretében írta ki a rangos versenyt, amely tulajdonképpen a különböző kutatólaboratóriumok felkészültségének megmérettetése is - tavaly összesen 159 csapaté volt a világ különböző részeiről. A verseny rendkívül szorosan ért véget, mindössze 0,004 ponttal maradt le a magyar versenyzőt is indító csapat megoldása az első helyezetthez képest, annak ellenére, hogy a megvalósítás módja mindkét esetben nagyon hasonló volt.

A versenyen részt vett IBM kutatócsoport tagjai: Erwan Zerhouni, Maria Gabrani és Lányi Dávid (Forrás: IBM)
Már a kezdetekkor megkapták a versenyzők az adathalmazt, amely ötszáz mellrákos páciens 50 000 x 50 000 pixel felbontású, nagyméretű mikroszkopikus szkennelt szövetmintájának képét tartalmazta. A patológusok gyakran végeznek biopsziát (szövetmintavétel) követően elemzést, hogy megállapítsák a rák előrehaladásának állapotát, illetve melyik terület növekszik leginkább. Ennek során megszámolják hány mitózis keletkezett, mivel a rákos területeken ez sokszorosa a normálisnak, és ez alapján kategorizálják az esetet.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A patológusok 8-10 évig tanulják a folyamatot, majd az elemzést kézzel, egyenként végzik, de a gépi tanulással módszereivel pontosabb és gyorsabb lehetne az eljárás - tudtuk meg Lányi Dávidtól. Így a versenyfeladat az volt, hogy a képeken található mitózisokat kellett lokalizálni, és megállapítani mekkora számban jelennek meg. Ehhez mindössze a formátum és a határidő volt meghatározva, a megadott adatok mellett pedig csak nyilvánosan elérhető adathalmazokat lehetett használni.
Nagy adatmennyiség és nagy bizonytalanság
Egyik legnagyobb problémát az jelentette, hogy nagyon nagy adathalmazzal, több terabájt képpel kellett dolgozni a kutatóknak. Először egy olyan rendszert kellett kialakítani, amely meg tud birkózni ennek a nagyságával, majd az előfeldolgozás lépéseit végezte el a csapat, mint például a képek feldarabolása, színkorrekció, normalizálás, nagyítások egységesítése, vagyis a képminták feldolgozhatóvá tevése a neurális háló számára. Majd kidolgozta Lányiék csapata azt a megoldást, amely képes eldönteni, hogy a képkivágás közepén található-e mitózis, és ezt optimalizálta tovább az idő következő részében.
Egyrészt a tanulókomponens technológiájához az IBM kutatói konvolúciós hálózatot használtak, amely jó módszer a képek és a kétdimenziósan strukturált adatok feldolgozására. A hálózat megtanulja a képfeldolgozó filterek viszonylag nagy halmazát, majd kombinálja őket, és ezek alapján állítja elő predikciót. A másik alkalmazott technológia pedig a reziduális tanulás, amelyet először vettek igénybe ilyen esetben, és ez tette lehetővé a mély hálózatok és a sok réteg egymásra építését.
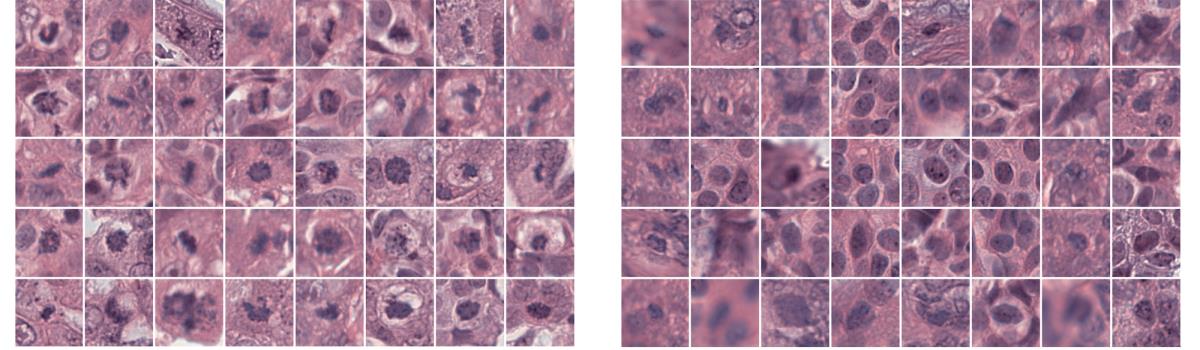
Mitózisok (balra) és nem mitotikus félrevezető minták (jobbra)
A korlátok között jelent még meg az adatnagyság mellett, hogy kevés páciensről állt rendelkezésre információ. Elég nagy számban fordultak elő olyan esetek is, amelyekben az orvosok sem értettek egyet. A megoldásban törekedni kellett annak a kezelésére, hogy a tréninghalmazban sem minden tökéletes - a megoldásnak a bizonytalansággal szemben is robusztusnak kell lennie. Emellett pedig az idő is korlátként jelentkezett, mivel a több hónapost megmérettetés mellett a kutatók két-három másik projekten is folyamatosan dolgoztak a laboratóriumban.
Hajszálnyival csúsztak le az első helyről
A tesztadatok (ground truth) címkézését a szervezők nem tették közzé, csak az eredményhirdetésnél vetették össze a beküldött adatokkal, és így alakult ki a végső rangsor. Az IBM-es csapat a tréningadatokból különített el egy keveset, és a hálózat által nem látott adatokkal optimalizálta a hálózatot, kereszt-validálta az eredményt. "Volt egy becslés mennyire jó a rendszer, de tesztadatokban mindig van olyan, ami nem reprezentált" - tette hozzá a magyar származású deep learning kutató. A végén 0,004 ponttal maradtak le az első helyről, ami a zsűri által használt "F1 mértéknek" a mutatószáma a predikciók és a valós adatok összevetésére.
Kérdésünkre, hogy mi okozhatta az eltérést, Lányi elmondta, hogy a mély tanuló algoritmusban a véletlennek is van szerepe. Közrejátszhatott például, hogy milyen tréningmintán dolgoztak vagy hogyan inicializálták a hálózatot. "Véletlenszerű paraméterekkel van tele a rendszer, közben egyre jobban közelít a célváltozó megállapításához" - foglalta össze a kutató.
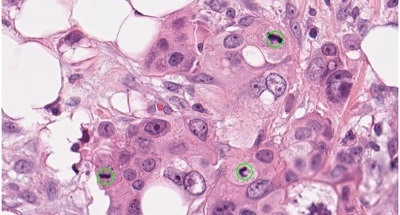
Adathalmazban kapott szövetminta részlete mitózisokkal
A nyertes csapat megoldása egyébként teljesen hasonló volt az IBM-es indulók megoldásához, de a digitális patológia területére specializált startupnak több ideje volt teszteket futtatni különböző bázisokkal. Akik a versenyben mögöttük végeztek, szintén hasonló módszerekkel próbálkoztak, csak kisebb-nagyobb különbségek voltak az adatok összeállításában. A sikert többek közt az jelenthette, hogy Lányiék kiegészítették a tréningmintákat más melldaganatos képekkel is. Az extra adathalmaz plusz dolog, amitől még nagyobb és bonyolultabb lesz a rendszer, mégis nagyon fontos. A "hard negative mining" egy olyan problémaspecifikus technika, amely segít csökkenteni a hibás detektálások számát - a magyar kutató szerint ezeknek a felismerése és alkalmazása adja a sikert, nem feltétlenül csak a technológia.
Nagy a potenciál, de nem cél az orvosok leváltása
Jelenleg a kutatók a futás idejét szeretnék gyorsítani, a prototípusnál igénybe vett képenkénti közel egyórás elemzést fél percre csökkentenék le. A versenyen elért eredmény már közelíti az emberi pontosságot a mitózis detekcióban, de legalábbis minden eddigi módszernél sokkal jobban. A laboratórium folyamatosan együttműködik a kórházakkal, úgyhogy elképzelhető a jövőben a zürichi kórház közreműködése ebben a kutatásban is.
"Nem cél az emberi szakértők kiváltása", szögezte le Lányi, hanem sokkal inkább az orvosok munkáját szeretnék megkönnyíteni a folyamat felgyorsításával és a pontosság növelésével. Az AI-t éppen ezért sokszor "augmented intelligence" értelemben használják, vagyis amely segít kiterjeszteni a szakértők tudását. A termékesítés szoros együttműködésben menne végbe a patológus orvosokkal, a rendszert átalakítanák pilot környezetre és próbálnák kitalálni a legjobb mértéket a munka segítésére. A magyar kutató szerint a kísérleti alkalmazás akár egy év alatt is megvalósulhatna, de az időtáv az IBM startégiájától is függ.

Lányi Dávid az IBM Research zürichi laboratóriumában
Az IBM research célkitűzése a mesterséges intelligencia megoldások fejlesztése, amelynek a deep learning az egyik része, és a kongitív rendszerek elterjesztésében is szeretne a cég előbbre jutni - a későbbiekben akár ez a digitális patológia is az egyik ága lehet majd Watsonnak. A megmérettetés arra volt jó többek közt, hogy az IBM felmérje, megfelelő irányba tartanak-e a fejlesztések és hol állnak a többi vállalathoz, egyetemi kutatócsoporthoz és specializált céghez képest. A verseny alapján úgy tűnik, hogy jól halad a vállalat, mögötte végzett a Microsoft Research, illetve különböző távol-keleti és európai egyetemek, csak egy koreai digitális patológiára specializált startup előzte meg.
Úgyhogy a fejlesztés várhatóan folytatódik a jövőben, főleg, hogy a Lányiék által kidolgozott módszer használható minden olyan esetben, ahol a mitózisok számát kell felismerni, például a prosztatarák elemzésében is. Általánosabban véve pedig a deep learningnek és a képfelismerésnek a mintázatok felismerésében még nagy potenciálja van, ezért az orvosi ipar is kezd lépéseket tenni ebben az irányban. "A deep learning nagyon jól alkalmazható az orvosi képfeldolgozási problémákra. Nem magától értetődő a képfeldolgozás területén, hogy milyen technikára van szükség, ebben jó tapasztalatot jelentett a verseny. Sokat tanultunk arról, hogy milyen specifikus technikák szükségesek az orvosi adatokhoz." - foglalta össze a magyar kutató.
"Az orvosok 8-10 évig tanulják, mi egy nyár alatt raktuk össze"
Arra a kérdésünkre, miért pont a deep learning terület mellett döntött, Lányi Dávid úgy válaszolt, hogy mindig érdekelték az olyan problémák, amelyeket ő nem tud magától megoldani. Erre jó példa, hogy orvosok 8-10 évig tanulják a mitózis detekció folyamatát, míg a kutatócsapat egy nyár alatt rakott össze egy működőképes rendszert a felismeréséhez, specifikus tudás nélkül. "Inspiráló, ahol a gépek példák alapján találják meg, hogyan cselekedjenek adott esetben" - mondta. A szakértő véleménye szerint olyan nagy sebességgel nő az adatmennyiség, hogy a klasszikus algoritmusok nem tudnak lépést tartani vele, ezért a rendszerek inkább a példákból tudnak tanulni.
Ha valaki a deep learning irányában szeretne továbbfejlődni, akkor Lányi javaslata alapján a statisztika, a valószínűségszámítás és a gépi tanulás vonatkozásában kell ismereteket szereznie: "Csak akkor lehet elkezdeni a gépi tanuló rendszer munkáit, ha megvan az általános ismeret" - ez akár online kurzusokon is elsajátítható. A mély tanuláshoz pedig sok szoftvercsomag érhető el, amelyek nem túl drága számítógépeken is futtathatók, és oktatóanyagok is találhatóak hozzá, akár például a konvolúciós hálózattal kapcsolatban is. Azt viszont érdemes még az elején eldönteni, hogy valaki inkább képekkel, szövegekkel vagy hanganyagokkal szeretne foglalkozni.
Egyetemen a matematikai és az informatikai alapképzés is megfelelő lehet, amelyet specifikus mesterképzéssel lehet kiegészíteni. Érdemes az önálló munkákat, szakdolgozatot is közelebb vinni a gyakorlathoz és kihasználni a vállalatok által kínált lehetőségeket. Lányi például az IBM évről-évre kiírt The Great Mind Challenge ösztöndíját nyerte el egyik évben. Már négy éve a zürichi laborban dolgozik, idén év eleje óta főállásban foglalkozik gépi tanulással és a mély tanulással, például Q&A rendszerek és kognitív IT menedzsment projektek kapcsán. Ahogy megfogalmazta: "A gépi tanulás sok helyen alkalmazható, a digitális patológia csak egy a sok közül."