Harci helikopterekkel nyit tüzet az AMD
A professzionális videokártyák után gyorsítós palettáját is megújítja az AMD, igaz egyelőre csak papíron. Az erre tervezett Radeon Instinct sorozat három új taggal debütál, elsősorban a gépi tanulás gyorsításához tervezve.
A Radeon Pro után újabb márkanév és termékpaletta érkezik az AMD-től, amely cég Radeon Instinct termékeivel szeretné megkeseríteni az Nvidia és az Intel dolgát a gyorsítókártyák roppant jövedelmező piacán a vállalat, első sorban a gépi tanulás egyre bővülő területét célozva. A termékek érdekessége, hogy azokból egy modell már a Vega kódnevű GPU-ra épül majd, amelynek (várhatóan) méretes lapkája mellé HBM2 memóriák kerülnek, az AMD esetében először.
A Radeon Instinct sorozat egyes tagjait a hasonlóság ellenére nem katonai helikopterekről nevezte el az AMD, az "MI" a Machine Intelligence rövidítésre, a két betűt követő szám pedig a számítási teljesítményre utal. A sorozat legkisebb tagja az MI6 lesz, mely az idén megjelent egyes Radeonokról (pl. RX 480) már ismert Polaris 10 GPU-ra épül, amely mellé 16 gigabyte GDDR5 memória kerül. A videokártyás rokonságra utal az egyszeres pontosság melletti 5,7 TFLOPS-os tempó, a 224 GB/s-os memória-sávszélesség, illetve a 150 watt körüli TDP érték is.

A középső modellnek számító MI8-ra egy korosodó GPU került, a szerepre ugyanis jobb híján az előző generáció Fiji kódnevű chipjét választotta az AMD, melynek sajátossága, hogy elsőként hozta el a rétegzett, HBM memóriát. A Fijire utal a 8,2 TFLOPS-os számítási teljesítmény és az 512 GB/s-os memória-sávszélesség, na meg a 4 gigabájt kapacitás is, a 175 wattos fogyasztási mutatóval egyetemben. A kártya ezzel meglehetősen hasonlít az R9 Nano asztali videokártyához, a megállapítás pedig a fizikai kialakításra is áll, ugyanis az MI8 egy kompakt, félhosszú megoldás. A rendkívül szűkös memória okán a termék életképessége kérdéses, az MI8 valószínűleg csak nagyon speciális feladatokhoz lehet jó választás, ráadásul a korosodó GPU és a HBM(1) memória okán sem valószínű, hogy túl hosszú karriert fut majd be ez a modell, amit így valószínűleg hamar le fog cserélni az AMD - a megjelenést leginkább az indokolhatja, hogy túl nagy űr lett volna a termékcsaládban az MI8 nélkül.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
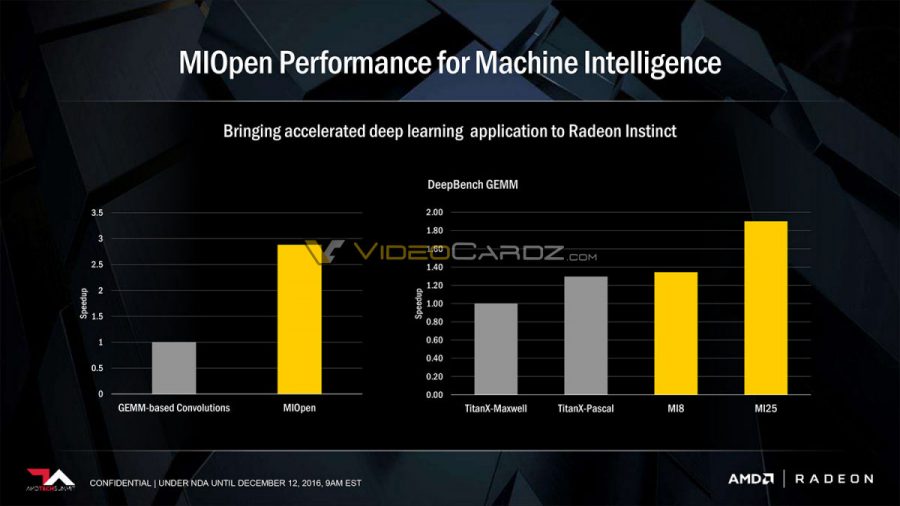
Az igazi újdonságot a nagyágyú MI25 jelenti majd, melyen a vadiúj Vega GPU dolgozik majd. A kiszivárgott információk szerint a processzor félpontosság mellett 25 TFLOPS-os, egyszeres pontosság mellett pedig 12,5 TFLOPS-os tempóra lesz képes, amivel felülmúlná az aktuális csúcstartó Nvidia Tesla P100-at, melynek mutatói rendre 21,2-ben és 10,6 TFLOPS-ban tetőznek. Ennek fényében a kártyát gépi tanulásos rendszerek tréningezéséhez ajánlja az AMD, illetve majd csak fogja, mert egyelőre kézzel fogható termék nincs, a három kártya piaci rajtja csak jövőre lesz esedékes. A tervezőcég ennek ellenére már optimistán közölte saját méréseit, melyek szerint DeepBench GEMM alatt közel 50 százalékkal gyorsabb az az MI25 a Pascal-alapú Titan X-nél, amit (részben) hasonló célokra ajánl az Nvidia.

Az AMD emellett komplett szerverekkel is készül, amely kezdeményezése részben a konkurens Nvidia stratégiáját idézi. A tervezőcég OEM (SuperMicro, Inventec) gyártókkal összefogva komplett, saját Zen-alapú processzoraira épülő szervereket tervezett, SR-IOV hardveres virtualizációval megtámogatva, amitől virtualizált környezetben magasabb hatékonyságot vár a cég.
Az SR-IOV hardveres virtualizációval a PCIe eszköz saját szintjén végzi önmaga virtualizációját, vagyis egyetlen PCIe hardver (például egy videokártya vagy hálózati vezérlő) több PCIe eszköznek látszik a gép felé, így a hypervisor feladatát betöltő szoftver irányában is. Az eszköz particionálását és virtualizációját tehát maga hardver végzi, ezért a hypervisornak már csak a kiosztásokat kell kezelnie, nincs szükség semmilyen, a CPU-t terhelő komplex logikára a hypervisor rétegében, sem driverekre, sem emulációra, sem pedig a virtuális és fizikai erőforrások megfeleltetésére.
A komplett rendszerek 100 vagy 400 TFLOPS-os számítási kapacitással rendelkeznek majd, a legnagyobb, 39U méretűt pedig 120 darab MI25-ös kártyával szerelik fel, amely így 3 PFLOPS-os tempóra lesz képes, amiből 12 darabbal jelen állás szerint el lehetne foglalni a TOP500-as lista második helyét.
Tessék-lássék gyorsítók
A Radeon Instinct gyorsítókártyák, illetve a szerverek megjelenésére a tervek szerint jövő év első felében kerülhet sor, tehát az AMD mostani bejelentése csupán egy paper launch volt, a termékekből egyelőre csak mérnöki mintapéldányok vannak, a végleges verziókhoz még hetek vagy hónapokra van szükség, különösen a legerősebb, MI25-ös modell esetében, amely vadiúj GPU-ra épül. Erre vezethető vissza a szűkös információmennyiség is, a közzétett diákon ugyanis olyan, eddig ismeretlen technológiákra utaló ködös kifejezéseket (pl. NCU, High Bandwidth Cache) használ az AMD, aminek mögöttes tartalmát nem kommunikálja.
Ez több lehetséges okra vezethető vissza, például a vállalat ezzel próbálhatja nyugtatgatni meglévő, illetve potenciális részvényeseit, hogy ők sem maradnak ki az idén jól láthatóan fontossá vált gyorsítós buliból, melynek aktuális hívószava a gépi tanulás. Az AMD ezen a piacon is alaposan le van maradva, hisz a konkurens Intel és Nvidia már az év korábbi szakaszában egymásnak feszült. Utóbbi vállalat a már említett Pascal-alapú termékekkel próbálja horogra akasztani az egyre bővülő vásárlóréteget, az Intel pedig a Knights Landinggel igyekszik megkeseríteni a Teslák életét, korábbi hírek szerint sikerrel. Mindeközben az Intel már kifejezetten a gépi tanulásra kihegyezett termékekkel is készül, a Knights Mill várhatóan jövőre jelenik meg, tehát az AMD-nek iparkodnia kell, ha szeretne egy szabad szemmel is jól látható szeletet a piacból.