Itt az IBM és az Nvidia új, közös fejlesztésű szervere
Elsőként veti be élesben az NVLinket az IBM és az Nvidia. A közös fejlesztés komoly előrelépést hoz, egyes esetekben kétszer gyorsabb az új rendszer.
Bemutatkozott az IBM és az Nvidia új közös HPC szervere, a 2U magas Power Systems S822LC frissített kiadása. Az új kiszolgáló már teljesen kiaknázza az NVLink képességeit - ebben a gépben ölt testet az IBM új POWER-stratégiája és az Nvidia fejlesztései, az új termék egy nagyjából négy éves kooperáció eredménye.

A rendszer IBM POWER8 processzorokat és Nvidia Tesla P100 gyorsítókártyákat egyesít, a kettő közötti kapcsolatot pedig az Nvidia NVLink biztosítja, élesben elsőként. A villámgyors CPU-GPU kapcsolathoz szükséges vezérlőblokkokat mind az IBM processzora, mind pedig az Nvidia tavasszal bejelentett Pascal GP100 GPU-ja integráltan tartalmazza.
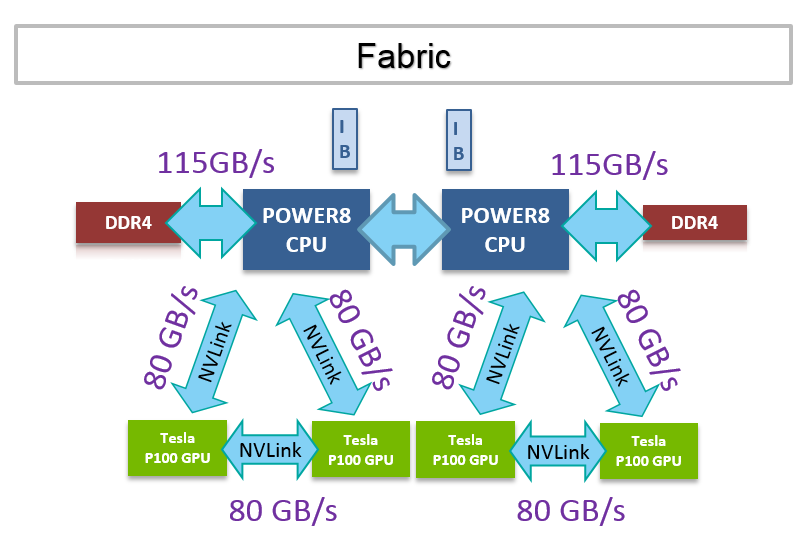
A PCI Express skálázódási problémájára gyógyírként szolgáló, pont-pont kommunikációt biztosító NVLink első verziójából linkenként 40 GB/s-os sávszélesség nyerhető ki, ami bő két és félszer több a 3.0-s PCI Express szabvány értékénél. A GPGPU-s szuperszámítógépek esetében a skálázódás a sarkalatos pont, a CPU-k és a GPU-k, illetve GPU-k és GPU-k közötti kommunikáció, a nagy sávszélesség és az alacsony késleltetés magasabbra tolja a lécet.
Nem csak a nagyobb sávszélesség miatt jelent előnyt az NVLink, hanem szorosabb kapcsolatot is biztosít a processzorok és a GPU-k között. Az összeköttetéssel ugyanis a a chipek NUMA architektúrában hálózatba is rendezhetőek, ezzel egy GPU a rendszerben lévő másik GPU (vagy CPU) memóriájához is hozzáférhet, tehát támogatott az egységes (egységesen címezhető) virtuális memóriát, a CPU-k és GPU-k közös címtérben dolgozhatnak.

Ez jelen esetben négy darab mezzanine csatlakozós, SXM2 formátumú Tesla P100 gyorsító, és két darab tízmagos, 3,26 GHz-es POWER8 CPU között biztosítja a kapcsolatot, utóbbihoz legfeljebb 1 terabájt, DDR4 modulokból kirakható rendszermemória társulhat. A rendszer számítási kapacitása a GPU-knak köszönhetően félpontosságú műveleteknél közel 85, egyszeres pontosság esetében körülbelül 40, dupla pontosság mellett pedig valamivel 20 TFLOPS feletti számítási tempót produkál.
Tavaszi mix a 2025-ös IT pangástól az interjúk evolúciójáig Ezúttal öt IT karrierrel kapcsolatos, érdekes és aktuális témát érintettünk.
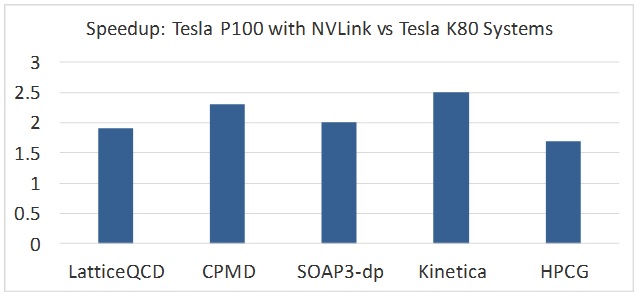
Az IBM néhány mérés erejéig összevetette az új, illetve a korábbi, még PCI Express csatolós Tesla K80 gyorsítókat alkalmazó rendszereket. Az előrelépés tetemes, a szorzó 1,75 és 2,4 között mozog, tehát átlagban nagyjából kétszeres gyorsulást hozott az új Power Systems S822LC.
Ez még mindig csak a kezdet
Eközben a két cég már gőzerővel dolgozik a következő nagy fejlesztésen. Ez a jelentős gyorsulással kecsegtető POWER9-es processzorokat egyesíti majd az Nvidia következő generációs, Volta gyorsítóival az NVLink csatoló következő, 2.0-s verziójával. Utóbbi a gyorsítótár-koherencia mellett tovább növelheti az egyes összekapcsolt processzorok közötti sávszélességet. Az első ilyen rendszerek 2017-2018 környékén érkezhetnek meg.