Tetemes előrelépést hoznak az új Teslák
Komoly előrelépést kínálnak az új Tesla kártyák, a P40 és a P4 helyenként akár 3-4-szer is gyorsabb lehet közvetlen elődeikénél.
Két új Tesla gyorsítót mutatott be a pekingi GTC rendezvényén az Nvidia, a termékek a gépi tanulásra fókuszálnak, amire az Nvidia évek óta kiemelt figyelmet fordít. A Pascal mikroarchitektúrára épülő kártyák a tavaly novemberben bejelentett Maxwell-alapú modellek közvetlen utódjai, azokhoz viszonyítva pedig tetemes előrelépést kínálnak.
Utóbbi részben a Pascal fejlesztéseinek köszönhető. Bár a neurális hálózatokkal kapcsolatos műveletek gyorsítása megfelelően kivitelezhető az egyszeres pontosságú (FP32) lebegőpontos számításokkal, az Nvidia szerint ehhez félpontosságú (FP16) lebegőpontos, de akár 8 bites egészszámos (INT8) műveletek is elengedőek lehetnek. Utóbbihoz az Nvidia módosított a mikroarchitektúrán, így a GP102 és a GP104 GPU egy órajel alatt akár négy egészszámos (INT8) műveletet is elvégezhet egy darab egyszeres pontosságú (FP32) helyett, hasonlóra az előd Maxwell még nem volt felkészítve.

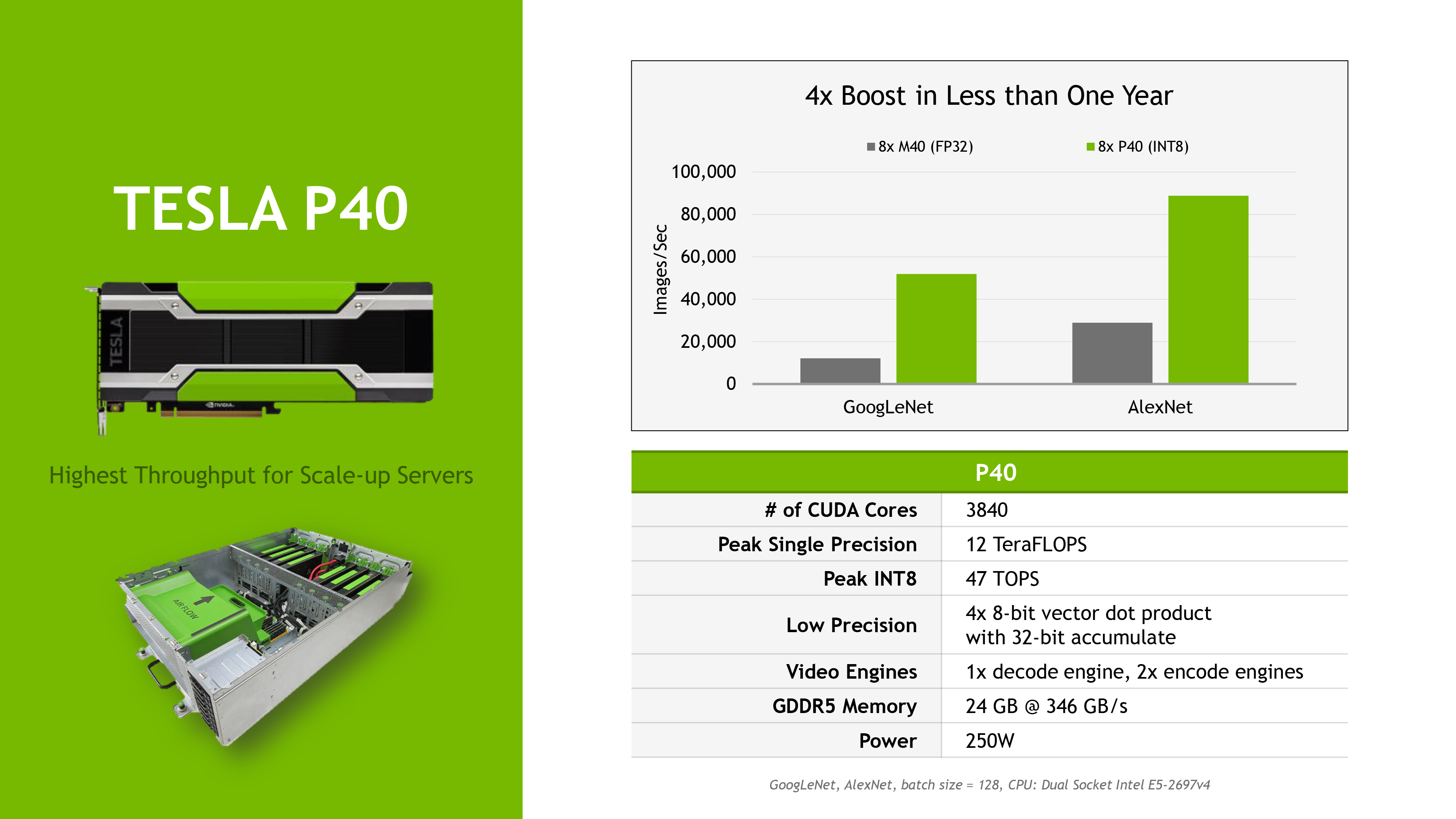
A kártyák az elődökhöz mérten ettől eltekintve is óriási ugrást kínálnak úgy, hogy közben a fogyasztási keret nem változott. A Tesla M40 utódjának tekinthető Tesla P40 25 százalékkal több végrehajtót (CUDA mag), illetve 60 százalékkal magasabb alapórajele kapott, ami az elméleti számítási teljesítmények összevetésében is megmutatkozik. Míg a régi kártya 7, addig az új már 12 TFLOPS-os értékkel rendelkezik, ennél pedig a 47 TOPS-os INT8 kapacitás majdnem pontosan négyszer több. Fontos megjegyezni, hogy ez bizonyos esetekben nem tükrözi jól a gyakorlati teljesítményt, a különbség ennél kevesebb és több is lehet. A P40 24 gigabájt memóriát, illetve 250 wattos TDP keretet kapott.
A low profile formátumú Tesla P4 ennél is nagyobb ugrást kínál, ami mögött az Nvidia kissé meglepő lépése áll. A közvetlen előd M4-en a GM206-os GPU kapott helyet, így arra lehetett számítani, hogy a P4-re a GP106 kerül, a cég viszont végül a nagyobb, GP104-et tette fel a gyorsítóra. Ez 150 százalékkal több végrehajtót jelent, ezek viszont egy kicsivel alacsonyabb órajelet kaptak, alapfrekvenciában a különbség nagyjából 7 százalék. Ezzel együtt a memóriabusz szélessége, illetve a VRAM kapacitása is duplázódott, előbbi már 256 bites, utóbbi pedig 8 gigabájt.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Mindezeknek hála az elméleti számítási tempó is nagyjából 150 százalékot ugrott, ami különösen meggyőző az 50 és 75 között konfigurálható TDP értéket figyelembe véve. A kisebbik modell teljesítmény/fogyasztás mutatója tehát kimagasló, míg az P40 250 watt mellett 47 TOPS INT8 tempót nyújt, addig a P4 ennek alig kevesebb mint a felét, 22 TOPS-t kínál legfeljebb harmad akkora fogyasztásból.
Bár utóbbi egyáltalán nem elhanyagolható, az Nvidia a két kártyát eltérő környezetbe szánja. A Tesla P40 a scale-out rendszerekhez lehet ideális, olyan környezetbe, amelynél nagy teljesítményre van szükség, de nem skálázódik jól több GPU-val. Ezzel szemben a P4 a nagy sűrűségű, scale-up rendszereket célozza, ahol a szoftveres környezet megfelelően profitál a több GPU-s konfigurációból.

Az Nvidia végül az elődhöz viszonyított gyakorlati előrelépésről is beszélt, igaz ebbe a cég már az INT8-as lehetőséget is beleszámolta. Ezzel együtt 3-4-szeres előrelépést mért ki a cég a P40-M40 viszonylatában, P4-M4 relációban pedig hasonló ugrásról beszél az Nvidia a hatékonyságot illetően. A Tesla P40 valamikor októberben kerül piacra, a kisebb, Tesla P4 pedig nagyjából egy hónappal később, novembertől lesz elérhető, az árakról egyelőre nincs publikus információ.