CCIX: új interkonnekt-szabvány készül
Iparági összefogásból jöhet létre egy új, nyílt interkonnekt. A CCIX cache-koherens adatbusz fejlesztésébe az ARM, az AMD, a Huawei, és az IBM mellett a Qualcomm, a Mellanox, valamint a Xilinx is beszállt. A cél egy átjárhatóbb, könnyebben programozható, nagyobb teljesítményű interkonnekt megalkotása.
Új konzorciumot alapított hét neves gyártó, az együttműködés célja egy egységes nagy teljesítményű, nyílt interkonnekt szabvány megalkotása, elsősorban adatközponti használatra. Ez széles(ebb) körű kompatibilitást, illetve átjárhatóságot biztosíthat a különféle CPU-k és gyorsítók között, amivel tovább javítható a rendszerek számítási teljesítménye és hatékonysága. A fejlesztéseket az ARM, az AMD, a Huawei, a IBM, a Qualcomm, a Mellanox és a Xilinx közösen felügyeli majd, a CCIX (Cache Coherent Interconnect for Accelerators) várhatóan valamikor az évtized vége felé jelenhet meg a piacon.
A CCIX egy cache-koherens interkonnekt lesz, az ezzel összekötött CPU-k és különféle gyorsítók (GPU, FPGA, DSP, hálózati processzor, stb.) elérhetik egymás gyorsítótárait és rendszermemóriáit. A processzorok folyamatosan monitorozzák egymás memóriáinak tartalmát, és ha az egyik olyan adatot módosít, ami egy másiknál gyorsítótárazva van, akkor az inkonzisztencia elkerülése végett érvényteleníti az utóbbit. Mindez dióhéjban még egyszerűen hangozhat, de a gyors és stabil interkonnekt kivitelezése hosszú és bonyolult folyamat, amit csak tovább nehezíthet a több eltérő utasításkészlet és gyorsító támogatása.
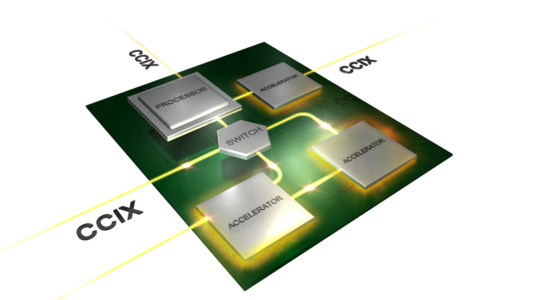
A koherencia mellett az átviteli sebesség és a késleltetés is sarkalatos, ugyanakkor erről egyelőre nem tett említést a bejelentés. A PCI Express busz sem a szűkös sávszélesség, sem pedig a magas késleltetés okán nem alkalmas komolyabb szerveres gyorsítók kiszolgálására, mely problémát már régen felismerték a gyártók, a konzorcium néhány tagja már rendelkezik is ilyen irányú fejlesztéssel.
Az IBM a POWER8-ban mutatta be a CAPI-t (Coherent Accelerator Protocol Interface), az ARM-nek ott a CoreLink CCI-500, az AMD pedig a GMI-t (Global Memory Interconnect) fejleszti. A konzorciumtól távol maradt releváns gyártók szintén rendelkeznek saját megoldásokkal. Az Intel már évek óta használja koherens fejlesztését, a QPI-t (QuickPath Interconnect) még 2008-ban vetette be elsőként a vállalat, amit elsősorban a Xeon processzorok összekapcsolásánál alkalmaz. A cég valószínűleg ugyanezt alkalmazza majd az FPGA-val megspékelt gyorsítóknál is, ami a tavalyi Altera felvásárlásnak köszönhetően kerülhet piacra.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Az együttműködésből ugyancsak hiányzó Nvidia épp a közelmúltban mutatta meg élesben is az NVLinket, ami elsősorban magas, blokkonkénti 40 GB/s-os átviteli sebességével hívja fel magára a figyelmet, bár ez a megoldás koherenciát jelen állás szerint nem támogat. Ennek érdekessége, hogy egyes POWER8 CPU-k beépítve tartalmazzák az NVLink blokkot, tehát az IBM jelenleg több vasat is tart a tűzben, ugyanakkor ez később a CCIX megjelenésével könnyen változhat.
Ismétel a történelem
Nem ez az első iparági összefogás melyben egységes interkonnekt lefektetéséért alapítanak szövetséget neves gyártók. Majd 15 éve hasonló úton indult el a HyperTransport Technology konzorcium, melyben többek között olyan gyártók tömörültek mint az AMD, Apple, Broadcom, Cisco Systems, Nvidia, PMC-Sierra, vagy a Sun. A közösen kifejlesztett HyperTransport számos termékben kapott helyet, a PC-kben elsősorban az AMD és az Nvidia alkalmazta a megoldást - a várt áttörés azonban elmaradt, valódi, széles körben használt iparági szabvánnyá nem tudott válni. A konzorcium 2009-ben már több mint 50 tagot számlált, de a fejlesztések mára elsuvadtak, a HyperTransport 3.1-es verziója óta, azaz nagyjából 6 éve nem adott hírt újdonságról a szövetség.