Itt mentik le az egész internetet
Rendkívül komplex és összetett adatbázis lett mára az Internet Archive. Hogyan működik a legnagyobb digitális könyvtár - és hogy nézett ki a HWSW az induláskor?
Fennállásának huszadik évfordulóját ünnepli idén az Internet Archive. A San Franciscóban székelő non-profit internetes könyvtár küldetése 1996-ban kezdődött, amikor az alapító Brewster Kahle kikiáltotta az intézmény küldetését: egyetemes hozzáférést az összes tudásanyaghoz. Az Internet Archive alapvető célja egyezik a klasszikus könyvtárakéval, azaz megóvni az (online) kulturális örökséget, ezzel párhuzamosan pedig bárki számára hozzáférést biztosítani a múlt különféle internetes tartalmaihoz. Utóbbiba a weboldalak, alkalmazások és játékok, különféle mozgóképek (videók, animált képformátumok), hanganyagok, illetve a szabadon terjeszthető könyvek tartoznak.
A lengyelek az új németek A lengyel informatikát már nyugati mércével kell nézni, mi is így tettünk az 52. kraftie adásban.
Bár az internet mint médium csupán alig több mint két évtizede került be a köztudatba, máris meghatározó történelmi jelentőséggel bír. Ennek okán kiemelten fontos a különféle, digitális formában napvilágot látott anyagok megóvása, mely az internetes archívumok munkája nélkül szinte észrevétlenül tűnhetne el szemünk elől. A szakembereknek nincs könnyű dolguk, hisz a megannyi értékes tartalom mellett nagy mennyiségű virtuális hulladék is kering a hálózaton, a hasznos és haszontalan adatok megkülönböztetése pedig komoly kihívás elé állítja az archívumok üzemeltetőit.
Digitális időutazás
Az Internet Archive legnépszerűbb szolgáltatása a Wayback Machine, mellyel különféle, időközben akár végleg felszámolt weboldalak esetében is visszaugorhatunk a történelemben. A rendszer bizonyos időközönként digitális lenyomatot készít a (majdnem) teljes web tartalmáról, melybe alapértelmezetten a portálok döntő többsége beletartozik.
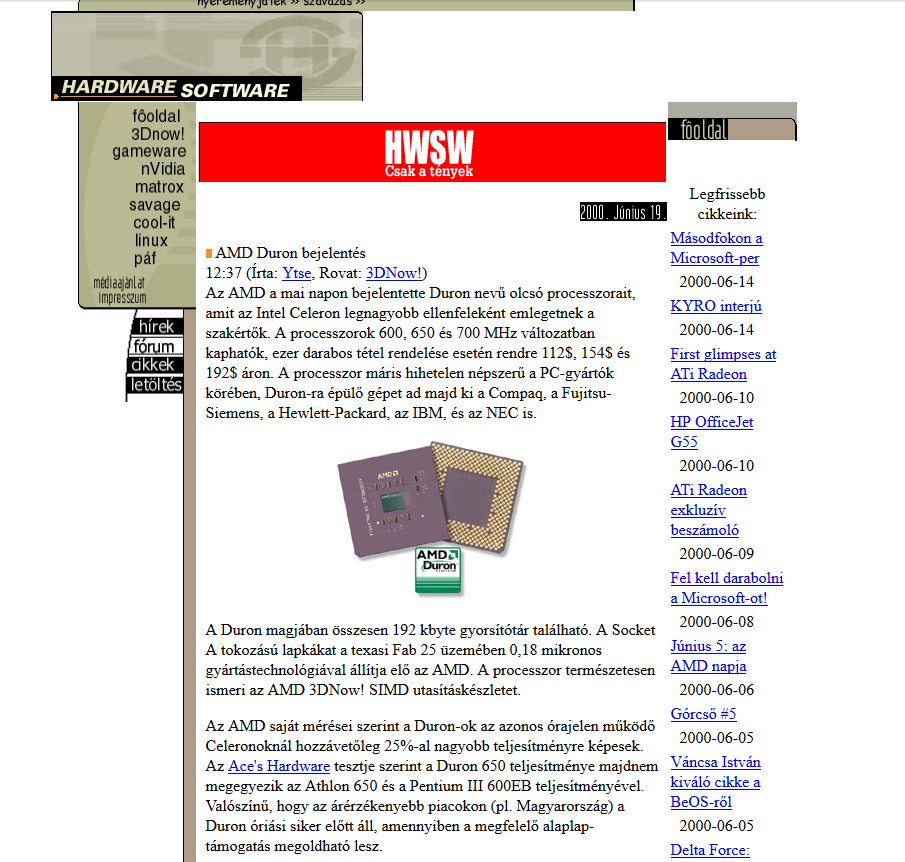
Nagyjából így festett a hwsw.hu az ezredforduló nyarán
Érdekes etikai kérdést vet fel ugyanakkor, hogy milyen (amúgy publikus) információk kerüljenek be az Internet Archive adatbázisába. A keresőcrawlerek (amelyek a publikus tartalom beolvasását végzik) hagyományosan tiszteletben tartják a robots.txt-t, amelyben a weboldal üzemeltetője határozhatja meg a keresés korlátait és az oldal bizonyos elemeit kizárhatja a találatok közül. Hogyan kezelje azonban az Internet Könyvtára az ilyen kivételek listáját?
Az erre adott válasz időben folyamatosan alakult. 2013-ig bezárólag a robotok a szöveges fájl tartalmának megfelelően nem készítettek lenyomatot a kivételként szereplő oldalakról. Ezt követően a könyvtárosok módosítottak a megközelítésen: a crawler a listázott oldalakat is letölti, azokat viszont nem jeleníti meg az Internet Archive nyilvánosan kereshető archívumaiban (például a Wayback Machine-ben), hanem az úgynevezett dark archive része lesz. Ezt a szekciót többek között olyan portálok erősítik mint a Washington Post vagy az USA Today.
Az egyes mentési pontok megjelenéséhez korábban akár 6-18 hónapra is szükség lehetett, ennyi idő kellett, hogy a robotok munkája elérhető legyen az archívumban. Ezen sokat segített a 2013 októberében megjelent a manuális mentési lehetőség, a "Save Page Now" opcióval percek alatt készíthetünk lenyomatot az azt engedélyező oldalakról, ami azonnal bekerül a nagy elektronikus történelemkönyvbe. A digitális lexikon a legutóbbi, 2014-ben közzétett adat szerint nem kevesebb mint 400 milliárd oldalból állt, ami a növekvő tendenciát követve jelenleg már 462 milliárd környékén jár.
Így mentik a mentendőt
Bár a Wayback Machine címsora hasonlít a Google keresőjének beviteli mezőjéhez, a háttérben egy teljesen más elven alapuló rendszer, több komplex adatbázis, illetve számos partner húzódik. Az Internet Archive keresőrobotos (crawler) tevékenysége sokkal inkább hasonlít egy tradicionális könyvtári archívum modelljéhez mintsem egy modern internetes keresőhöz, derül ki a Forbes elemzéséből. Utóbbi egységesített robotokat alkalmaz, melyek azonos szabályok szerint viselkednek, és folyamatosan, 24/7-ben pásztáznak, miközben az összes létező URL-t próbálják azonosítani, végül pedig tartalmukat eltárolni.
Ezzel szemben az Internet Archive rendszere számtalan különálló, illetve jelentősen eltérő adatbázissal operál, melyek egészen különböző metodika szerint építkeznek. Ez logikus - a szervezet más logika mentén tárolja a rendszeresen frissülő és referenciának számító híroldalak tartalmát, és egészen más logika diktálja a teljes internet "lementésére" irányuló erőfeszítést, az így kinyert adatokat pedig más struktúrájú adatbázisokban és más lekérdező felület mögé teszi a Könyvtár. Ennek van párhuzama a fizikai világban is, a nagy könyvtárak könyv-, kézirat- és periodikagyűjteménye, illetve az állami irattárak, archívumok mind-mind eltérő logika mentén végzik az adatok gyűjtését, rendszerezését, tárolását és teszik elérhetővé azokat a közönség számára.

Az Internet Archive 2010 szeptemberében indította el Worldwide Web Crawls nevű, a folyamat szempontjából szintén nagy jelentőségű programját, mely weboldalakat, illetve azok egyes részeit gyűjti be. A Hetrix szoftverén alapuló robotok egy vagy több, URL címeket tartalmazó úgynevezett seed listákból indulnak ki, melyeket többek között olyan szabályok alapján definiálnak mint az URL maximális mélysége. A legtöbb oldalt egy futtatás során csupán egyszer húz be a Worldwide Web Crawls, ugyanakkor a rendszeresen frissülő, például hírekkel foglalkozó portálok esetében sűrűbben végez mentést a robotszkenner.
A szintén házon belüli No More 404 olyan népszerű oldalakat pásztáz kiemelt prioritás mellett mint a Wikipedia vagy a WordPress, illetve a GDELT Project. Az utóbbi egy naponta frissített listát tartalmaz a világot behálózó fontosabb hírportálok URL címéről, amivel az Internet Archive könnyedén eltárolhatja az év összes napjának hírértékű eseményeit.
Az Internet Archive munkájához számos partner is nagyban hozzájárul. A listán többek között olyan nevek vannak mint a Sloan Foundation, a NARA, az Internet Memory Foundation, vagy a Common Crawl, amihez még egy nagyjából 2,5 milliárd bejegyzéses DNS könyvtár is hozzájön. Ezen felül olyan már megszűnt közösségek hagyatéka is az Internet Archive birtokában van mint a Wretch, vagy az egykor nagyon népszerű GeoCities, ezeket a könyvtár adományként kapta meg.
Szintén adomány az Alexa crawling adatbázisa, amelyet a cég rendszeresen átad az Internet Archive-nak tárolásra és feldolgozásra. Az ismert Alexa Internet nevű rangsoroló a kezdetek óta nagy mennyiségben szolgáltat adatokat az archívum számára, melyből többek között az oldalak látogatottsága is kiderül, ami az archiválás szempontjából nagy fontossággal bír. (A támogatás annak fényében nem meglepő, hogy az Alexát ugyanaz a Brewster Kahle alapította, aki az Internet Archive-ot is.) Az Alexa által szolgáltatott adatok azért is fontosak, mert míg az archívum saját robotjai elsősorban több független oldalon gyakran hivatkozott linkeken pásztáznak, addig az Alexa egy más, nem publikus módszert alkalmaz, mely többek között az Alexa Toolbaron megadott adatokból (pl. webcím) tájékozódik.
A végeredmény több különböző forrásból és technikával összeállított, jelenleg valamivel több mint 7000 gyűjteményből tevődik össze, az ezekben található összes tétel pedig körülbelül 4,1 milliót számlál. Ezek egy része a nem publikus, úgynevezett dark archive szekciót gazdagítja, mely a Wayback Machine-en keresztül nem elérhető, aminek oka például érvényben lévő embargó, vagy licencmegállapodás lehet.
A népszerű Wayback Machine csupán a jéghegy csúcsa. A huszadik születésnapját betöltött Internet Archive legfőbb célja a 21. század tömegkommunikációs médiumának konzerválása, mely feladat olykor sokkal nagyobb kihívást jelent mint a nyomtatott vagy írott anyagok rendszerezése, illetve tárolása. Az összesen nagyjából 300 alkalmazottat foglalkozó non-profit internetes könyvtár mindössze évi 10 millió dollárból gazdálkodhat, melynek egy része felhasználói adományokból származik.