Számos fejlesztést hozott a HANA új szervizcsomagja
Az SPS 11-gyel elérhetővé vált a régóta kért hot standby, így jelentősen gyorsult a failover.
Kiadata az esedékes féléves frissítést a HANA-hoz az SAP, a 11-es szervizcsomag pedig az eddig megszokottakhoz hasonlóan messze nem csak biztonsági javításokat, hanem funkcionális fejlesztéseket is tartalmaz. Az SPS 11 újdonságairól Daniel Schneiss fejlesztési vezetővel beszélgettünk a frankfurti HANA Forumon.
Schneiss szerint a legfontosabb fejlesztés a hot standby funkció, ami már régóta a vevői kívánságlista tetején szerepelt. Ezáltal az elsődleges és a másodlagos adatbázis között szinkron módon történik a replikáció, üzemzavar esetén a failover egy teljesen friss adatbázisra történhet, egy percnél kevesebb idő alatt. Az új szervizcsomag a visszaállítási időt is lerövidítette, a folyamat a hiba bekövetkezésétől, nem pedig az egész adatbázisra fut le.
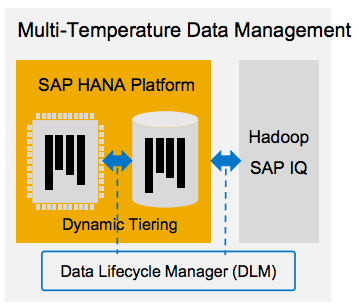
Megjelent a Data Lifecycle Management lehetősége, ami lényegében egy szabályalapú dinamikus adattiering funkció, és batch-alapú végrehajtással mozgatja az adatokat a memória és az egyéb lassabb tárolók (például lokális háttértárak, Hadoop-klaszterek). Az új kiadásba természetesen bekerült a nemrég bemutatott Vora támogatása is, valamint ezentúl geolokációs adatok alapján is lehet klaszterezni az adatokat – az ezeket tartalmazó táblákat pedig particionálni is lehet. Javult a 10-es csomaggal bevezetett terhelésmenedzsment, feladattípusonként szabályozható a CPU-használat mértéke. A fejlesztők szerkezetileg leválasztották az alkalmazáskiszolgálói részt az adatbázis-szolgáltatásokról, így hatékonyabban, külön-külön is lehet skálázni, ha szükség lenne rá.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Jelentősen bővült a külsős fejlesztésekhez használható nyelvek száma, az SPS 11 a Node.js, a Java és a C++ használatára is lehetőséget biztosít. A fejlesztők számára további jó hír, hogy végre a nagyobb kódmenedzsment-eszközöket (Git, GitHub, Maven) is igénybe vehetik.
A HANA immár több mint 70 előre csomagolt algoritmust tartalmaz az adatfeldolgozásra, közülük számos valós időben streamelt adatfolyamon is használható (akár prediktív módban is), és működésük utólag gépi tanulással automatikusan finomítható. A 11-es HANA-ba bekerült a magyar és a román nyelv teljeskörű elemzése, az analitikai motor pedig az egyes szavak közötti nyelvtani kapcsolat (például alany-állítmány-tárgy) felismerésére is képes.
A jövővel kapcsolatban Schneiss elmondta, hogy a fejlesztés fő irányát az elosztott adatbázis-szemlélet határozza meg, az SAP fő célja a HANA-val a legjobb összevont (de globálisan fizikailag különböző adatközpontokban hosztolt adatbázisokkal dolgozó), valós idejű analitikai megoldás létrehozása. Ezt egyébként a jelenleg még mindig nagyon változó adatvédelmi követelmények is indokolják, olyan megvalósításra van szükség, mely képes úgy elvégezni hatalmas elosztott adatbázisokon az elemzéseket, hogy az adatok nem hagyják el a törvények által szabott földrajzi határokat.