Intel Omni-Path: az interkonnekt a lapka része lesz
Az elmúlt hetekben számos részletet árult el az Intel a tavaly eredetileg Omni Scale néven bejelentett HPC interkonnekt technológiájáról. A végleges nevén Intel Omni-Path-ra keresztelt interfész nagy ugrás lesz a korábbi True Scale-hez (InfiniBand) képest, és 2015 utolsó negyedévében kerülhet éles bevetésre.
Az Intel először tavaly nyáron, a mostani Xeon Phi generáció (Knights Corner) utódja, a Knights Landing bejelentésekor beszélt nagyon szűkszavúan az új processzorgenerációval párhuzamosan fejlesztett interkonnekt-technológiájáról. Az akkor még Omni Scale-nek hívott új hálózati interfészről a vállalat szinte semmit nem árult el azon kívül, hogy az gyorsabb, megbízhatóbb és jobban skálázható lesz mint a True Scale (az Intel saját márkanév alatt futó InfiniBand implementációja), valamint szándékai szerint az interkonnekt vezérlőjét magára a Xeon Phi (és később a sima Xeon) lapkákra integrálja.
Közeledik azonban a 14 nanométeres csíkszélességű Knights Landing Xeon Phi processzorok és így az Omni-Path Architecture (OPA) 2015 utolsó negyedévére tervezett debütálása, így a vállalat idei fejlesztői konferenciáján és a Hot Interconnects szakmai konferencián több fontos műszaki részletről is lerántotta a leplet. Az Intel még 2012-ben vásárolta fel a Cray Aries interkonnekt technológiát fejlesztő részlegét valamint a QLogic Infiniband üzletágát az így megszerzett szellemi tulajdon és saját kutatás-fejlesztési eredményeinek kombinációja alkotja a portonként akár 100 Gbps sávszélességre is képes Omni-Path alapjait.
A True Scale-hez képest az egyik legfontosabb változás a már említett magas fokú integráció megvalósítása. Ez annyit tesz, hogy az első körben megjelenő Knights Landing lapkákra az Intel MCM (multi-chip module) megközelítésben a processzor mellé tokozza az Omni-Path vezérlőt, később pedig a gyártó a teljes integrációt megvalósítja. Az Intel a jelenleg kapható Xeon Phi generációtól eltérően a Knights Landinget nem bővítőkártyaként, hanem processzorfoglalatba illeszthető termékként fogja piacra dobni.
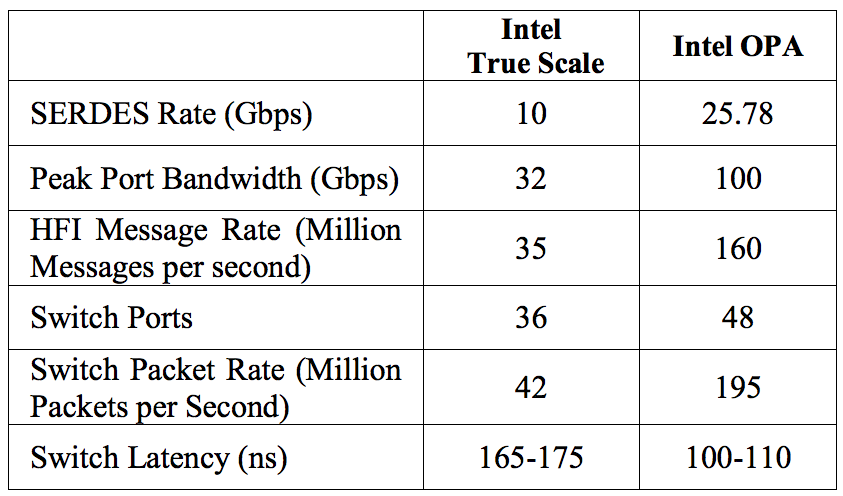
Ígéretes specifikációkat mutat az OPA.
Persze az Intel továbbra is kínálni fog különálló hálózati vezérlőket is, és a vállalat vadonatúj 24 és 48 portos switch-eket valamint egy legfeljebb 192 illetve 768 portos kapcsolót is bejelentett. Ezek kétirányú, elméleti maximális sávszélessége lenyűgöző, a nagyobb, 20U magas modell 19,2 Tbps-et kínál. Az Omni Scale esetében egy switch legfeljebb 36 portot támogatott, így az Omni-Path-szal egy nagyobb méretű HPC kiépítés esetében jelentősen csökkenthető az egyes node-ok közötti maximális ugrások száma.

Az Intel a forgalomoptimalizálás és a hibajavítás hatékonyságának emelése érdekében eltért a hagyományos hétrétegű OSI-referenciamodelltől, és a rétegek közé egy másfelediknek vagy Link Transfernek (LT) hívott réteget illesztett be. Az OPA-ban a nagyobb, node-node közötti, úgynevezett Fabric Packet csomagokat a vezérlő 64 bitnyi Flow Control Digits (FLIT) egységekre bontja, ezek számítanak az OPA legkisebb adategységeinek. Tizenhat FLIT-ből, 16 típusbitből (FLIT-enként egy), 14 hibajavító (CRC) bitből és 2 Virtual Lane (VL, virtuális sáv) bitből összeáll egy fix, összesen 1056 bit méretű Link Transfer Packet (LTP).
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Egy LTP-ben tehát 64 bájtnyi hasznos adat utazik (a többi modern hálózati megoldáshoz hasonlóan 64B/66B kódolással, a 3,125 százalékos overhead biztosítja a Link Transfer rétegen a megbízhatóságot), de az ezt a tömböt alkotó FLIT-ek akár különböző, a fentebb már említett módon a legnagyobb csomagnak számító FP-kből származhatnak. (A méretsorrend tehát a legkisebbtől a legnagyobbig: FLIT, LTP, FP). Az OPA-vezérlő tehát végeredményben a FLIT-ek szintjén szervezi a forgalmat, így akár 65 bitenként belenyúlhat abba a "szülő" LTP prioritási besorolás alapján – ebből legfeljebb 31 lehet (plusz egy vezérlősáv).
Ha a küldő node hibajelzést kap a fogadó féltől, az OPA csomagintegritás-védelme újraküldési kérelmet küld a hibás LTP sorszámával. Érdemes kihangsúlyozni, hogy újraküldés esetén tehát nem az egész csomag (FP), hanem annak csak egy jóval kisebb része, az adott 1056 bites LTP kerül újraküldésre, így kisebb időre okozva fennakadást a normális forgalmi rendben.
A biztonságot és a forgalomoptimalizálást szolgálja a csoport- és feladatalapú hálózatparticionálás is. Az OPA ezt az adatkapcsolati rétegen valósítja meg, és minden FP-t társít egy meghatározott partícióval. Az egy partícióba tartozó végpontok egymással kommunikálhatnak, de az azon kívül eső végpontokkal nem. A végpontok teljes vagy korlátozott besorolású tagok lehetnek, előbbiek a partíció minden tagjával kommunikálhatnak, utóbbiak viszont csak a teljes jogúakkal. Ez csoporton belül az erőforrásmegosztást és az izolációt egyaránt lehetővé teszi.
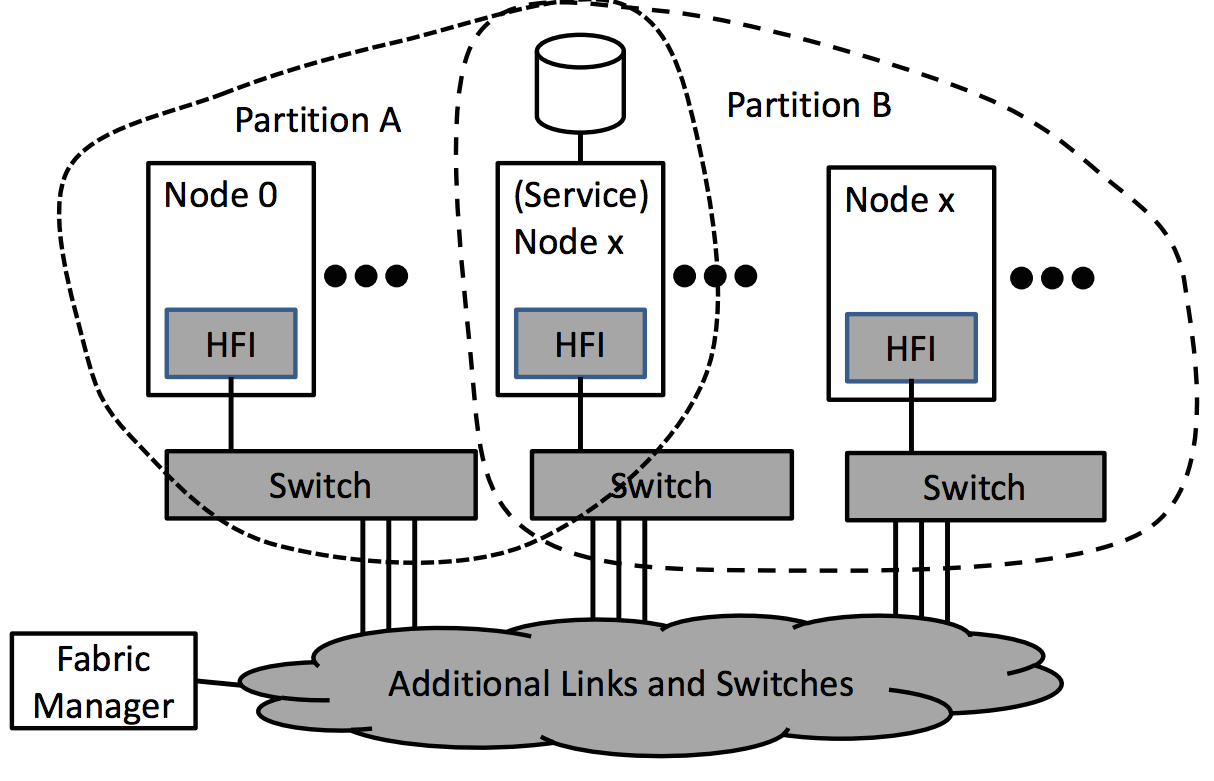
Fontos, hogy egy OPA-hálózat minden végpontja tagja legalább a Fabric Manager által vezérelt menedzsmentpartíciónak, ezen felül pedig akár több partícióba is besorolható. Az Intel egyébként az OPA-ban lehetővé tette a 24 bites címek használatát, így akár 16,7 millió (!) végpontból álló rendszerekig is skálázható az új interkonnekt.
Az Intel szerint az első OPA-alapú rendszerek az év utolsó negyedévében állhatnak szolgálatba, a szélesebb körű piaci bevezetésre pedig 2016 első felében kerülhet sor – az egyik legnagyobb szövetséges a HP lesz. A még mélyebb műszaki részletek iránt érdeklődőknek az Omni-Path műszaki dokumentációját érdemes áttanulmányozni.