Új memóriaalapú lekérdezési motor az SAP-tól
A HANA Vora a vállalati rendszereket hozná össze a Hadooppal, az Apache Spark keretrendszerre építve.
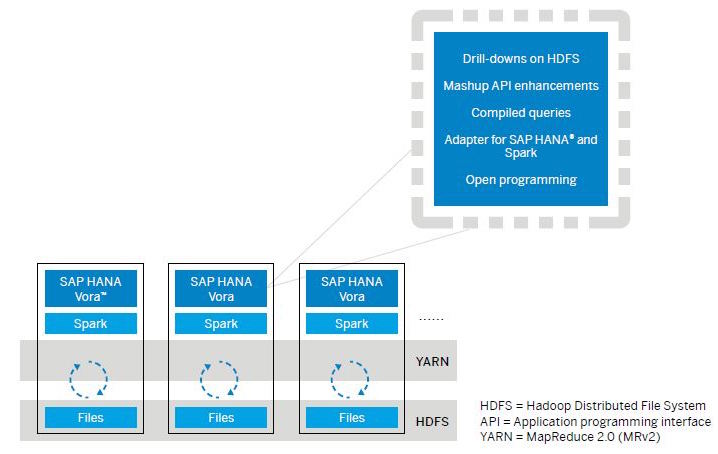
HANA Vora néven memóriaalapú lekérdezési motort mutatott be az SAP, mellyel nagy mennyiségű, strukturálatlan adatforrást is bevon az OLAP (online analytical processing) típusú adatfeldolgozásba. A Vora az egyik legnépszerűbb Big Data keretrendszerre, az Apache Sparkra épít - azért, mert a Spark mára iparági szinten elfogadott adatfeldolgozási keretrendszer, és ebből adódóan big data típusú adatfeldolgozásban jártas szakemberek (adattudósok, programozók) számára megtartja az ismerős környezetet. Ráadásul a Spark az alapoktól kezdve elsősorban memóriaalapú feldolgozásra született, így ebből a szempontból is célszerű választás volt a szintén erre az alapelvre építő HANA mellé.
A Vorával a vállalat a céges rendszerek strukturált adatait valamint a strukturálatlan, elosztott adatbázisokat (közösségi médiából nyert információk, szenzorok és egyéb IoT eszközök által begyűjtött adatok stb.) hozza össze egy egységesen, közös felületről elemezhető és lekérdezhető poolba. Az eszköz természetesen együttműködik a HANA-val is (erről egy YARN-alapú Spark-HANA adapter gondoskodik), de az nem feltétele a Vora használatának. Az SAP a Hortonworks Hadoop disztribúcióját ajánlja a Vora/Spark mellé, ami nem meglepő, hiszen a vállalat két éve ennek viszonteladója is.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A Spark miatt az API keretrendszer nyílt, a szakemberek Spark R vagy ML nyelvet használhatnak az adatbázisok közötti kapcsolat kialakítására. A Vora számos egyéb nyelvet is támogat (C, C++, Java, Python, Scala, R), ha felhasználói saját fejlesztésű eszközökkel szeretnék kiegészíteni. Nincs szüksége dedikált hardverre, a Spark/Hadoop node-okon él, és on-premise valamint szolgáltatásként elérhető változata is van. Bár a Vora alatt szolgáló Spark és Hadoop is nyílt forrású projektek, az SAP fejlesztése nem az – a vállalat elérhetővé tesz majd egy fejlesztőknek szóló ingyenes változatot az Amazon felhőjében (AWS), de azt éles üzleti környezetben nem lehet majd jogszerűen használni.
Berczik Márton, az SAP hazai szakértője kérdésünkre elmondta, hogy a Vorában a riportokat drag and drop módon, programozás nélkül lehet összeállítani (persze miután az adatforrások közötti kapcsolatokat a szakemberek már létrehozták). Mindez azonban nem azt jelenti, hogy az eszközt a vállalat az átlagfelhasználóknak szánja – a célközönséget azok az adattudósok, adatbázisszakértők adják, akik ismerik, értik az adatokat és az összefüggéseket. A jelenlegi analitikai minták korábbi, általánosítható ügyfélprojektek eredményei, de Berczik szerint nem determinálják a későbbi alkalmazási módszert.
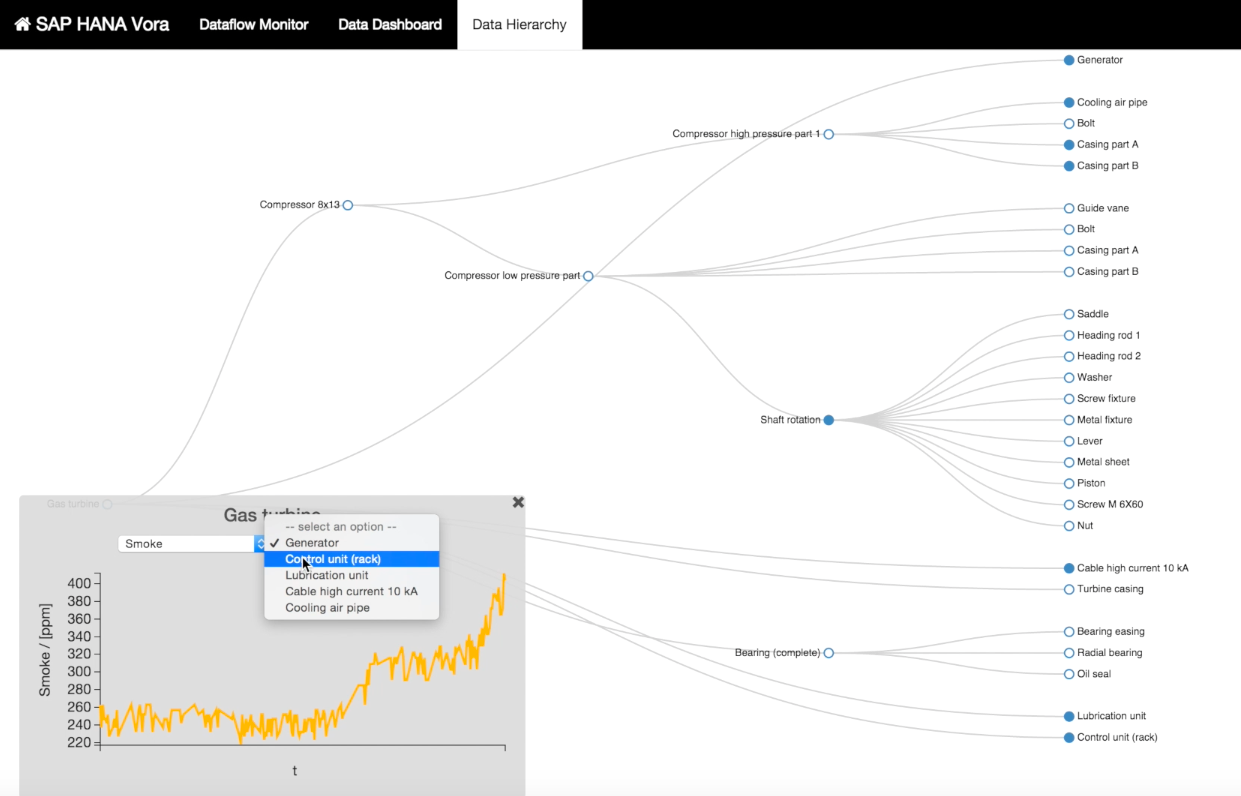
A szakember alkalmazási területként a csalásdetektálást (például pénzügyi szektorban), a kockázatelemzést, a helyzetszimulációt, közművek esetében a karbantartási előrejelzést és az eszközkihasználást, a telekommunikációs szektorban pedig a hálózati kapacitásszervezést emelte ki. Ezek mellett hasznos lehet az úgynevezett smart grid rendszerű erőművekben, a SCADA rendszerek által gyűjtött adatok elemzésében és az egészségügyben is (mint például a magyar Pulzus projekt).