Pedzegeti a Pascalt az Nvidia
Rétegzett RAM, FinFET tranzisztorok, fantasztikus sávszélesség - több fontos innovációval érkezik a Pascal, az Nvidia következő GPU-generációja.
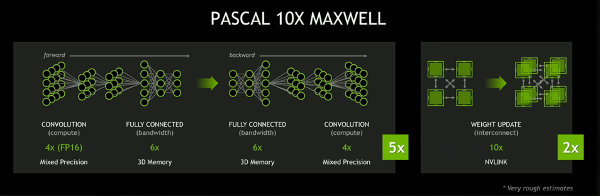
A Pascal architektúra nyers teljesítményadatai igen ígéretesek, a cég állítása szerint vegyes pontosságú feldolgozásban akár négyszeres sebességnövekedés is elérhető a Maxwell generációhoz képet, miközben a fogyasztás-teljesítmény mutató felére esik, a támogatott memória mérete 2,7-szer, sávszélessége pedig háromszor akkora lesz. A cég azt is közölte, hogy jelenleg két Pascal-alapú mag készül, a PK104 és a PK100. Előbbi a GM204-et váltja a cég kínálatában, míg a PK100 a csúcsmodell szerepét látja majd el.
Mindkét chip FinFET technológiával készül majd, 14 vagy 16 nanométeres eljáráson. Ez utóbbi jelenti igazából a hírértéket, az Nvidia és az AMD is évek óta 28 nanométeren ragadt a GPU-kat illetően, mivel a kisebb csíkszélességű eljárásból a bérgyártó partnerek nem készítettek nagy teljesítményre optimalizált gyártástechnológiát. Ez azonban a következő generációval változik, így a vásárlók újra élvezhetik a csíkszélesség csökkenésének előnyeit, a magasabb tranzisztorszámot és jobb fogyasztási karakterisztikát. Arról az Nvidia egyelőre mélyen hallgat, hogy mely gyártónál készülnek majd a Pascal-féle GPU-k, a cég azonban kijelentette, hogy "elsődleges partnere" 16 és 10 nanométeren is a tajvani TSMC lesz.
A sebességnövekedésben nagyon fontos szerepe lesz a vadonatúj memória-alrendszernek, amely a cég ígérete szerint akár 32 gigabájt grafikus RAM-ot és 1 terabites sávszélességet is elérheti. Ez hagyományos megoldásokkal nem érhető el, itt már szükség van az új HBM (high bandwith memory) technológiára, amely a GPU-t és a memóriamodulokat egymásra rétegzi, a magas integráció révén pedig kompaktabb kialakítás és nagyobb sebesség érhető el.

Így kell elképzelni a szilíciummagokat "átütő" vezetékezést.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A GPU a memóriamodulokkal TSV (thru silicon via) összeköttetésen keresztül kapcsolódik. Ez az egymásra rétegzett lapkák belsején végigfutó vezetékeket jelenti, amely a gyártást bonyolítja (értsd: drágítja), viszont hatalmas kapacitást és sávszélességet tesz elérhetővé. Hasonló technológiát fog használni az AMD következő generációs GPU-ja is, az Intel pedig már 2014-ben bejelentette, hogy Knights Landing chipjeit ilyen módszerrel készíti.