Itt az új Nvidia mobilprocesszor
Tovább próbálkozik a mobilos piacon az Nvidia, a Tegra hatodik generációját az ARM 64 bites processzormagjaira, de saját GPU-ra építette - kényszerűségből. A kitörési pont a grafika lehet, miután idén minden csúcslapka ugyanazt a CPU-t használja.
Meglepetésre az Nvidia is kudarcot vallott a versenyképes 64 bites processzormagok 20 nanométeres gyártásával és az ARM-tól kért kölcsön, a Qualcommhoz hasonlóan. A vadonatúj Tegra X1, kódnevén Erista azonban ettől függetlenül látványos előrelépés az előző Tegrákhoz és a versenytársakhoz képest is, különösen a grafikus egység nyers ereje lenyűgöző.
Tegra, megint Cortexekkel
Szögezzük le előre, az Erista egy vészmegoldás. Az Nvidia általában két évre előre közli a termékterveket, az Erista azonban csak egy évvel ezelőtt jelent meg ezekben a tervekben az eredetileg tervezett Parker lapka helyén. Az Eristával ugyanis az Nvidia most mellőzte a saját fejlesztésű, vadonatúj Denver processzormagokat, helyettük újra az ARM-tól licencelt Cortex egységekre esett a cég választása. Az Eristában az ARM Inc. legújabb fejlesztései, a Cortex-A57 és Cortex-A53 magok dolgoznak, négy-négy magos klaszterekbe rendezve. A klaszterek összekötésére használt megoldás már az Nvidia saját fejlesztése, nem az ARM által szállított CCI-400. Az egyedi fejlesztésű interconnect lehetővé teszi a globális ütemező használatát, amely az operációs rendszer és az alkalmazások felé egységesen osztja ki a nyolc mag teljesítményét.
Az ARM-féle interconnect cache-koherenciát csak a klasztereken belül biztosít, ha egy alkalmazás futása egyik klaszterből átkerül a másikba, az jelentős (ideiglenes) teljesítményesést jelentett. Az Erista esetében mind a nyolc processzormag azonos kontextussal dolgozik, a magok közötti váltás így lényegesen gyorsabb, ami magasabb rendszerszintű sebességet is jelent, ahogy az alkalmazáskontextust nem kell klaszterek között migrálni a teljesítményigény változásával.
A lapka a TSMC vadonatúj 20 nanométeres eljárásán készül, eddig ezt a technológiát csak az iPhone 6-ban dolgozó Apple chipek kapták meg. Részben ez a ragyogó teljesítmény/fogyasztás karakterisztikával bíró technológia az oka, hogy az Erista lényegesen jobban viselkedik, mint a Samsung Exynos 5433, amely ugyanezt a két CPU-klasztert implementálja, az ARM-féle interconnecttel, a Samsung saját eljárásán. Az Nvidia adatai szerint azonos teljesítmény mellett az Erista fele annyit fogyaszt, mint a koreai csúcslapka, azonos fogyasztás mellett pedig 1,4-szeres teljesítményt tud leadni. Az interconnect és az eltérő eljárás mellett ebben szerepet játszhat az eltérő energiamenedzsment is - míg az Erista az Nvidia saját System EDP vezérlőmodulját használja, a Samsung ezt is az ARM-tól licenceli.
A felépítésből tehát jól látszik, hogy az Nvidiánál a processzornak gyakorlatilag minden eleme készen állt - csak a processzormagok tekintetében kényszerült külső szállítóra fanyalodnia a cégnek. Egyelőre nem világos, hogy milyen problémák akadtak a Denverrel, sejtésünk szerint a TSMC 20 nanométeres eljárására történő optimalizálás okozott komoly fennakadást, a vadonatúj technológiával még nincs sok tapasztalata a gyártónak. Mivel az ARM-TSMC együttműködésnek köszönhetően ezt a munkát a Cortexek esetében mások már elvégezték, a 20 nanométeres Cortexek készen megvásárolhatóak, a cég egyszerűen beemelte ezeket a magokat a sajátja helyére.
Ezt erősíti meg az Nvidia is, a cég illetékesei az Anandtechnek elmondták, hogy a piaci bevezetést nagyon eltolta volna a Denver magok használata, ezért került be végül a licencelt szellemi tulajdon a processzorba. A teljes processzort átállítani egy külső tervezésű processzormagra ugyanis elképesztően nagy feladat, ha az Nvidia erre kényszerült, akkor a 20 nanométeres Denverrel valóban nagyon súlyos problémák lehettek.
Asztali GPU - mobilban
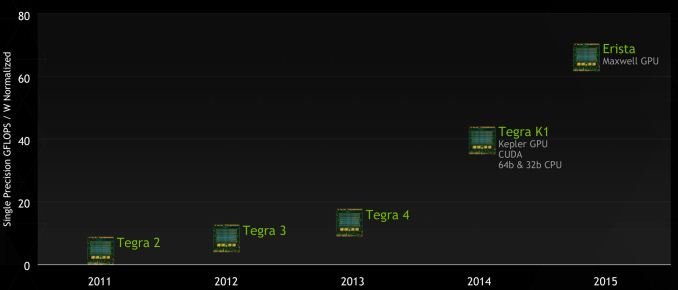
Az Nvidia már korábban egyértelművé tette, hogy az asztali és a mobilos GPU-architektúrákat összeolvasztja, azonos képességű, funkcionalitású grafikus processzorok fognak az okostelefonokban-tabletekben-autókban és a nagy munkaállomásokban is dolgozni. Az egyetlen fontos különbség a kiszerelés, vagyis a komolyabb teljesítményt kínáló asztali kártyákon sokkal több modul teljesít szolgáltatot. Az ígéretet a Tegra K1-gyel a gyártó valóra is váltotta, amely a Kepler architektúrát hozta el a mobilprocesszorok közé: a K1-ben egy Kepler modul (SMX) dolgozott, míg az asztali csúcsmodellben nyolc ilyen modul kapott helyet (természetesen eltérő órajelen, így a teljesítmény közvetlenül nem összehasonlítható).

Ezt az egységesítő logikát tovább viszi az Erista is, Kepler helyett immár a Maxwell architektúrával. A Maxwell újdonságairól már írtunk részletesebben, röviden ezt a GPU-t az Nvidia az extrém energiahatékonyságra hegyezte ki, a GPU minden elemét ennek megfelelően tervezte át a cég. A magasabb architekturális hatékonyság érdekes módon a PC-s GPU-k esetében is kritikussá vált, a 20 nanométeres eljárás ugyanis egyelőre csak mobilchipekhez optimalizált változatban érhető el, ezzel a teljesítmény növelésének egyetlen járható útja az azonos fogyasztásból elérhető teljesítmény maximalizálása lett. Érthető módon a mobilos környezetben mindig kritikus az alacsony fogyasztás, így a Maxwell-fejlesztések természetesen a Tegra vonalnak is nagyon jól jöttek, annak ellenére, hogy itt már elérhető a 20 nanométeres gyártás.
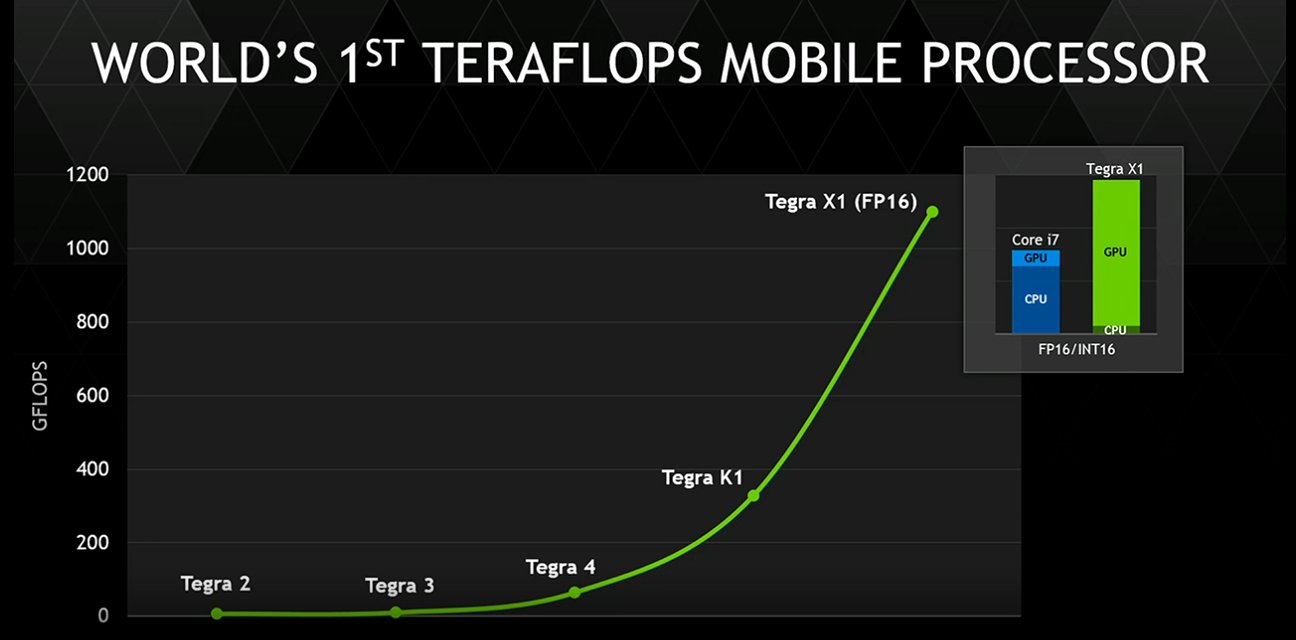
A grafikus tapasztalatokkal bőven rendelkező Nvidia álláspontja szerint az új Tegrák kitörési pontja pontosan ez a terület lehet. Miután az idei mobilprocesszorok mindenike ugyanazokat a CPU-kat használja (a fent említett Samsung mellett a Qualcomm is kénytelen volt az ARM-tól kölcsönözni a 64 bites magokat, mivel sajátjai még nem állnak készen). Így a differenciáló tényező a mobilos lapkák között a CPU-t körbevevő egyéb egységek, köztük a GPU lehet - annak sebessége és különösen annak hatékonysága. Az X1 esetében az Nvidia mintegy kétszeres hatékonyságnövekedést vár a K1-hez képest, köszönhetően az újratervezett architektúrának. Mivel a mobilos piacon jellemzően a maximális megengedhető fogyasztás limitálja a teljesítményt, ez gyakorlatilag kétszeres sebességként értelmezhető - ami igen jelentős előrelépést jelent.
A GPU nyers teljesítményét tovább fokozza, hogy az Nvidia lehetővé tette a felezett pontosságú lebegőpontos műveletek (FP16) duplázott sebességű végrehajtását. A Maxwell ugyanis egyetlen FP32-es CUDA-utasítás helyett végre tud hajtani két FP16-ost, amennyiben azok ugyanazt a műveletet (szorzást, összeadást) igénylik. Ezzel a processzor elméleti teljesítménye 1 teraflops fölé ugrik - a számot a gyártó nem is győzi hangsúlyozni.
És a maradék
A lapka többi részének fejlesztése is a teljesítmény és a fogyasztás optimalizálásának jegyében zajlott. A memóriavezérlő LPDDR4 támogatást kapott, ezzel az elérhető elméleti sávszélesség 64 bites buszon 14,9 GB/s-ről 25,6 GB/s-re nőtt, a memória-alrendszer hatékonysága pedig 40 százalékkal nőtt. A videós kimenet maximális felbontása a K1-hez viszonyítva 3200x2000-ről 3840x2160-ra nőtt 60 FPS mellett, ezzel már a 4K-s kijelzőket is meg tudja hajtani a lapka megfelelő frissítés mellett. Ennek megfelelően megjelent a HDMI 2.0 támogatása is.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A dedikált képfeldolgozó egység (ISP) nagyjából hasonló maradt a K1-hez viszonyítva, a JPEG motor átviteli sebessége azonban jelentősen megnőtt, másodpercenként 120 megapixelről 600 megapixelre. A videós egység új formátumokat is támogat, a fix funkciós áramkörök immár hardveresen képesek dekódolni a h.264 és VP8 streameket 4K felbontásban, 60 képkocka mellett, így az ilyen kimenetet a teljes útvonalon tudja fogadni és kezelni a processzor.
Nem csak mobilba

A Tegra sorozatot az okostelefonos és tabletes felhasználáshoz tervezi az Nvidia, az Tegra 2 és 3 sikereit követően azonban nem nagyon jött ki csúcsmodell a cég lapkái köré tervezve. A cég az X1-et nem csak ezekbe az eszközökbe szánja, külön fejlesztési kapacitást dedikált a vállalat az autós felhasználásnak. Az Nvidia szerint a jövő autóiban több, nagy felbontású kijelző is dolgozik majd, a központi képernyő mellett a műszeregység, illetve a hátul utazók játékra és multimédiára használt képernyőit is a központi egységnek kell meghajtania. A cég erre a célra szánja a Drive CX platformot, amely a Tegra X1 alapjait használja, azonban azt teljes platformmá kerekíti ki. A Drive CX-en Android, Linux és QNX is futhat, ezt természetesen a célközönség, az autógyártók választják majd ki.

A Drive CX azonban csak egy eleme a teljes Drive PX csomagnak. Ezt az Nvidia már kifejezetten az önvezető autók számítási igényeinek megfelelően fejleszti, két Tegra X1 lapkával, és a megfelelő szoftverrel együtt. A cég beszámolója szerint a deep learning algoritmusokat használó szoftverrel az autó például képes átvenni a parkolóban való lassú cirkálás során az irányítást, sőt, a járművet az üres helyre képes le is parkolni a vezető helyett. Ebben természetesen rengeteg szenzor segíti a központi egységet, a megoldás azonban a cég szerint már most általánosan használható, működéséhez pedig elegendő az autóban található számítási kapacitás.