Dinamikus kódoptimalizációt alkalmaz a Denver
A héten zajló Hot Chips konferencián először részletezte saját fejlesztésű ARM processzormagjainak működését az NVIDIA. A vállalat dinamikus kódoptimalizációt alkalmaz a nagyobb teljesítmény érdekében.
Régóta terítéken van az NVIDIA saját fejlesztésű processzormagja, a vállalat tegnap végre konkrét részleteket is elárult róla. A Denver egy (64 bites) ARMv8 utasításkészlet-architektúrát alkalmazó processzormag, az NVIDIA azonban ebben az esetben csak az ISA licencet vásárolta meg az ARM-tól és teljesen saját magot fejlesztett, amelyekben számos egyedi megoldást alkalmazott az alacsony fogyasztás és a nagy teljesítmény elérése érdekében.
Dinamikus kódoptimalizáció
A Denver legnagyobb dobásának egyértelműen a dinamikus kódoptimalizáció tűnik. A modern processzorokban az áramkörök jelentős része nem az utasítások konkrét végrehajtásával foglalkozik, hanem azok olyan átrendezéséről, hogy a végrehajtóegységek a legmagasabb kihasználtsággal működhessenek. Az NVIDIA szoftverrel kerülte meg, hogy out of order processzort kelljen építenie, a Denver magjai in-order felépítésűek, azonban dinamikus kódoptimalizáció segítségével a gyakran futtatott kódrészleteket már átrendezve, optimalizálva kapják meg - lényegében az out of order logikát szoftver helyettesíti.
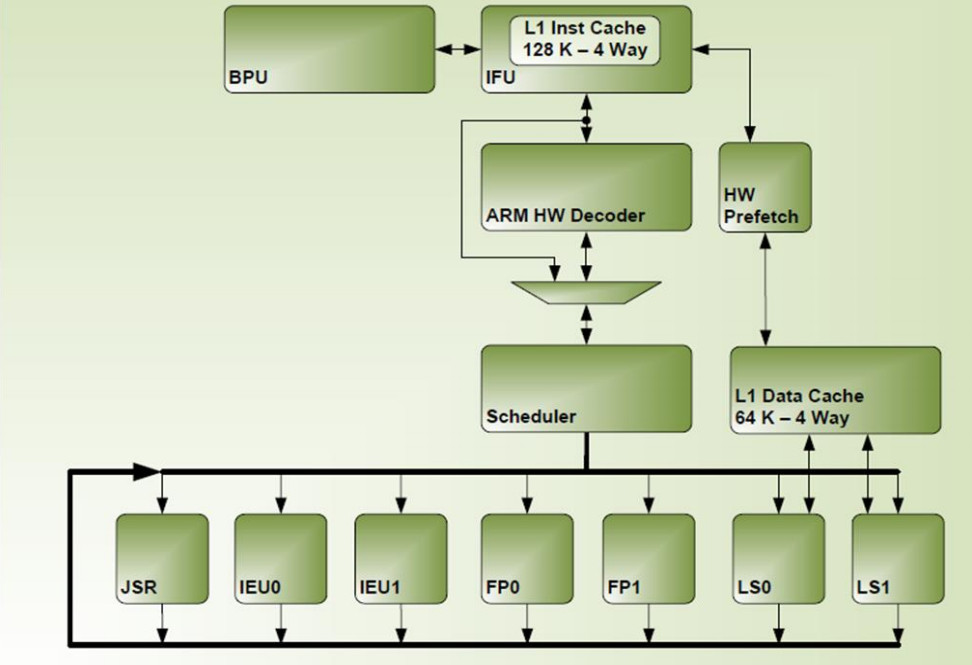
A processzor a Transmeta chipjeiben már látotthoz hasonló megoldást alkalmaz: a leggyakrabban futtatott kódrészleteket a Denver felismeri és egy saját szoftveres algoritmus segítségével futásidőben optimalizálja. Az optimalizált kód a rendszermemória egy elkülönített részében tárolódik és onnan hívja elő a CPU, amikor az adott kódrészletre kerül a sor. Az optimalizációt a Denver magok ráérő idejükben végzik, így ez elvileg nem lassítja a többi feladat végrehajtását. A folyamat az operációs rendszer és a felhasználói szoftverek számára teljesen transzparens.
Introvertáltak az IT-ban: a hard skill nem elég Már nem elég zárkózott zseninek lenni, aki egyedül old meg problémákat. Az 53. kraftie adásban az introverzióról beszélgettünk.
A cég szerint a futásidejű optimalizáció előnye, hogy mindig az adott szoftveres környezethez igazodik, ezáltal a leghatékonyabb. Az NVIDIA nem mást állít, mint hogy a szoftveres megközelítéssel az utasításablak akár ezres nagyságrendű is lehet, vagyis ennyi utasításból választhatja ki az ütemező a következőt, ellentétben a sok tranzisztort és bonyolult logikát felemésztő hardveres megoldások jellemzően 128-192 utasításos ablakával.
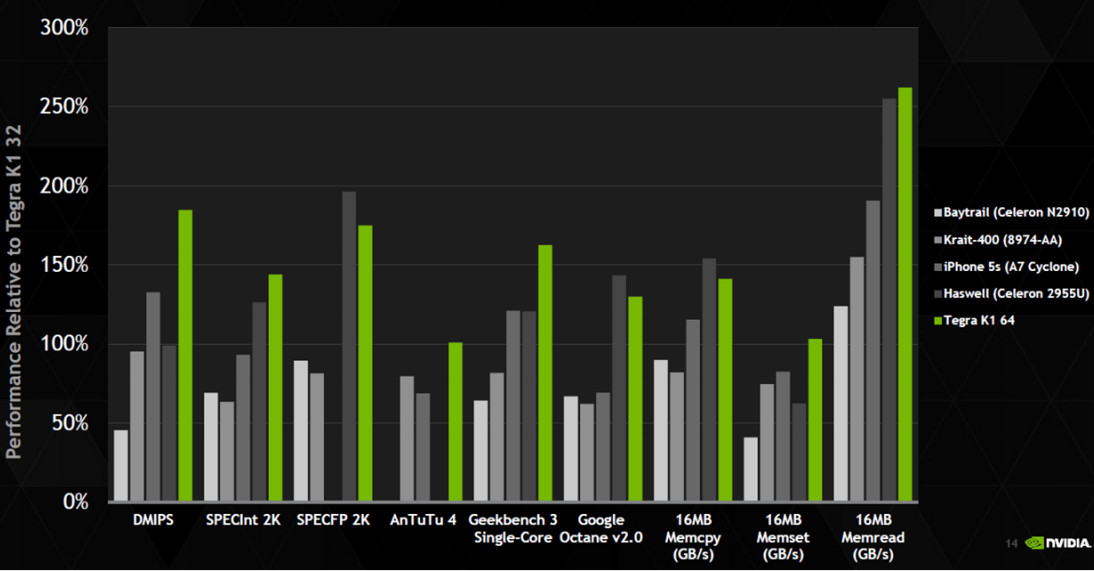
A processzor már néhány futás után az optimalizált kódra cseréli az eredetit, ez ugyan nagyobb méretű kód is lehet, de a 128 64 KB-os (I+D) cache ezt a cég szerint jól kompenzálja. Az eredmény: a Denver ideális esetben órajelenként 7 ARM utasítást tud végrehajtani, ami bő kétszerese a Cortex-A15 vagy Cortex-A57 hasonló értékének, ezáltal jóval nagyobb teljesítményre képes azoknál a gyakran ismétlődő kódok alatt. A közzétett teljesítményadatok alapján a 2,5 GHz-es Denver a legtöbb tesztben maga mögé utasítja a mobilos konkurenciát (pl. ARM Cortex-A15, Qualcomm Krait, Apple Cyclone, Intel Silvermont), de egyes esetekben még az 1,4 GHz-es Haswell-generációs Celeron-2955U chipet is lehagyja - nagy kérdés persze a fogyasztás és hőtermelés, ezekről az NVIDIA egyelőre semmit sem árult el.
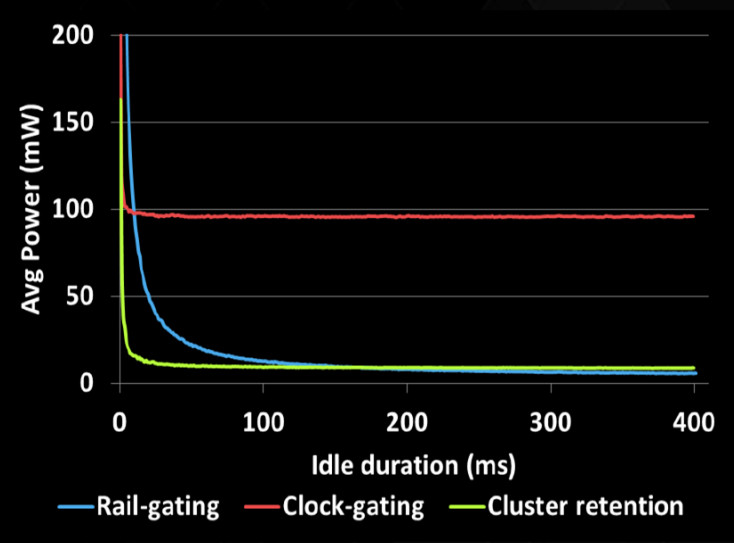
Mivel a Denver esetében csak az ISA származik az ARM-tól, az NVIDIA mérnökeinek szabad volt a keze, hogy tetszőleges energiatakarékossági trükköket implementáljanak a fogyasztás és hőtermelés kordában tartása érdekében. A Denver esetében a CC4 nevű energiakatarékos állapot megjelenése jelenti ezen a téren az újdonságot, ebben az állapotban a cache-ek tartalma és a CPU állapota ("state") marad meg csupán, minden más áramkör lekapcsol. A cég szerint ebből az állapotból gyorsan vissza lehet térni a normál üzemmenethez, miközben a fogyasztás majdnem olyan alacsony, mintha az egész magot lekapcsolnák.
Mire lesz elég két mag?
A jelenleg rendelkezésre álló információk szerint a Denver igen ütősnek ígérkezik, ami a teljesítményt illeti - de hogy ezért mekkora magmérettel (a 128 kb L1 cache extrémnek számít mobilos viszonylatban, de még asztali CPU-k terén is), fogyasztással és hőtermeléssel kell fizetni, az nem világos. Az első Denver chipek feltehetően azért lesznek "csak" kétmagosak, mert a processzormagok mérete nem tesz lehetővé több gazdaságos elhelyezését - a nagyobb teljesítmény azonban valószínűleg kárpótol ezért, a két magnak csupán a marketingüzenetek terén lehet érezhető hátránya, amikor a Denvert négy- vagy nyolcmagos chipekkel kell felvennie a harcot a vásárlók kegyeiért.