Radikálisat villantott az NVIDIA
Néhány váratlan bejelentéssel sokkolta hallgatóságát az NVIDIA a GPU Technology Forumon. Radikálisan megújult a termékterv, és jönnek az alaplapi foglalatba illeszkedő GPU-k.
Új termékterv
Az NVIDIA korábbi termékterve szerint a nemrég megjelent új generációs mikroarchitektúra, a Maxwell igazi újdonsága az egységes (egységesen címezhető) virtuális memória, a következő generáció pedig a Volta, amely a GPU-ra rétegelt, nagy sebességű memóriát hozta volna. Ezzel szemben az új terméktervben a Maxwell már nem kapja meg az egységes memória hardveres támogatását, csupán a CUDA 6 részeként egy szoftveres megvalósítást. Valódi újdonságként így csak a DirectX 12 támogatása szerepel. Ez azért nagyon meglepő, mert az NVIDIA bejelentése szerint a DX12-t támogatni fogja nem csak a Maxwell, de a Kepler és a Fermi architektúra is, így ez a bejelentés több kérdést vet fel, mint amennyit megválaszol.
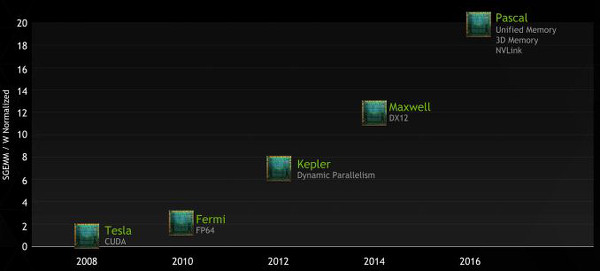
Ennél is érdekesebb, hogy a Volta eltűnt a terméktervről, helyette 2016-ra érkezik a Pascal, amely megkapta a Maxwellhez ígért egységes memóriát, mellette pedig megkapja a tokon belüli, a GPU-ra rétegezett memóriát is, és az igazi meglepetést, a vadonatúj NVlink csatolót is. Az egyelőre nem tiszta, hogy mi a különbség a Pascal és a Volta között, a vállalat tájékoztatása szerint a Volta kódnév továbbra is él és a Pascalt követő architektúrát jelöli.
NVlink és foglalatos GPU-k
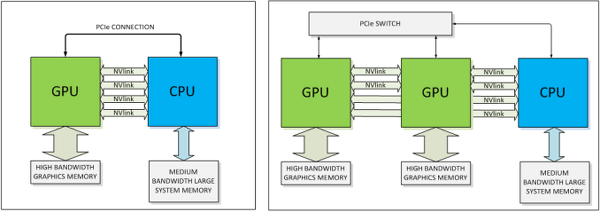
A nagy dobás a fent említett NVlink csatoló, amely az NVIDIA szerint meg fogja oldani a PCI Express skálázódási problémáját. A széles körben elterjedt PCIe sávszélessége éppen elegendő arra, amire most használjuk, a GPU és a CPU közötti kommunikációra, a GPU-k összekötésére illetve a CPU-GPU szorosabb együttműködését feltételező GPGPU-feladatokhoz azonban kevés. A problémára már vannak megoldások, az AMD HyperTransport, vagy az Intel Quick Path Interconnect (QPI) hasonló problémákra adott válaszok, amelyek rendkívül gyors és alacsony késleltetésű pont-pont kommunikációt tesz lehetővé.
Az NVIDIA-nak eddig nem volt ilyen csatlakozója, ezt a hiányt pótolja most az NVlink elnevezésű interfész. A cég ígérete szerint az NVlink elképesztően gyors lesz, egy blokk (8 sáv) 160 gigabites átvitelt tesz lehetővé, 20 gigatranszfer/másodperc sebesség mellett. A blokkok kombinálhatóak is, amivel az elméleti sávszélesség tovább skálázható. Az NVlink (a fent említett HyperTransporthoz és QPI-hez hasonlóan) közvetlenül a processzorok között teremt kapcsolatot, az interfészben nincsenek közvetítőlapkák és elosztók. Ennek megfelelően egy blokk két GPU-t képes összekötni, több lapka összekötéséhez több blokkra van szükség, a chipek ilyenkor NUMA architektúrában hálózatba is rendezhetőek.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Az NVlink implementációjához az NVIDIA egy új fizikai csatlakozót is szükségesnek tartott, a hagyományos kártyás megoldás helyett úgynevezett mezzanine csatlakozót használ. Ez, kombinálva a Pascal másik érdekességével, a chipre rétegezett memóriával, egy vadonatúj kialakítást tesz szükségessé: a GPU gyakorlatilag foglalatba illeszkedik majd az alaplapon, a nagyméretű (de a hagyományos videokártyákhoz viszonyítva apró) tokozásban egy platformra kerül majd a grafikus egység és a fedélzeti memória (és a tápellátás áramkörei).
Az implementáció várhatóan komoly együttműködést igényel majd az NVIDIA és az alaplapgyártók között, a foglalat ugyanis jelen állás szerint NVIDIA-specifikus lesz. Érdekesség, hogy az NVlinket a gyártó az OpenPOWER konzorcium tagjaként elérhetővé teszi a partnerek felé, így a jövőben megjelenhetnek olyan POWER processzorok, amelyek natívan támogatják az NVlink csatlakozást. Ez gyakorlatilag az AMD Torrenza koncepciójának újjáélesztése, a gyártó korábban a HyperTransport protokollon keresztül tette volna lehetővé a CPU és foglalatos koprocesszorok (GPU, ASIC) együttműködését.
Az NVIDIA már az NVlink 2.0-s verzióján is dolgozik, amely jelen állás szerint a Voltában (a Pascal után) mutatkozhat be. Ez az implementáció már elhozná a gyorsítótár-koherenciát (cache coherence), amely jelentős sebességnövekedést hozna az így összekapcsolt processzorok számára és lehetővé tenné, hogy különböző lapkák valóban azonos feladatokon dolgozzanak. Ez hatalmas ugrás lenne a GPU számára és közelebb hozná az NVIDIA-t ahhoz a szinthez, ahol most az Intel és az AMD tart a CPU-GPU integrációban.