Óvatosan csiszolja a Bulldozert az AMD
Kerülte a látványos átalakításokat az AMD a Steamroller magok fejlesztésénél. Az asztali és szerverprocesszorok alapját adó architektúrát inkább apró módosításokkal csiszolgatja a gyártó, ennek megfelelően az előrelépés sem túl nagy.
A várakozásoknak megfelelően marad a Bulldozer processzorgeneráció alapvető felépítése a harmadik iterációnak számító Steamroller alatt is. A 2000-es évek elején elkezdett fejlesztés 2011 második felében mutatkozott be, csalódást keltő teljesítménye nyomán pedig az AMD részesedése tovább olvadt a cég túlélése szempontjából kritikus fontosságú szerverprocesszorok piacán, de a noteszgépekbe szánt, illetve asztali processzorok esetében sem növelte az AMD versenyképességét az új generáció.
A Bulldozer fejlesztése az előzetes terveknek megfelelően gőzerővel folyik tovább, az eredeti változat után a Trinityben idén bemutatkozott Piledriver a számottevő fogyasztáscsökkentést és az apró finomításokat helyezte előtérbe, az immár 32 nanométeres SOI technológia helyett 28 nanométeres "bulk" eljáráson készülő Steamroller pedig szintén ugyanilyen hozzáállással tovább csiszolja az architektúra gyenge pontjait.
Felületi kezelés
A legfontosabb változás a magokat feladatokkal és adatokkal ellátó frontend egységet érinti, amelynek egyes elemeit az AMD megduplázta, így nagy párhuzamosságú feladatok esetén a processzor egyik fontos szűk keresztmetszete eltűnik. Míg a Bulldozer és Piledriver esetében minden két mag egy-egy négy utasítás széles dekódoló egységen osztozott, a Steamroller esetében magonként jár ekkora, amelyek teljesen párhuzamosan dolgoznak. Az AMD ezzel gyakorlatilag beismerte, hogy a két mag között teljesen megosztott frontend, amelyet a Bulldozerben helytakarékossági okok miatt alkalmazni volt kénytelen, nem olyan hatékony mint kellene.
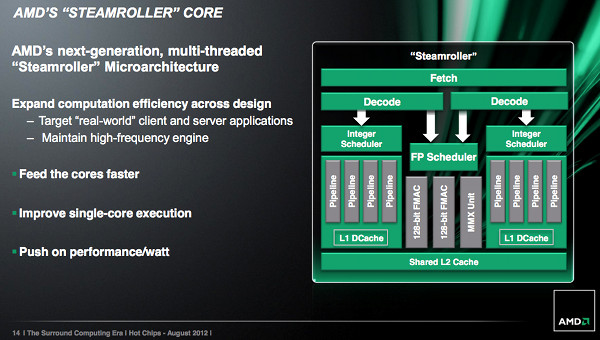
A frontend a Steamrollerben nem duplázódott meg teljesen, a betöltést (fetch) végző egység továbbra is megosztott marad a két mag között. Változások azonban itt is vannak, a cache-tévesztés aránya 30 százalékkal, a hibás elágazásbecslés aránya pedig 20 százalékkal csökkent. Ez a hatékonyságnövelés százalékokban mérhető teljesítménynövekedést jelenthet - a pontos érték persze számítási feladattól függően szélsőségesen változhat.
Introvertáltak az IT-ban: a hard skill nem elég Már nem elég zárkózott zseninek lenni, aki egyedül old meg problémákat. Az 53. kraftie adásban az introverzióról beszélgettünk.
A végrehajtás oldalán kevesebb a változás, az AMD a regiszterek méretét növelte meg és az ütemező hatékonysága is javult némileg. Az integer magok keveset változtak, a lebegőpontos műveleteket végző egységet azonban alaposan átdolgozta az AMD. A fejlesztés célja nem a teljesítmény növelése volt, a redundáns elemek eltüntetésével a mag méretét csökkentették. Erre az AMD szerint úgy nyílt lehetőség, hogy az MMX egység és a 128 bites FMAC egységek közötti közös elemekből csak egyet hagytak meg. A gyártó szerint ez nem jár majd sebességcsökkenéssel, a közös hardvert használó utasítások egymást kizáróak, így nem versenyeznek az végrehajtásért.
A fogyasztáscsökkentés sem maradt ki a fejlesztésből, a legnagyobb energiamegtakarítást várhatóan az új gyorsítótár-kezelés hozza majd a Steamroller esetében, a másodszintű cache ugyanis immár feladattól függően négy lépésben kapcsolható le. Ez főleg nem megterhelő feladatok esetén (például videónézés) hozhat megtakarítást, amikor a CPU gyorsítótár-igénye alacsony. Mivel a relatív nagy cache elektronszivárgásos vesztesége ezzel részben kiküszöbölhető, a fogyasztáscsökkentés kézzelfogható méretű lesz.

Tervezz okosan
Az AMD közlése szerint fontos változások következnek a processzortervezési folyamatokban, az időigényes kézi optimalizáció helyett minden korábbinál több automatizmust fognak használni, ez a törekvés az Excavator esetében már kézzelfogható eredményekkel is szolgálhat, az előzetes eredmények szerint 15-30 százalékos fogyasztáscsökkenést is el lehet érni az új módszerrel utasításonként, köszönhetően a kisebb alapterületnek, és az így csökkenő huzalozási igénynek. Az automatizáció alapját az AMD GPU-fejlesztésért felelős mérnökei tették le a High Density Library-val, amely a fontosabb áramkörök nagy sűrűségre optimalizált gyűjteménye, ezekből lehet modulárisan kirakni a processzort. A folyamatváltás jól jelzi egyébként, hogy a nagy órajelekhez szükséges manuális tervezés már a CPU-k között is eltűnőben van - a GPU-k automatizált tervezése ebben előbbre járt.