2012-ben jön az Intel x86-os koprocesszora
Nagy terveket sző az Intel a mérnöki-tudományos számítástechnika terén. A vállalat azt ígéri, 2018-ra 1 exaflopsos szuperszámítógépet építését teszi lehetővé, vagyis a mostani legjobbnál 125-ször gyorsabbat, de a fogyasztása csak annak a duplája lesz.
A nagy ígéret
A héten Hamburgban zajló International Supercomputing Conference 11-en (ISC11) Kirk Skaugen, az Intel Data Center Group vezetője közölte, 2018-ban az Intel által szállított alkatrészekből 1 exaflops, azaz 1000 petaflops teljesítményű szuperszámítógépet lehet majd építeni, amelynek fogyasztása nem haladja meg a 20 megawattot. A világ legerősebb szuperszámítógépe jelenleg a Japánban működő Fujitsu K Computer, amely 8 petaflopsos számítási teljesítménye mellett 10 megawatt elektromos fogyasztást alakít hővé.
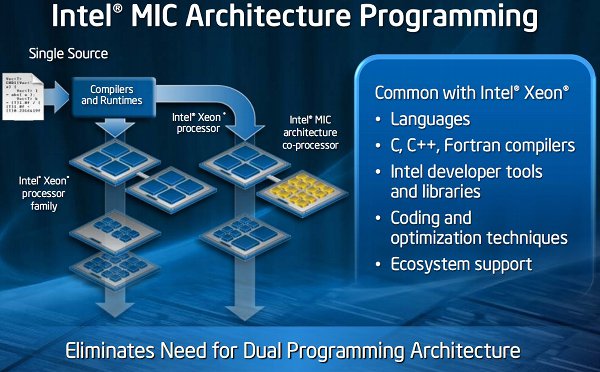
A mérnöki-tudományos számítástechnika világ nem idegen az Inteltől, a Top500 listán szereplő gépek majdnem négyötödében Intel processzor dolgozik. Az Intel célja, hogy "demokratizálja" a nagy teljesítményű számítástechnikát, mindenki számára elérhetővé tegyen akkora teljesítményt, amelyre néhány éve még csak a szuperszámítógépek voltak képesek. Ehhez a kulcsot a MIC projekt jelenti, ami a Many Integrated Cores rövidítéséből áll össze. A MIC keretén belül az Intel olyan, több tucat egyszerű x86 magot integráló chipeket fejleszt és gyárt, amelyek segítségével hatékonyan lehet mérnöki-tudományos számításokat gyorsítani.
A koncepció kísértetiesen hasonlít a GPGPU-k elgondolásához, azonban míg a GPGPU-kkal az NVIDIA és az AMD a grafikus chipek felől közelít az általános számítások felé, addig a MIC az Intel hagyományos területe felől, az általános célú x86 mikroprocesszorok oldaláról érkezik és nagyban épít a Larrabee projektre.

A GPGPU is jó, de....
GPU-kkal sok számítási feladat jelentősen felgyorsítható, erre a legjobb példát a Top500 listán található gépek jelentik: a tíz legerősebb gépből háromban is használnak GPU-kat, összesen pedig 19 GPU-gyorsított rendszer van a listán. A GPUk befogása általános számításokra azonban egyáltalán nem triviális feladat. Dr. Kai Lu, a világ második legnagyobb teljesítményű szuperszámítógépét, az NVIDIA Tesla processzorokkal gyorsított Tianhe-1A rendszert üzembe állító kínai Katonai Műszaki Nemzeti Egyetem professzora az ISC11-en tartott előadásában elmondta, a GPU technológiákat nehéz megtanulni, nincsenek kifinomult szoftverfejlesztői eszközök és hiányoznak a hatékony debuggoló és profilírozó szoftverek is.
Az Intel szerint az x64 magok használatának legnagyobb előnye a GPGPU megközelítéssel szemben, hogy a fejlesztőknek nem kell új programozási modellt vagy nyelvet elsajátítani és a vállalat széles körben elterjedt fejlesztői eszközei (fordító, debugger) is használhatók. Az Intel felkészíti fordítóit és optimalizáló eszközeit a MIC támogatására, így a programozók azonos forrásból azonos fejlesztői eszközökkel olyan binárist készíthetnek, amely fut a Core/Xeon processzorokon, de a MIC gyorsítóchipek képességeit is kihasználja, ha vannak a rendszerben. Utóbbihoz mindössze néhány sort kell a kódban elhelyezni.
Dr. Arndt Bode, a Németország egyik legnagyobb szuperszámítógépét üzemeltető Müncheni Egyetem professzora elmondta, az Inteltől kapott tesztrendszerekkel és korai állapotú szoftverekkel, meglevő programozási ismereteik birtokában rövid idő alatt látványos előrelépést értek el – volt olyan algoritmus, amelyet több mint háromszorosára tudtak gyorsítani azzal, hogy a Xeon processzorok mellett egy Knights Corner gyorsítókártya is dolgozott a gépben, a szükséges szoftveres módosításokat pedig 1-2 nap alatt el tudták végezni.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
Az Intel nem vonja kétségbe a GPU-gyorsítás létjogosultságát – vannak és biztosan továbbra is lesznek olyan területek, ahol a GPGPU megközelítés rendkívül hatékony, ha rendelkezésre áll az a szoftverfejlesztői tudás, amivel kihozható a grafikus chipekből a bennük rejlő erő. Az Intelnél ugyanakkor úgy látják, a nagy számítási teljesítményre éhes felhasználók többsége nem akarja majd felvállalni a szoftverek átírásával vagy módosításával járó anyagi terheket és bonyodalmakat – mindig is olcsóbb volt új hardvert venni mint egy meglevő szoftvert újraírni vagy optimalizálni.
Larrabee újratöltve
Már a tavalyi ISC-n is jelen volt masszívan párhuzamos Knights Corner chipjével az Intel, az azóta eltelt egy év alatt pedig számos partnert sikerült a kezdeményezés mellé állítani – mondta el az ISC-n tartott sajtótájékoztatón Kirk Skaugen. Jelenleg 50, a mérnöki-tudományos számítástechnika területén jelentősnek számító szervezet teszteli világszerte a cég sokmagos x86-os gyorsítóchipjét, a cél az, hogy az év végére a partnerek száma a duplájára növekedjen.
A Knights sorozat az Intel eredetileg grafikus területre szánt Larrabee projektjének szülötte, azonban a cég időközben megváltoztatta a céljait, áruta el a HWSW-nek egy beszélgetés során Anthony Neal-Graves, az Intel Architecture Group munkaállomásokért és a MIC koncepcióért felelős vezetője. Hogy ez miért történt, arról legfeljebb spekulálni lehet. Egyrészt az Intel feltehetően belátta, hogy nem rendelkezik elegendő know-how-val a GPU-k területén ahhoz, hogy érdemben felvegye a harcot az AMD-vel és az NVIDIA-val a high-end szegmensben – bár Neal-Graves szavaiból arra lehet következtetni, a cég még nem tett le erről.
Másrészt az egyre fejlődő integrált GPU-k kielégítik a legtöbb PC-felhasználó igényeit, így a high-end GPU-k piaca nem vonzó már annyira. Utóbbit valószínűleg az NVIDIA és az AMD is érzékelte, hiszen egy ideje a grafikus chipek fejlődésének irányát is a GPGPU területen való jobb használhatóság határozza meg elsősorban. Az NVIDIA már a Fermit is inkább mérnöki-tudományos alkalmazásokra tervezte mint grafikára, az AMD pedig a múlt héten vázolta évek óta fejlesztett következő generációs GPU-architektúráját, amely nem csak felépítésében szakít teljesen a korábbiakkal – a megcélzott feladatokról sokat elárul, hogy shader egységek helyett a vállalat már compute unitokról beszél.
A lovagok
A 45 nanométeres csíkszélességgel gyártott Knights Corner még csak egy fejlesztési platform, a chipek kiviteltől függően 30-32 maggal rendelkeznek és 1,05-1,2 GHz-es órajelen működnek. A következő változat, a Knights Ferry azonban jó úton halad afelé, hogy az Intel 22 nanométeres csíkszélességű gyártástechnológián kereskedelmi termékké váljon. Elsőként valószínűleg PCIe felületű bővítőkártyaként lesz elérhető a Knights Ferry, ahogy az Intel ezt demózta is, de nem zárható ki, hogy később, a gyártástechnológia fejlődésével párhuzamosan akár a tokozás, akár a szilícium szintjén integrálódjon az általános processzorokkal ugyanúgy, ahogy az a grafikus vezérlőkkel történt.

A Knights Ferryről egyelőre nem hoz nyilvánosságra részletes architekturális adatokat az Intel, mindössze annyit lehet tudni a chipről, hogy 50-nél több egyszerű x64 magot tartalmaz széles vektorizált (SIMD) kiterjesztéssel, 100 új utasítással és négy utasításszál párhuzamos végrehajtásának lehetőségével (Hyper-Threading). Megjelenési időpontról hivatalosan nem beszélnek a vállalat képviselői, de „folyosói pletykák” szerint 2012 második felére esik majd a premier. Az Intel már megnyert magának olyan szervergyártó partnereket mint az SGI, a Supermicro, a Dell, a HP és az IBM.
A Knights Ferry számítási sebességét konkrétumot nélkül nehéz lenne előre megbecsülni, de a 45 nanométeres, 32 magos, 1,2 GHz-es Knights Cornerrel elért teszteredményekből kiindulva a HWSW az NVIDIA Tesla C2070-nel egy súlycsoportba várja a 22 nanométeres verziót, amely jóval több magot vonultat fel és az órajele is alighanem magasabb lesz. Kérdés, mire lesz elég (kétszeres pontosság mellett) 0,5-0,6 teraflops teoretikus csúcsteljesítmény 2012 második felében a következő generációs AMD és NVIDIA chipek ellen.