Inkább okos, mint erős az AMD Bulldozere
Az AMD további részleteket csepegtetett jövőre debütáló új x86 mikroarchitektúráiról, amelyeket ma mutat be a Stanford Egyetemen évente megrendezett Hot Chips konferencián. Jelenleg azonban nem tudni, pontosan milyen termékek alapoznak majd az új fejlesztésekre, és a megjelenési idejükkel kapcsolatban is csak spekulálni lehet.
Az AMD számára 2011 sorsfordító év lehet, ugyanis hosszú idő után gyökeresen megújítani ígérkezik x86-os processzorainak felépítését. A vállalat számára mindez kritikus fontosságú, az Intellel szemben ugyanis hatalmassá duzzadt a lemaradása, ami a mikroarchitektúrákat illeti. Mindez az Intel gyártástechnológiai lépéselőnyével párosulva hatalmas nyomás alá helyezi az AMD-t, amely így kénytelen drágábban termelhető termékeket az Intelnél jóval olcsóbban kínálni - az AMD 12 magos Opteron termékei nagyjából 700 négyzet-milliméternyi szilíciumot emésztenek fel, miközben a kétfoglalatos szerverekben még némileg magasabb teljesítményszintet is kínáló Intel Westmere-EP Xeon chip mérete 250 négyzetmilliméter körül alakul.
A helyzet különösen a szerverpiacon súlyos, ahol az AMD a második negyedév során 3,3 százalékpontot bukott el részesedéséből, és 6,5 százalékra szorult vissza, miután az Intel elkezdte forgalmazni a még nagyobb teljesítményt és energiahatékonyságot kínáló 32 nanométeres Xeonjait, elcsípve a vállalati beszerzések felpezsdülésének kezdetét. Az AMD-re nézve különösen aggasztó, hogy a vezető szervergyártók közül kizárólag mindössze a HP és a Dell foglalkozik a cég legújabb, Magny-Cours Opteronjaival.
Ezen a helyzeten kell változtatnia a Bulldozernek, amely az AMD szerverekbe, munkaállomásokba és nagy teljesítményű kliensekbe szánt processzorok alapjául szolgál majd. A Bulldozernek hatalmasat kell ugrania a jelenlegi, 10h kódnévvel ellátott mikroarchitektúrához képest, ha le akarja dolgozni az AMD lemaradását. Nehezíti a feladatot, hogy a nagyjából egy év múlva megjelenő Bulldozernek nem az Intel jelenlegi felhozatalával, hanem a jövő évi Sandy Bridge generációval kell megmérettetnie magát - igaz, az eddigi publikációk alapján az előrelépés inkább inkrementális a jelenlegi 32 nanométeres szerverchipekhez képest.
A Bulldozer koncepciója már korábban napvilágot látott, és az AMD friss közzététele továbbra is csak a magas szintű felépítését taglalta, így viszonylag kevés új érdemi információ látott napvilágot. A Bulldozer célja nem más, minthogy ellensúlyozza az Intel hatalmas előnyét az egységnyi szilíciumterületre és energiafogyasztásra eső teljesítmény terén, amely alapvetően a gyártástechnológiában gyökerezik, és csak másodsorban a fejlett Nehalem mikroarchitektúra eredménye.
1 + 1 < 2
A lépéshátrány leküzdése érdekében az AMD mérnökei újragondolták a többszálú végrehajtást és a többmagos felépítést, és egy harmadik megközelítés mellett döntöttek, amely a kettő közé esik koncepcióban. A klasszikus megközelítésben a magok számának növelése egyet jelent a magok teljes replikációjával, vagyis a teljesítmény fokozódásával párhuzamosan meredeken emelkedik a fogyasztás, valamint kisebb mértékben, de továbbra is jelentős mértékben az elfogyasztott szilíciumterület.
Egy modern x86 processzormagban azonban a valódi számításokat végző végrehajtóegységek csak az energiakeret és szilíciumterület egy töredékét fogyasztják, miközben a támogatást végző többi, úgynevezett vezérlő logikát megvalósító áramkörök emésztik fel a mag nagy részét - ezek végzik a adatok betöltését és kiírását, a SRAM cache vezérlését, az x86 utasítások dekódolását, ütemezését, az elágazások spekulatív lekezelését, és az eredmények integritásának felügyeletét. Miközben rengeteg területet foglalnak, kihasználtságuk viszonylag alacsony, hogy ne alakuljanak ki aránytalanul szűk keresztmetszetek a teljesítmény előtt.
A szerver- és PC-kódok többsége ráadásul utasítások egy viszonylag jól behatárolható keverékét futtatja, amelyek többségükben egész számokkal dolgoznak. Chekib Akrout, a Bulldozerért is felelős technológiai kutatás-fejlesztési részleg vezetője szerint az elemzések azt mutatták, a teljesítménykritikus alkalmazások többsége 80 százalék feletti arányban hajt végre fixpontos műveleteket, vagyis csak kevesebb mint 20 százalékban történik lebegőpontos számítás vagy egyéb adatmanipuláció.
Mindebből az következik, hogy a teljesítményt a legtöbb alkalmazás számára anélkül is lehetséges erőteljesen fokozni, hogy a magokat teljesen replikálni kellene, mivel azok megosztozhatnak bizonyos erőforrásokon. Az ötlet természetesen nem új, a többmagos processzorok közel egy évtizede osztoznak különféle erőforrásokon, a koncepciót legélénkebben a Sun Microsystemst foglalkoztatta, törölt Rock processzora például osztott L1 tárakat használt, míg az első Niagara magjai egy közös lebegőpontos egységet használtak.
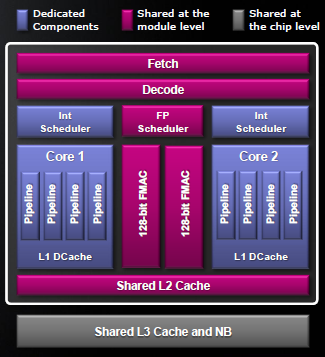
A két mag a közös erőforrásokkal együtt egy modult képez. Akrout világossá tette, hogy egy modul esetében két magról van szó, amint az operációs rendszerek és az alkalmazások is két teljes értékű magnak látnak, az osztott erőforrások a szoftverek felé teljesen transzparensek. Egy-egy chip több modulból épül fel, ahol a modulok osztoznak az L3 gyorstáron, és az eddig megszokott módon a többi magokon kívüli erőforráson, mint a memóriavezérlők és külső összeköttetések. Az egyes magok továbbra is megtartják a saját ütemezőjüket és az L1 adattárat - az L1 utasítástár osztott, hiszen logikailag a közös front-end előtt található.
Mennyi az annyi?
Az így elérhető megtakarításokat Akrout nem számszerűsítette, egyelőre legalábbis, az azonban nyilvánvaló, hogy igencsak jelentősek. Amennyiben ezt a koncepciót a 10h mikroarchitektúrára alkalmazzuk, akkor a replikálni szükséges áramkörök, az egész számokkal dolgozó végrehajtóegységek, a hozzájuk tartozó utasításokat ütemező logika és az L1 adattár, a mag területének nagyjából 30 százalékát tehetik ki legfeljebb. Ha mindehhez hozzávesszük a megosztott L2 tárat is, akkor az arány még kisebb, a 65 nanométeres Barcelona esetében így nagyjából 20 százalékos arányt kapnánk. Ez azt jelenti, hogy durva becsléssel 20-25 százaléknyi extra magterületért cserébe megduplázható a egész számokkal végzett feldolgozási kapacitás.
Mindez persze egyszerűsítés, hiszen a megosztott erőforrásokat kétségtelenül meg kell némileg növelni annak érdekében, hogy hatékonyan ki tudják szolgálni a két magot, különösen a sok helyet elfoglaló L1 és L2 tárra való tekintettel - az elérhető területbeli megtakarítások nagy mértékben függnek attól, hogy mennyire hatékony SRAM cache blokkokat tudnak alkotni az AMD mérnökei. A publikáció szerint egy modul, vagyis két mag nem 3, mint a jelenlegi 10h magokban, hanem 4 darab x86 dekóderen osztozik, amelyek az x86 utasításokat saját, RISC-szerű mikroutasításokra fordítják át.Szintén ront némileg a szilícium-kihasználáson, hogy az áramköröket összekapcsoló, többrétegű fém huzalozások, valamint a hőfejlődés miatt nem lehet fizikailag tökéletesen szorosan integrálni az új maghoz tartozó áramköröket, de összességében így is belátható, hogy a szilíciumbeli megtakarítások tetemesek lehetnek, bőven ellensúlyozva az Intel miniatürizációs és költségbeli lépéselőnyét.
Ez a felépítés ugyanakkor nem csak a felhasznált szilíciumterületben hoz jelentős javulást, hanem az energiahatékonyság és teljesítmény terén is előnyökkel kecsegtet. Mivel egy kétmagos modulon belül az áramköri redundancia nagy része megszűnik, így az aktív és szivárgási fogyasztás is jelentősen lecsökken a két önálló maghoz képest, hiszen egy modul várhatóan sokkal kevesebb logikai tranzisztorból épül fel. Akrout szerint egy modul teljesítménye közelíti két független magét, így egy jól sikerült implementáció esetében a fogyasztás nagyobb mértékben csökken, mint amekkora kompromisszumot a teljesítmény terén kötni kell - mindez az üzleti célú szerverek és a PC-k esetében kecsegtető leginkább, ahova a Bulldozert optimalizálták.
A Hot Chipsen közzétett információk alapján a Bulldozer átlagosan 80 százalékát hozza egy natív kétmagos implementáció teljesítményének. Érdemes megemlíteni, hogy a közös erőforrások többségét többszálúsítási technikával osztja fel a két mag utasításszálai közt, így a magasabb kihasználtság érdekében az egyes szálak teljesítménye némileg csökken a versenykondíciók miatt. A párhuzamosított területek, vagyis leginkább a front-end, úgynevezett vertikális többszálúsítást alkalmaznak, amikor az egyik órajelben csak az egyik, a másik órajelben a másik utasításszál számára áll rendelkezésre az adott egység, például a dekóderek.
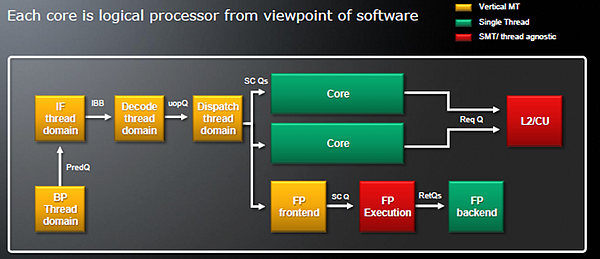
A Bulldozer logikai felépítése az utasításfolyam szempontjából
Érdemes külön kiemelni a megosztott lebegőpontos blokkot is, amivel szintén jelentős szilíciumterületet lehet megtakarítani. Bár az elmúlt időszakban a vezető processzorgyártók mindegyike, az AMD, az IBM és az Intel is bevezetett olyan technikákat, amelyekkel a gyári órajel fölé fokozható egy chip órajele, amennyiben az nem tölti ki az energiakeretet, a processzorokat még mindig a névleges órajel alapján árazzák be és értékesítik a piacon. Mivel a a névleges órajelet alapvetően a színtiszta, elágazásmentes lebegőpontos számításokat végző kódok által okozott hőfejlődés limitálja, ezért a kevesebb lebegőpontos végrehajtóegység azt is jelenti, hogy kevesebb hő szabadul fel csúcsterhelésen, mint egy klasszikus többmagos design esetében.
Mindez összességében azt eredményezi, hogy a Bulldozer modulja által megtakarított energiakeret mozgásteret adott a mérnökök számára, de egyelőre nem látni, hogy ezt a mozgásteret mire használja majd fel az AMD. A kézenfekvő lehetőséget közt van a névleges órajelek relatív megemelése, a modulok számának növelése, vagy kevésbé triviális módon a felszabadult energiabüdzsé újraelosztása a többi áramköri blokk közt, amivel a mérnökök továbbfejleszthetik azokat, például erőteljesebb utasítás-újrarendező motort, kifinomultabb elágazásbecslést vagy spekulatív előtöltést kaphatnak a magok. Ezzel együtt a Bulldozer chipek rendelkeznek majd dinamikus órajelnövelési technikával, amennyiben a chip által felvett energia nem éri el a küszöböt.
Buldózer vagy targonca?
A Bulldozer papíron ígéretes, azt azonban egyelőre nem tudni, a gyakorlatban hogyan válik be. Az AMD összességében úgy becsli, a Bulldozer-alapú processzorok adott energiafogyasztásból másfélszeres teljesítményt adnak le a jelenlegi Opteronokhoz képest, és harmadával több maggal rendelkezhetnek. Az elsőre impresszívnek tűnő mutatók ugyanakkor inkább aggodalomra adnak okot, semmint bizakodásra. Ennek a becsült hozadéknak ugyanis nagy részéért vélhetően az felel, hogy a Bulldozer már egy egész generációval fejlettebb, 32 nanométeres csíkszélességű eljáráson készül majd - egy generációnyi gyártástechnológia könnyedén biztosíthat 30 százaléknyi fogyasztáscsökkenést és miniatürizációt. Az Intel a 32 nanométeres Xeonokkal a mikroarchitektúra érdemi áttervezése nélkül például 40 százalékos teljesítménynövekedést ért el a 45 nanométeres generációhoz képest, a számításintenzív kódokból álló SPECint_rate2006 tanúsága szerint, amelyet viszonyítási pontként szoktak használni a gyártók a processzorok teljesítményprojekcióihoz.
A Bulldozernek ráadásul nem csak a szilícium- és energiahatékonyságbeli hátrányt kellene leküzdenie, hanem a magonkénti teljesítményben mutatott lemaradását. A másfélszeres feldolgozási kapacitás foglalatonként elegendő volna, hogy versenyben maradjon az AMD, a magonkénti teljesítmény azonban továbbra is fontos. Az üzleti szerverek és PC-k szempontjából ez egyaránt kritikus jelentőségű, igaz, egészen más okokból - a szerverek esetében szoftvergazdálkodási szempontból döntő, míg a PC-s szoftverek a mai napig jobban örülnek egy-két erőteljes és gyors magnak, mint több gyengébbnek.
Nem tudni, a Bulldozer egyes blokkjai, például a végrehajtóegységek vagy az ütemezők mennyiben hasonlítanak a jelenlegi 10h mikroarchitektúrájáéhoz, ugyanakkor egyértelműnek tűnik, hogy az erőforrások optimalizációjánál többre lesz szükség az Intel ellen. A Bulldozer és a 32 nanométer együtt talán megoldja a költségbeli kérdés nagy részét, ugyanakkor a magonkénti teljesítménnyel kapcsolatban maradnak kérdőjelek. Akrout direkt kérdésre sem kívánta elárulni, hogy a plusz 50 százalék teljesítmény és a plusz 33 százaléknyi mag kéz a kézben járnak-e.
Ez azt jelentené, hogy az egy magra eső teljesítmény alig 12 százalékkal emelkedne, ami továbbra is jelentős problémát okozna. Ezt erősítik ugyanakkor az AMD korábbi prezentációi, ahol 16 magos, multi-chip Bulldozer változatokról beszélt Interlagos kódnév alatt, és ezzel egybevágna az is, hogy miért 8 magos Bulldozer chipet vázolt fel az AMD - két ilyen chipből jön létre az Interlagos, pont, ahogyan két hatmagos szilíciumlapkából épül fel a Magny-Cours is. Ezt a forgatókönyvet elfogadva matematikailag ebből az is következik, hogy az integer magok a jelek szerint mégiscsak erősen átdolgozottak lehetnek, mivel annak ellenére nyújtanak nagyobb teljesítményt, hogy erőforrásokon osztoznak egymással. A foglalatonként 16 mag így legfeljebb 64 magos SMP-rendszereket eredményezhet.

Egy teoretikus nyolcmagos Bulldozer chip
Ha elfogadjuk, hogy az azonos fogyasztás mellett másfélszeres feldolgozási kapacitás harmadával több maggal valósul meg, valamint hogy ezek a magok a natív implementáció átlagosan 80 százalékát nyújtják, úgy az új integer magok 40 százalékkal erőteljesebbeknek ígérkeznek a jelenlegi 45 nanométeres 10h implementációnál. A probléma az, hogy az Intel jelenlegi 32 nanométeres, hatmagos Westmere-EP chipjei a piac legnagyobb részét kitevő kétfoglalatos rendszerekben magonként több mint kétszeres feldolgozási teljesítményt adnak le a Magny-Cours Opteronokhoz képest az egész számokkal végzett számításokat felmérő SPECint_rates2006 alapján,de ha az iparági tranzakcionális benchmarkokat nézzük,mint a SPECjbb2005 (Xeon X5680 vs. Opteron 6176SE), az SAP Sales & Distribution (Xeon X5680 vs. Opteron 6176SE) vagy a TPC-C (Xeon X5680 vs. Opteron 6176SE), akkor is hasonló arányok rajzolódnak ki - előbbiben az magasabb órajelek, utóbbiakban az AMD által kritizált Hyper-threading segít sokat az egyébként is erőteljesebb felépítésű Nehalem-mikroarchitektrúának.
Ezt a mikroarchitekturális és gyártástechnológiai eltérések mellett kétségtelenül magyarázzák az egy magra jutó memóriasávszélességben keresendő különbségek is. A Bulldozer chipek első generációja azonban a Magny-Cours platformjába illeszkedik majd, így szó sem lehet a memória sávszélességének drasztikus emelkedéséről, sőt, a magok számának emelkedésével az egy magra jutó effektív memóriasávszélesség még csökkenni is fog az AMD oldalán. Eközben az Intel a következő Sandy Bridge generációnál három csatornáról négy DDR3 csatornára bővít az azt kiszolgáló új platformon, hogy a sávszélesség lépést tartson a magok számának későbbi bővülésével. Mindez azt valószínűsíti, hogy bár az AMD partiban maradhat a foglalatonkénti és rendszerszintű teljesítményben, és ezt sokkal alacsonyabb gyártási költséggel mellett éri el, a magonkénti teljesítmény égető problémáját nem fogja tudni leküzdeni egyetlen lépésben.
Mivel az első Bulldozer-implementáció csak a második negyedévben készült el, ezért a hosszadalmas validációs folyamat miatt legkorábban jövő év közepére, de inkább második felére kerülhetnek piacra az első chipek, és a teljesítménykép is csak most, az első szilícium példányok tesztelése során alakul ki - kifejezetten aggasztó, hogy ez nagyjából egybeesik az Oracle és a Fujitsu döntéseivel, amelyek szerint a közeljövőben kizárólag Intel-alapú szerverekkel foglalkoznak. A felépítés egyik elkerülhetetlen következményének tűnik ráadásul, hogy a Bulldozer chipek relatíve gyengébben szerepelnek majd szuperszámítógépes, illetve a mérnöki- és tudományos felhasználási területeken. Elképzelhető, hogy az AMD ezt a rést majd az ATI Stream termékekkel igyekszik betömni.
Önök kérték: AMD Bobcat
Szerencsére nem a Bulldozer sikerén vagy bukásán múlik kizárólag az AMD jövője, műszakilag sokkal kevésbé izgalmas, ugyanakkor az AMD szempontjából sokkal fontosabb lehet a Bobcat, amely a hordozható eszközöket célozza meg. A Bobcat az AMD első fejlesztése, amely a mikroarchitektúra szintjétől kezdve a mobilitásra összpontosít, így célja az, hogy elfogadható teljesítményszintet nyújtson az elérhető legalacsonyabb fogyasztás mellett.
A notebookokat és netbookokat megcélzó Bobcattel az AMD célja az, hogy 1 watt alatti fogyasztású, az olcsó gyárthatóságot lehetővé tévő kompakt magokat tudjon létrehozni, miközben a teljesítmény megközelíti egy mai átlagos számítógépét - ennél pontosabban nem határozta meg a cég, mit ért "mainstream PC" alatt, ugyanakkor kihallható belőle a "jól használható" jelző. A Bobcat fele akkora maggal 90 százalékos teljesítményszintet hoz, amit valószínűleg egy mai Phenom vagy Athlon chippel történő összevetésre kell érteni.
A Bobcat esetében az AMD hangsúlyozza, hogy egy vagy több teljes értékű x86 processzormagról van szó, amelyek 1 watt alá tudnak menni fogyasztásban, ugyanakkor nem mellőzik a soronkívüli végrehajtást, a lebegőpontos egységeket, a 64 bites végrehajtást, SSE-kiterjesztéseket vagy a virtualizációs támogatást sem - sokkal használhatóbbnak tűnik az ultramobil Atomoknál. A két utasítás egyidejű feldolgozására képes Bobcat magok dedikált ütemezővel rendelkezik az integer (egész számok), lebegőpontos és memóriaműveletek számára, amivel az eddigi AMD mikroarchitektúrákra emlékeztet. A Bobcat teljesítményt fog feláldozni az adat előtöltések mellőzésével annak érdekében, hogy minimalizálja az adatmozgást, és így a fogyasztást. A chipek természetesen erőteljes órajel- és feszültségkapuzást is alkalmaznak majd a sebesség dinamikus szabályozása mellett.
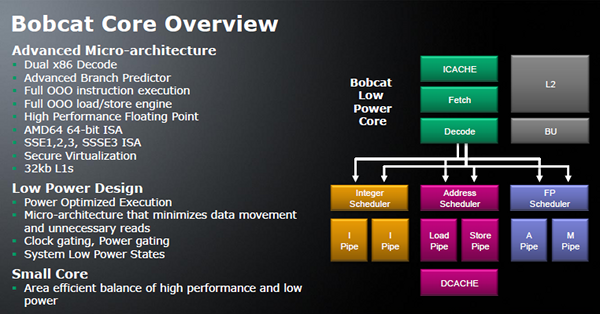
Az első Bobcat termék Ontario névre hallgat, és DirectX 11 grafikus magot is integrál. Az Ontario termelése akár idén megindulhat már, így jövő év elejére már a piacon lehetnek az ilyen chipekkel szerelt termékek. A gyártást nem az AMD-ből leválasztott Globalfoundries, hanem a tajvani TSMC végzi majd, 40 nanométeres eljárásán. Amennyiben a Bobcat termékek jól sikerülnek, úgy az AMD könnyedén növelheti majd jelenleg 15 százalék alatti piaci részesedését a notebookok hatalmas és gyorsan bővülő piacán, ami méretgazdaságossági okokból kritikus volna a cég hosszútávú versenyképességének szempontjából.