Intel: az NVIDIA chipjei csak két és félszer gyorsabbak
Az Intel szerint nem igaz, hogy az NVIDIA chipjei százszor gyorsabbak - a különbség tipikusan csak két és félszeres. Ezt a vállalat mérnökei által publikált tanulmány állapította meg, igaz, a kutatás gyakorlati hasznossága a nagy szórás miatt gyenge.
Core i7-960 vs. GeForce GTX 280
A HWSW olvasói bizonyára jól tudják, az utóbbi időben agresszív hangvételű pr-kommunikációs hadviselés zajlik az Intel és az NVIDIA közt. A grafikus chipek gyártója gyakorlatilag hétről hétre keres újabb és újabb bizonyítékokat, mennyire megsemmisítő vereséget mér az Intel x86 processzoraira, köszönhetően a CUDA fejlesztési környezetnek, amellyel nem grafikus, általános célú számításintenzív (HPC) feladatokra is befogható a GeForce/Tesla hardverek ereje. Az NVIDIA gépezete nem egy alkalommal akár százszoros gyorsulásról beszélt, mikor egy ügyfél áttért a cég megoldására.
Ezért döntött úgy az Intel, hogy rászabadítja mérnökeit a kérdésre, derítsék ki, mennyi valóságtartalma van ezeknek az állításoknak. Valószínűleg senkit nem fog meglepni, hogy az Intel megállapította: az NVIDIA állításai nem kissé túlzóak. Ezt kétségtelenül egyszerre magyarázza, hogy az NVIDIA az extrém eseteket emeli, miközben elsikkad a részletekben az, hogy pontosan milyen x86 processzorokkal szemben is tapasztalható ez a gyorsulás, pláne mennyire volt egyik-másik platformra optimalizálva a kód, de nyilvánvaló módon az Intel sem fog olyan eseteket összeválogatni, ahol valamilyen oknál fogva az NVIDIA állításai igazolódnának - igaz, a hardveres képességek közti különbségek valós körülmények közt valóban nem igazolnak két nagyságrendbeli különbséget.
Az Intel összesen 14 kód viselkedését teljesítményét vizsgálta meg egy Core i7-960, és egy GeForce GTX 280 chipen. A Nehalem mikroarchitektúrájú Core i7-960 egy 45 nanométeres csíkszélességgel készült, négymagos, magonként kettő 128 bites SIMD egységgel és két utasításszálat futtató processzor, 8 MB L3 tárral, amelynek gyári órajele 3,2 gigahertz, hőtermelése pedig tartósan legfeljebb 130 watt lehet. A GT200 mikroarchitektúrát implementáló GTX 280 chip 65 nanométeres eljáráson készült, 10 blokkban 30 processzorral, összesen 240 CUDA végrehajtóegységgel, órajelük 1,3 gigahertz, a hőfejlődés pedig 236 watt lehet. A Core chip így 102,4 Gflopsra képes 32 bites pontossággal, 32 GB/s memóriasávszélesség mellett, míg a GTX 280 elméleti csúcsa 933,1 Gflops és 141 GB/s.
Mint látható, a két chipben sem a gyártástechnológia, sem az energiaosztály nem közös, de még csak nem is kerülnek ugyanannyiba - az Intel processzora 500 euróért, míg egy GeForce GTX 280 videokártya 300 euró körüli összegért vihető haza Európában. Miért akkor e párosítás? A válasz valószínűleg az lehet, hogy mindkét architektúra 2008-as, ami kutatási szempontból ideálissá teszi azokat, hiszen más kutatási eredményeket is fel lehet már használni, és összevetéseket végezni, valamint mindkét hardver elég régóta piacon van már ahhoz, hogy a szoftveres eszközök érettsége is megfelelő legyen a megalapozott kép kialakításához.
Hatalmas szórás
A publikáció szerint mind a Core, mind a GeForce chip architektúrájára elvégezték a kódok optimalizálását, amelynek módját nagy vonalakban mindegyik kódnál részletezik is - tipikusan a memóriahozzáférések optimalizálásáról, a feladat felszeleteléséről és a végrehajtás párhuzamosításról, vektorizálásáról van szó. A kódok között megtalálható a lineáris algebra, pénzügyi kalkulációk, képelemzés, jelfeldolgozás, merevtest-fizika, adatbázis-rendezés és -keresés, valamint a ray casting renderelés is. A kutatás szerint a 14 kód alatt átlagosan két és félszeres teljesítményt adott le a GTX 280, ami még mindig hatalmas fölény, ugyanakkor közel sem az a nagyságrend, amiről az NVIDIA beszél.
A szórás ugyanakkor rendkívül nagy, a GTX 280 relatív teljesítménye az 50 százaléktól az 1490 százalékig terjedt, ami jól mutatja, mennyire érzékeny a kép a kód természetére - 2 kódban a Core i7 volt a gyorsabb, 5 kód alatt a GTX 280 sebessége kevesebb mint kétszeres, 6 kódban nagyjából három-ötszörös teljesítményt ad le, míg egy kód alatt közel tizenötszörös teljesítményt produkált a GPU. A mérnökök megállapítják, hogy tipikusan három eset van, amikor a GeForce drámai mértékben elhúz: a sávszélesség által limitált, alacsony számítási tömegű kódok, a számítási erőforrásokat kihajtó, rendkívül hatékonyan futó kódok, valamint az adattömbök rendezését végző gather/scatter utasításokkal dolgozó kódok, amelyek hardveresen támogatottak a GTX 280 chipben.
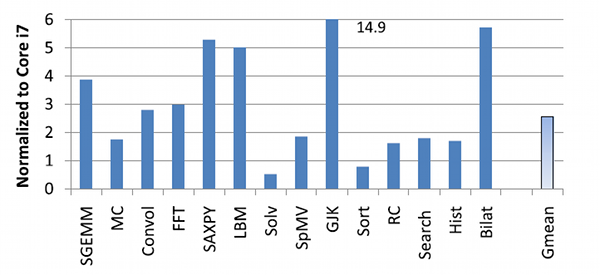
A GTX 280 relatív sebessége az Intel Core i7-960-ra normalizálva
Az Intel processzorai ott szerepelnek jól, ahol szükséges a szálak közti szinkronizáció, a feldolgozott adatok nagy része belefér a hatalmas gyorsítótárakba, vagy győz a magasabb szálankénti teljesítmény, mert a GeForce masszívan párhuzamos felépítését nem tudja követni a kód, vagy a kód extrém párhuzamossága által generált sávszélesség igényt nem tudja kielégíteni a memóriarendszer. A tanulság tehát ismét az, mint bármikor máskor: az adott alkalmazáshoz kell hardvert választani, figyelembe véve a kód portolhatóságát és annak idő- és pénzbeli költségeit - ha egy probléma estén az IT beszerzése és üzemeltetésének költsége nem mérhető a lehetséges üzleti haszonhoz, vagy a GPGPU-ra történő portolás sokkal drágább és lassabb volna, mint az egyszerű hardvervásárlás, akkor a gyors és egyszerű bevezetés, és későbbi bővítés a hagyományos processzorok mellett szólhat. Az Intel kutatása letölthető a HWSW szerveréről (PDF).
Mit hoz a jövő?
Az Intel javára írható azonban az a bátor tett, hogy nem tagadták: a vizsgált kódok többsége alatt egy NVIDIA GeForce GTX 280 sokkal gyorsabbnak bizonyult egy 3,2 gigahertzes Intel Core i7-960 chipnél. Az Intel mérnökei láthatóan nem próbáltak meg szánt szándékkal olyan kódokat keresni, amelyek irreális mértékben az x86 processzoroknak kedveznek, hiszen ez a kutatás egyben az Intel számára is forrásként szolgál abban a tekintetben, milyen irányban kell fejlesztenie processzorarchitektúráját, hogy az versenyképesebb legyen a GPGPU pályáján - a lehetséges irányok több és szélesebb SIMD egység, illetve egyes műveletek hardveres támogatása, mint amilyen a gather/scatter.
Az év végén érkező Intel Sandy Bridge ennek megfelelően már 256 bites vektoregységekkel és új, AVX SIMD-utasításkészlettel érkezik, miközben folynak a kifejezetten az NVIDIA-t célba vevő HPC Larrabee-derivatívák fejlesztései is, sokkal több maggal, több és szélesebb SIMD egységgel, amelynek első gyümölcse 2012-re érhet be. Eközben természetesen az NVIDIA sem áll meg, az idén megjelent Fermi mikroarchitektúrája sokkal magasabbra tette a lécet, amit utódai kétségtelenül tovább fokoznak majd a következő iterációi - érdekes lenne látni, hogyan változott a helyzet a 2008-as állapothoz képest. Az NVIDIA félhivatalosan mindössze annyit válaszolt a publikációra, hogy ezek az Intel állításai, amivel óvatosan kell bánni.