Windows Server 2008 Failover Cluster
Már jó pár éve szemezek Ovidius "Átváltozások" című könyvével, szívesen elolvasnám, de valahogy mindig tolódik a terv. Most éppen a Windows Server 2008 Failover Cluster funkciójának megismerése köti le az időmet. Bár, amilyen átváltozáson átesett ez a szoftverkód, akár még fent említett műben is szerepelhetne...
Mert minek is nevezhetnénk azt a változást, amely révén a telepítési, a hálózati, a lemezkezelési, quorum-kezelési és a GUI alrendszert is teljesen újraírták? Még a szolgáltatás -- bocsánat: tulajdonság (feature) -- neve is megváltozott. Már nem Microsoft Cluster Server (MSCS) vagy Server Cluster, hanem "Failover Cluster". Kattintgatva az MMC ikonjain, azon gondolkodtam, mi nem változott?
Egy hajdanvolt cikksorozat -- Failover Cluster 2002-es szemmel
No, igen. Az, hogy milyen volt a fürtszolgáltatás, egész jól tudjuk. A TechNet magazinnak meglehetősen kedves ez a téma: 2001 és 2002-ben mindösszesen tizenhárom cikkben taglaltuk a szoftver képességeit. (A "véletlen" úgy hozta, hogy a jelen írás és a korábbi cikksorozat szerzője azonos.) Van tehát egyfajta előkép, és bár szerettük, azért kritikával is illettük mindazt, amit láttunk. Íme, két idézet az egykori tapasztalatokról:
"a Cluster telepítésének inkább NT4-es formája és érzete van, mint Windows 2000-es. Ez a "gyanú" később igazolódni fog: A Windows 2000-ben nagyon sok mindent átírtak, és nagyon sokat fejlesztettek, beleértve a Cluster szolgáltatást is, mégis maradt jócskán tennivaló a következő kiadásig." (2001. december – II. rész)
"A fürtszolgáltatás, úgy tűnik, mindig egy lépéssel az újdonságok mögött jár. Az eredeti Windows 2000 fürt, akárcsak a korábbi NT4 verzió, lemezszignatúrákat használ, nem ismeri a dinamikus diszkeket, a lemezcsatolás módszerét, ragaszkodik a lemezek betűjeleihez, NTLM hitelesítést alkalmaz, az FRS szolgáltatással hadilábon áll, még a telepítése is olyan "NT4-szagú". A sok hiányosságból most az egyik, a hitelesítés, kicsit közelít a "normális" Windows 2000 szintjéhez." (2002. december – XIII. rész)
Ezeken túl 2002 decemberében -- a további idézeteket elhagyva -- hiányoltuk a DFS- FRS-Cluster integrációt, az IPv6 támogatást, a GPT lemezek használatát, a kizárólagos Kerberos hitelesítést, és a cluster.log dokumentálatlanságát. Összegezve: a fürtszolgáltatás bevezetésekor mindeddig egy nagy kompromisszumot kellett kötnünk. A magas rendelkezésre állásért cserébe bizonyos innovatív képességekről lemondtunk, ami főleg a biztonságot növelő képességek esetén fájt és lépten-nyomon hiányzó puzzle darabkák akadályozták, hogy teljes értékű rendszerünk legyen. Mindennek fényében különösen izgalmas, mit hoz a 2008-as esztendő Windows verziója.
Visszatérve az MMC kezdő képernyőjéhez: a sokéves tapasztalat ellenére, az első percekben elvesztem. Ez lenne a Failover Cluster? Itt már semmi sincs úgy, mint régen... Aztán némi akklimatizáció után rájöttem, a dolog nem olyan ijesztő. Bár külsőleg minden új, az alapok változatlanok. Az architektúra elve továbbra is a "semmi sem közös" (shared-nothing). Az építőkövek az erőforrások, az erőforrás-csoportok és a függőségek. A mechanizmusok lényege maradt a régi: átköltözés (failover), visszaköltözés (failback), sőt, még olyan funkciókat is viszontláthatunk, mint az IsAlive/LooksAlive.
Az alapokon túl azonban az ugrás óriási, érdemes tehát nem hagyatkozni a régi beidegződésekre, a képességek újratanulását nem kerülhetjük el.
Megváltozott környezet -- szerepek kiegészítése
A Failover Cluster megértését kezdjük a környezete megértésével. A Windows Server 2008 elhozta számunkra a szerepek (roles) és képességek (features) világát. Már nem egyedi szolgáltatásokkal (Windows service) bajlódunk, magasabb fogalmi egységgel, a szereppel kell megküzdenünk. Egy "File Server" szerep, vagy egy "Print Server" szerep telepítésekor a rendszer tudja, milyen egyedi szolgáltatásokat kell telepíteni. A Failover Cluster nem szerep, hanem képesség vagy tulajdonság (feature). Önmagában semmire sem való; egy konkrét szerepet egészít ki magas rendelkezésre állási képességgel. Vagyis, bár önmagában telepíthető, az erőforrások csak akkor hozhatók létre, ha azok szerepkörét előzőleg felraktuk. Példa: A DFS NameSpace egy fürtözhető erőforrás, ám ha nem telepítjük a File Server szerepkör szerepkör-szolgáltatásaként (role service), nem hozhatunk létre ilyen erőforrást sem -- végül is érthető. A lényeg: a Failover Cluster tökéletesen érti a környezetét és annak fogalmait, azokkal szorosan integrált.
A fürtadminisztrátorok két szempontból is profitálhatnak a fentiekből. Egyrészt nagyon jól lehet majd tudni, hogy egy fürttagon "mi van fent", a konfiguráció jobban átlátható. Másrészt ha Failover Cluster mindent ért, akkor teljes egészében kompatibilis a "Server Core" telepítési móddal is -- és valóban: ott éppúgy működik, mint a teljes telepítéskor. Az első piros pont: a server Core nyújtotta kisebb erőforrásigényről, kisebb sérülékenységről, kevesebb hotfixről nem kell lemondanunk annak érdekében, hogy magas rendelkezésre állásunk legyen. Ugyanakkor ebből egy egészen más implementációs kényszermegoldás is következik: a Failover Cluster parancssori felülete nem Powershell alapú. És ezúttal nem a Cluster csapat maradt le. Ha a Server Core támogatás követelmény, a parancssori felület szintén, a Server Core-on viszont a Powershell (legalábbis a Windows Server 2008 verzióban) nem működik, abból következik, hogy a fürtszolgáltatás parancssori felülete sem lehet Powershell alapú -- hiába a WMI-barát szerkezet.
Végül még egy példa a környezettel való összenövésre. Ha létrehoztunk egy magas rendelkezésre állású File Server szerepkört egy fürtön, majd ezután megosztunk egy mappát a Windows Explorer segítségével, a megosztás automatikusan fürtözött megosztás lesz! (Vigyázat! A megosztás már nem erőforrás!) A fürt ugyanis tudja, hogy az adott lemez, amelyen a megosztás létrejött, mely erőforráscsoporthoz tartozik, tehát magát a megosztást is oda helyezi. Vagyis nem fordulhat elő, hogy egy fürtön megosztott mappa nem fürtözött mappa. És fordítva: nem szükséges a cluster administrator mmc elindítása a fürtözött szolgáltatás létrehozásához. Na, ez integráció!
Telepítés
A fürtöket többnyire ott rontották, rontják el, ahol ez először lehetséges, a telepítésnél. Vagy azért, mert eleve nem támogatott hardver szolgál alapul, vagy, mert nem értik pontosan a fürt működését és rosszul paraméterezik azt. A Windows Server 2003-ban a korábbi kiadásokhoz képest sokkal szofisztikáltabb telepítő, pontosabban inicializáló modul került, de még itt is érvényes a szabály: csak azonos gyártótól származó, Cluster kompatibilitási listán szereplő alkatrészekből építkezhetünk.
Jelentem, ennek vége. A telepítés során egy nagyon alapos, összetett rendszer esetén akár egy óránál is tovább futó validációs teszt eldönti, hogy az általunk fabrikált gépezeten működik-e majd a fürtünk, vagy sem. Ha a teszt eredménye szerint működik, akkor szedett-vedett hardver ide, HCL oda, az egy a Microsoft által is támogatott fürt lesz.
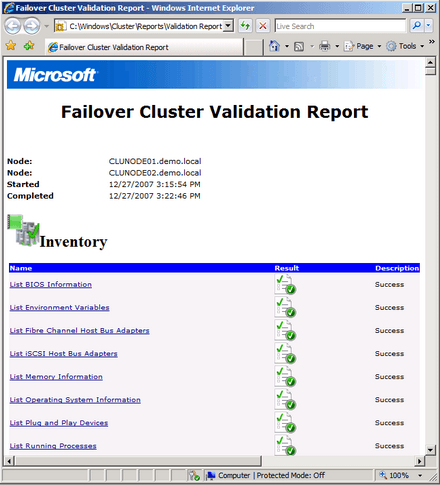
Validációs teszt -- működni fog a cluster
Sőt! Ha földrajzilag elosztott fürtöt építünk és ezért a storage teszt figyelmezető üzenettel fejeződik be, még ebben az esetben is a támogatott kategóriába esik a konfigurációnk. A Cluster HCL pedig füstté vált. Nincs többé. Nyomtassuk ki és tegyük el a validációs jelentést, mert azt később meglobogtathatjuk a megfelelő támogatási szerződés meglétekor. Mindez egyébként azért vált lehetségessé, mert mind a lemezkezelés, mind pedig a hálózatkezelés alapos revízión esett át, a fejlesztők pedig gondosan eliminálták a hibalehetőségeket, így már belezsúfolható egyetlen tesztbe minden szükséges ellenőrzés.
A telepítés folyamat 3-4 lépésből áll és egyszerre végrehajtódik az összes, általunk kijelölt node-on. A telepítés most első alkalommal teljes egészében scriptelhető -- nagymértékben javítva ezzel az implementálás tervezését, a változáskezelést és a katasztrófahelyzetek megoldását -- és hol máshol lenne erre a legnagyobb szükség, mint éppen a fürtöknél?
Első benyomások -- MMC
A fürtszolgáltatás végre valódi MMC konzolt kapott -- eddig egy MMC-t utánzó exe állomány (Apage Satana!) nyújtotta a grafikus felületet. A bal oldali fa struktúrája Exchange 2007-es iskolában nevelkedett fejlesztőkről árulkodik: nagyon egyszerű, legfeljebb két lépcsőből álló fastruktúra, mindössze öt fő ággal: szolgáltatások és alkalmazások (az erőforrás csoportok helyett), fürttagok, tároló alrendszer, hálózat végül pedig az fürttel kapcsolatos események. A középső panel teteje mindig egy áttekintő táblázatot tartalmaz, jobb oldalon pedig a környezet-érzékeny menü, amely minden pillanatban eléggé gazdag, úgyhogy a valódi menü használatára alig van szükség. Az egész felület letisztult és feladatközpontú.
A fürt valamely objektumának létrehozását minden esetben varázslóval kell elvégezni. Ez eddig is így volt, legfeljebb a varázslási folyamat áttekintése javult, az ablakok jobban magyarázzák önmagukat. Eleinte kell is, mert számos objektum új nevet kapott. Az erőforrás csoport első hálózati neve például "Client Access Point". Ezzel együtt a varázslókat nem éreztem idegesítőnek. Megvan a maguk helye és szerepe.
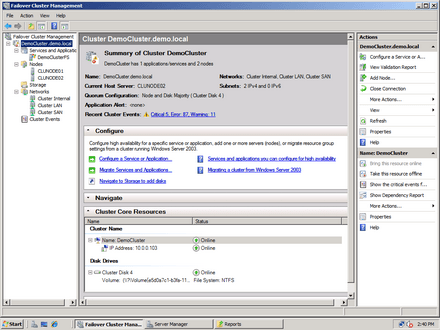
A Failover Cluster megújult MMC konzolja
A Quorum átalakulása
A fürtök eddigi nagy kincse a Quorum volt, amely szerencsés esetben saját lemezen ült, és tulajdonképpen eredetileg nem volt más, mint egy tranzakciós rendszerrel kiegészített registry hive. Hajdanán egyetlen quorum típus létezett, aztán a Windows Server 2003 megjelenésekor újabb kettő mutatkozott be (local Quorum, Majority Node Set.). Még később, az Exchange 2007 megjelentetésével együtt a Microsoft kiadott egy fürt "hotfixet" (921181), amely varázsolt egy vadonatúj Quorum típust. Ez megosztott mappát használ "tanúként" (file-share witness) és a Majority Node Set-re emlékeztet.
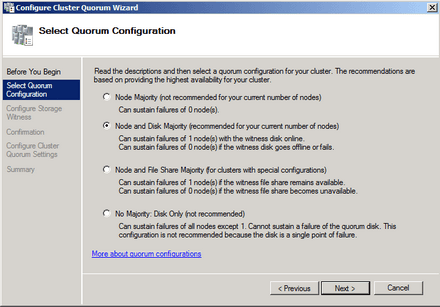
A Quroum típusának kiválasztása
Nos, a Windows Server 2008-ban a Quorum fogalma a korábbiakhoz képest felborult. Már nem registry-hive, vagy lemez, vagy megosztott mappa, vagy többség, hanem mindegyik, illetve egyik sem. A legpontosabban úgy fogalmazhatok: a quorum annak a tudása, hogy mi a Cluster, milyen a konfigurációja és milyen az aktuális állapota. Ennek a tudásnak a birtokosa vagy birtokosai a quorum. Ilyen értelemben mindig csak egy quorum van, de az lehet elosztott több node, megosztás, lemez között. Azt, hogy a fürt tagjai birtokolják-e a megfelelő tudást (értsd: a quorumot) és így a fürt működőképes-e, szavazásos módszerrel döntik el a fürt tagjai. Implementációját tekintve a Quorum négyféleképpen működhet -- azt mondhatjuk, hogy négyféle szabály szerint lehet szavazni vagy a szavazatokat kiértékelni.
Úgy érdemes elképzelni ezt, mint egy skálát, ahol a tengelyen a quorum elosztottsága, hibatűrése változik. A típusok:
- Node Majority. Ez az változat minden tekintetben megegyezik, a korábbi majority node set üzemmóddal. Szavazati joga csak a fürttagoknak van. Ha a szavazásban a többség részt vehet, akkor a fürt működik, ha nem vehet részt, akkor a fürt leáll. A fürttagok száma minimálisan 3, maximálisan 16.
- Node and disk majority. Ilyen korábban nem volt. Az előző verzióhoz képest szavazati jogot kap a tanúlemez (witness disk) – a korábbi quorum disk megfelelője. Továbbra is a többség dönt, de a tanúlemez szavazata kicsit többet ér a fürttagokénál. A fürt túléli a tagjai felének elvesztését, ha a tanúlemez működik, illetve a fürt túléli a tagjai felének -1 tagnak a kimúlását, ha a tanúlemez az örök vadászmezőkre költözött. Példa: 4 tag + tanúlemez. Ha a tanúlemez működik, kieshet két fürttag. Ha a tanúlemez nem működik, kieshet (4/2)-1 = 1 tag. Kéttagú fürt esetén ez azt jelenti, hogy a Cluster túléli a tanúlemez kiesését – feltéve, hogy mindkét node hibátlan!
- Node and File Share Majority. Pontosan úgy működik, mint az előző esetben, csak a tanúlemez helyett tanúmegosztást (file share witness) használunk. Ezt a Quorum típust vezette be a Microsoft a 921181-es hotfixszel. Földrajzilag elosztott fürtök esetén érdemes használni. Jegyezzük meg, DFS link nem lehet tanúmegosztás, annak viszont nincs akadálya, hogy egy másik fürt megosztása legyen tanúmegosztás. A tanúmegosztásnak nem kell azonos telephelyen lennie egyik fürtállomással sem.
- No Majority: Disk Only. Ez a diktatúra . A „szavazás” úgy módosul, hogy csak a tanúlemeznek van szavazata. Amíg a tanúlemez plusz egy fürttag él, addig van fürt. A módszerben nincs semmi új, ez az eredeti Quorum típus -- hátránya, hogy maga a Quorum egypontos meghibásodást jelent egy olyan rendszerben, amely az egypontos meghibásodásokat hivatott kiküszöbölni.
A modelleket -- ha megfelelő számú fürttag rendelkezésre áll -- szabadon átalakíthatjuk egyikből a másikba. Elsőre furcsa, hogy az MMC felületen a hajdani Cluster group, az első létrehozott erőforráscsoport, amely a quorumot tartalmazta, nem látható. Végeredményben mégis jobb ez így – nem fordulhat elő, hogy erőforrásokat pakolunk bele. A fent említett 16 maximális fürttag minden üzemmódban elérhető.
A hálózat átalakulása
A Quorum átalakulásával összevethető változások történtek a fürt hálózatkezelési technikáiban is. Kezdjük azzal, hogy a fürttagoknak nem kell statikus IP címmel rendelkezniük. Ízlés kérdése: van aki a statikus címekre esküszik a szervereknél -- én inkább a DHCP-szerver lefoglalt IP-címeit preferálom. Az központosított is, meg vezérelhető is. A Failover Cluster mostantól kielégíti az általam jónak vélt módszert. Ha a külső fürtcímeknél ez nem is mindenkinek vonzó, a fürtön belüli (intra-cluster) hálózattal egész biztosan senki sem akar foglalkozni. Ezután nem is kell. Úgy működik az APIPA, hogy azt nem jelzi problémának.
Kell ennél több? Íme: vadvízi evezősök tisztán IPv6 konfigurációt állíthatnak be -- mit is idéztünk a cikk elején? És még folytathatjuk: teljes a NetBIOS függetlenség; fürtök közötti forgalom teljes titkosítása; működik a tisztán Kerberos hitelesítés, NTLMv1 NTLMv2 igény szerint kihajítható. Régi vesszőparipám is teljesült: a fürtözött megosztások egyenrangú részei lehetnek egy DFS névtérnek, különösen, ami a replikációt illeti. Így végre felépíthető egy olyan DFS névtér, amelynek minden megosztása magas rendelkezésre állású, azonos tartalommal. Ezt éppen a Windows 2000 Advanced Serverbe álmodtam bele hét ével ezelőtt!
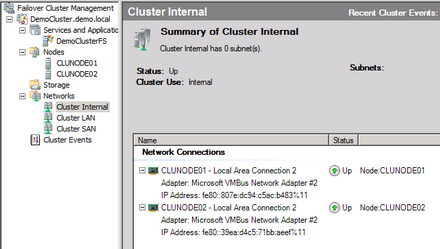
A cluster belső hálózata
A hálózatkezelés területén az i-re a pontot a földrajzilag elosztott fürtök létrehozásának lehetősége teszi fel. Elvileg ennek eddig sem volt akadálya, feltéve, ha a hálózati switcheket és az útválasztókat úgy tudtuk konfigurálni, hogy a fürtök azonos VLAN-ba kerüljenek és azonos IP alhálózatból kapjanak címet. Ezután már csak „imádkozni kellett” hogy a hálózat válaszideje ne növekedjék egy szint fölé, amit fürt már nem tolerált volna. Erre a mutatványra nem lesz többé szükség: a fürttagok gond nélkül külön alhálózatban is működhetnek – hála a (parancssorból) konfigurálható heartbeat időtúllépésnek.
[oldal:Lemezkezelés]
A lemezkezelés átalakulása
A sok újdonság között a személyes kedvenceim a lemezkezeléshez kapcsolódnak. Ezt a komponenst is alapos revíziónak vetették alá, néha egészen meglepő eredményeket produkálva. De hogy jobban értsük, nézzünk bele egy kicsit a múltba.
A fürtszolgáltatás, ahogy azt említettem már, a "semmi sem közös" elven épült fel, és ez igaz a lemezekre is. A semmi sem közös elv az amúgy közös diszkalrendszernél azt jelenti, hogy semmit sem birtokolnak közösen egyszerre a fürt állomásai. A lemezeket, mint erőforrásokat lefoglalják, és egy viszonylag bonyolult algoritmust építettek a szoftverbe, hogy a lemezek átadását, hiba esetén pedig az erőszakos átvételét kezeljék. Amikor erőszakos átvételről írok, egyáltalán nem túlzok. A Windows 2000 fürtök egyetlen lemez átvételét SCSI Bus reset paranccsal oldották meg. Mintha egy fa egy ágának lemetszését úgy végeznénk el, hogy motoros fűrésszel fentről lefelé végigsimogatnánk az egész fát.
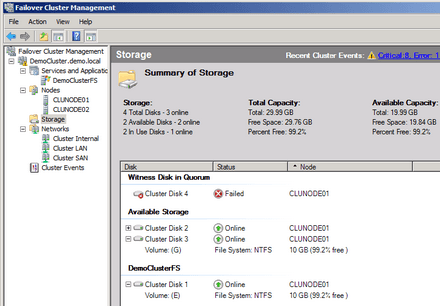
A cluster lemezeinek áttekintése
Ez jól működött 1997-ben a külső házas parallel SCSI Direct Attached Storage rendszereknél, de a mai konszolidált SAN-világban roppant barbár megoldás. A Windows Server2003 kulturáltabb módszert alkalmazott, de végső esetben még eleresztett bus resetet. A Windows Server 2008 viszont már finom úriember, a bus reset számára ismeretlen fogalom. A lemezek lefoglalására a "Persistent Reservation" módszerét használja -- tárolóalrendszer vásárlásakor ezt a képességet tessék tehát árgus szemekkel figyelni, amennyiben a fürtszolgáltatást építését is a fejünkbe vesszük.
Egy kis kitérő. Fürtöt építünk. Mit is jelent fürtöt építeni? A fürtépítés állandó harc az Achilles-sarkok, angolul Single Point of Failure, SPoF ellen. Van már kiszolgálónk, összekötjük egy új tárolórendszerrel. Összekötjük? Hányszor? Ugye, legalább duplán, a SPoF elleni védelem jegyében. Ahh, ettől a pillanattól kezdve viszont már több útvonalon is elérhetjük ugyanazokat a lemezeket, LUN-okat pontosabban. De ha már két storage kontrollerünk van, nem lenne érdemes megosztani közöttük a terhelést a hibatűrés megtartása mellett? A Windows Server 2008-ban implementáltak egy új tulajdonságot, amely "Multipath I/O" (MPIO) névre hallgat és a fenti problémakört oldja meg igen magas szinten. Az MPIO nem feltétele a fürtszolgáltatásnak, de tervezési szempontból a két komponens kéz a kézben jár: rendes cluster MPIO-t használ.
Az MPIO ismeri az összes aktuális és modern storage szabványt, felsorolásszerűen: Fibre Channel (FC), iSCSI és Serial Attached (SAS). Éles szeműek rögtön láthatják, egy valami hiányzik, a Paralel SCSI. És igen, elérkeztünk a tényleges mondanivalónkhoz. A Paralel SCSI támogatás kikerült a fürtszolgáltatásból. Fáj ez nekünk? Elsőre úgy tűnik, igen. A paralel SCSI egy kiöregedő szabvány, vagyis egyre olcsóbb, és milyen jó lenne, ha ilyen nagyon olcsó vasból építenénk legalább próbálgatásra vagy tesztelésre fürtöt. Nem fog menni. Aztán, virtuális SCSI kártyákat használhatunk virtual server vendéggépben is, és mindeddig ez volt a fürtépítés módja virtualizált környezetben. Windows Server 2008-tól már ez sem működik. Mi az, ami maradt? Tesztelésre, virtuális környezetre virtuális iSCSI Target, fizikai megvalósításnál pedig az FC-iSCSI-SAS hármasból bármelyik. (Lássuk be, azért nem volt ez olyan váratlan húzás. x64 platform alatt már a Windows Server 2003-nál sem lehetett PSCSI-t használni, ráadásul az ipar is szép lassan kidobja ezt a szabványt, ott az utód a SAS. Viszlát deszka-cluster, viszlát PSCSI! Béke poraira.)
Térjünk vissza a fürt és a lemezek kezelésének témaköréhez. Hat évvel ezelőtt panaszoltuk, hogy a dinamikus lemezekről mit sem tud a fürtünk. Nos, a témába vágóan egy jó és egy rossz hírrel szolgálhatok. A rossz hír, hogy a Windows Server 2008 sem ismeri a dinamikus lemezeket. A jó hír, hogy ez nem baj . Mire lennének jók a dinamikus lemezek?
Alapvetően két célt szolgálhatnak: egy adott partíció dinamikus növelése oldható meg velük, illetve szoftveres RAID tömböket hozhatunk létre a segítségükkel. Ez utóbbi fura igény lenne. Szoftveres RAID-et már évek óta nem láttam használni, olyan olcsó lemeztömböt hardver-eszközzel megvalósítani. Ha viszont valaki tényleg templom egere, akkor kizárt dolog, hogy fürtszolgáltatásra van szüksége. A fürtszolgáltatás ugyanis önmagában sem olcsó dolog –ergó, aki létrehoz egy fürtöt, annak már nem fájhat a hardveres RAID beruházás sem. Marad a partíció növelésének igénye.
Erre a céltáblára három golyóval is lőhetünk. Először is, ma már a virtuális lemezek világát éljük, a LUN-ok, amelyeket a fürt tagjai fizikai lemeznek látnak, valójában virtuálisak -- olyannyira, hogy a Microsoft Storage szerverben az iSCSI Target ténylegesen egy VHD formátumú állományt ajánl ki. VHD? Akkor az később növelhető is. És ha már megnöveltük a VHD-t, akkor egy diskpart-tal a partíció is kihúzható. Ehhez nem kell dinamikus diszk.
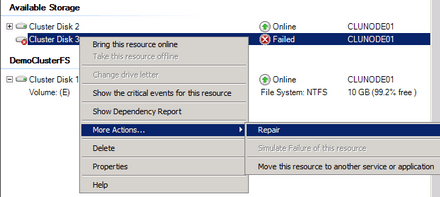
Hibás lemez javítása
Jó, maradt a basic lemez. Ez azt jelenti, hogy maradt a diszkek szignatúra alapú azonosítása is? És maradt diszkek cseréje továbbra is rémálom? Egyáltalán nem. A lemezeket a fürt továbbra is a partíciós táblába írt szignatúrák alapján azonosítja -- elsősorban. Emellett, és ez az újdonság, az SCSI szabvány Inquiry parancsát is használja a fürt. A parancsra a választ a storage kontroller adja meg és egy adott LUN-t lehet azonosítani vele. A LUN a kiszolgálóból nézve egy diszk. Mivel ez két egymástól független módszer a Windows 2008 szempontjából ugyanaz a "fizikai lemez" azonosítása, a metódusok egymás tartalékai lehetnek. Ha egy lemez nem található a szignatúra alapján, de az SCSI Inquiry működik, a fürt automatikusan javítja a szignatúrát, és fordítva.
Persze nem zárható ki az sem, hogy teljes katasztrófa történt és a teljes lemez alrendszer megsemmisült szignatúrástul Inquiry adatostul. A fürt erőforrásai ugyan leállnak, de megfelelő konfiguráció esetén (Node and disk majority) a fürtszolgáltatás még ezt is túlélheti. Ha azután újraépítjük a rendszerünket, a fizikai lemez erőforrásra kattintva, majd a "Repair disk..." parancsot választva már rá is mutathatunk, hogy a fürt lelke, vagyis a definiált erőforrás milyen testbe (értsd: tényleges LUN) költözzön. Szép, ugye?
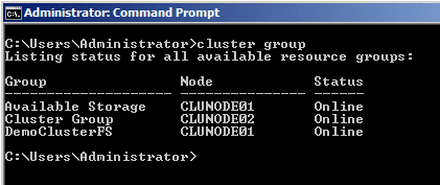
Parancssorból is látszik minden
Három további, lemezekkel kapcsolatos fejlesztést kell megemlítenünk, ebből kettőnek előzménye is van. A GPT támogatást már 2002. végén is ismertük, az akkor még .Net Server leánykori néven futó, később Windows Server 2003 x64-es fürtjeinél citáltuk, mint újonnan támogatott partíciós formátum. Jelentem a GPT nagykorú lett, a fürt minden platformja ismeri. Mi a GPT? GUID Partition Table – a Master Boot Record leváltását szolgáló módszertan. Mindenki, aki 2 TB-nál nagyobb partíciókat szeretne kezelni GPT formázás után kiált majd. És hol lenne a legnagyobb jelentősége ezen szabvány támogatásának, ha nem éppen a legfontosabb, legnagyobb rendszerek esetén?
Talán nüansznyi újítás, de jegyezzük meg, a tanúlemez nem igényel betűjelet. Mivel a nagyméretű Exchange és SQL fürtök meg olyan lemezkiosztást szeretnek, ahol a címkeként használt betűk pillanatok alatt elfogynak, adott esetben ez az egyetlen betűjel jól jöhet. Végezetül szeretném bevezetni az olvasót a lemezekre vonatkozó karbantartási üzemmód (maintenance mode) rejtelmeibe. Bár elsőre azt hittem, hogy ez a Windows Server 2008 újdonsága, rá kellett jönnöm, nem így van. A Windows Server 2003 SP1 verziójában implementálták. (Részletekkel a 903650 cikk szolgál)
Mi a karbantartási üzemmód? Azt jelenti, hogy a fürtszolgáltatás mind a négyféle (LooksAlive, IsAlive, SCSI Reserve, Private Sector) lemezellenőrzési funkcióját felfüggeszti, a fizikai lemez erőforrást "online" állapotban tartja, továbbá lehetővé teszi, hogy más processzek kizárólagosan lefoglalhassák a lemezt. Nem kell itt bonyolult dologra gondolni: chkdsk. Ha nincs maintenance mód, akkor csak a fürtszolgáltatás teljes leállításával lehetne hibajavítást végezni. Különben már az első ellenőrzés elhasalna, mire a fürt ijedten átküldeni a teljes erőforráscsoportot a másik node-re -- lekaszabolva ezzel a chkdsk-t.
A karbantartási üzemmódnak van még egy járulékos haszna: ez az összekötő kapocs a hardver alapú lemez-pillanatképet (snapshot) visszaállításához.
A folyamat egyszerű:
- A függő erőforrásokat egy ügynök leállítja
- Karbantartási üzemmódba teszi a lemezt
- Exclusive lock-ot alkalmaz
- Kicseréli a fizikai lemezt egy korábbi pillanatfelvétellel
- Feloldja a kizárólagos hozzáférést
- Befejezi a karbantartási üzemmódot
- lindítja a függő erőforrásokat
Ez több, mint amire számítani lehetett. A Windows Server 2008-nak csak grafikus felületet kellett csupán biztosítania -- megőrizve természetesen a szkriptelési lehetőséget.
Erőforrások és erőforráscsoportok
Évekkel ezelőtt tapasztaltuk már, erőforrások születnek és elhalnak. Kikerült az IIS, jött helyette a Generic Script. Eldőlt -- hiába hiányoltuk -- a WDS magas rendelkezésre állását az NLBS, nem pedig a failover cluster biztosítja. Van ugyanakkor húsz alapértelmezett erőforrás, ezek közül a Distributed File System, a File Server, a File Share Witness, az IPv6 Address, az IPv6 Tunnel Address, az Microsoft iSNS és az NFS Share részben vagy egészben új erőforrás típusok.
Sem a súgó, sem az MMC felület explicit módon nem használja azt a kifejezést, hogy Erőforrás-csoport sablon, de tulajdonképpen mégiscsak létezik ez a fogalom. Ha létre szeretnénk hozni egy új "services and application" objektumot (ez a hajdani erőforrás csoport) akkor a varázsló első lépésénél 13 féle „út” közül választhatunk, s ezek nem mások mint sablonok. Van köztük DHCP, DTC, Other Server (!) és Virtual Server is – ez utóbbi a Hyper-V integrációt mutatja.
Az erőforrások közötti viszont legjelentősebb változása a függőségeknél tapasztalható. Korábban a többszörös függőségek kizárólag ÉS kapcsolaton alapultak -- vagyis elég volt egyetlen erőforrásnak a sok közül megállnia, hogy a függőségi láncban tőle függők mind megálljanak. A Windows Server 2008-ban viszont az erőforrás függőség definiálásakor VAGY kapcsolatot is létrehozhatunk. Egy hálózati név erőforrás függhet két IP címtől is. Az egyik leállása VAGY kapcsolatnál nem okozza a hálózati név erőforrás leállását. Alhálózat cseréje során ez kifejezetten jól jöhet. Apropó: függőséget -- szemben a korábbi verziókkal -- működő erőforrásoknál is megadhatunk. Elvégre, legalább a fürtszolgáltatás maga ne okozzon leállást.
Végezetül egy különös erőforráscsoportra is felhívom az Olvasó figyelmét. A korábbi fürtökön az egyetlen azonnal létrejövő erőforráscsoport a Cluster Group volt a quorummal. A Failover Cluster ezt kiegészíti még eggyel, amelyet "Available Storage Group"-nak hívnak, és a hogy a neve mutatja, azokat a lemezerőforrásokat tartalmazza, amelyeket még egyetlen "valódi" csoporthoz sem rendeltünk hozzá. Miért fontos ez? Azért, mert így a fürt létrehozásának pillanatától minden lemezerőforrásra egyértelműen foglalt. Az új, rejtett csoport létrehozása a lehetséges rejtett hibák elkerülését jelenti.
[oldal:Eseménynapló és más változások]
Eseménynapló-kezelés
Őszinte leszek: az eseménynapló-kezelés változása okozott a legtöbb frusztrációt a számomra. Nem azért, mintha a fejlesztők nem találták volna el a helyes irányt, hanem... de lássuk előbb, mit hiányoltunk a korábbi verziókból.
"Végezetül feltehetjük a kérdést, hogy vajon elégséges információval és eszközökkel rendelkezünk-e ahhoz, hogy hatékonyan hárítsuk el a fürt hibáit. Úgy gondolom, hogy a Microsoftnak még sok tennivalója van ezen a téren. Két lehetséges úton haladhat a cég a jobb hibafelderítés elősegítésére. Az egyik egy referenciakönyv elkészítése a lehetséges naplóbejegyzésekhez […] A másik út az, ha szorosabb integrációt valósít meg a fürt és a Windows 2000 eseménynaplózó alrendszere között [..] A naplózási szinteket komponensenként lehetne meghatározni, és ha szükség van rá, akkor bekapcsolva egyre részletesebb eseménysort láthatnánk." (2002. november – Farkasokkal táncoló XII. rész)
A próféta szólt az írásból: a három fenti elképzelésből kettőt viszontláthatunk a Failover Clusternél. Az MMC fastruktúra öt főágából az utolsó az eseménykezelés. Módunk van a konzolból való kilépés nélkül megtekinteni a fürttel kapcsolatos összes eseményt. Melyik eseménynaplóból? "Melyikből szeretnéd?" -- jöhetne a válasz helyett a visszakérdezés. Itt is a Windows Server 2008 alapjai köszönnek vissza. Eseménynapló már nem csak három-négy-öt van, hanem sokkal több és sokkal részletesebb. A fejlesztők tehát ránk bízzák, hogy milyen eseményeket szeretnénk a mi ablakunkba összeválogatni. Az se baj, ha kezdetben nincs ötletünk -- fogadjuk el az ő esemény-szűrő alapbeállításaikat, nem fogjuk megbánni.
És az integráció itt még korántsem ért véget. Minden csoporthoz, erőforráshoz a lehetséges tevékenységek között kiválaszthatjuk a hozzá tartozó kritikus és figyelmeztető események lekérdezését. Ez egy nem módosítható lekérdezés, de nem is baj: szerepe, hogy az adott objektummal kapcsolatos hibaelhárítást a leghatékonyabban lehessen elkezdeni.
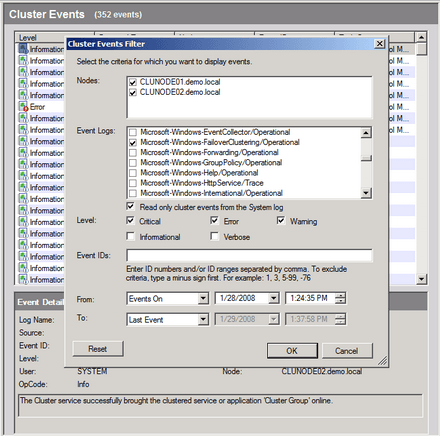
A bőbeszésű, de szűrhető eseménynapló
Ha van fontos dolog egy magas rendelkezésre állású szolgáltatás esetén, akkor az az auditálás: ki, mikor és mit végezett el azon a gépen vagy fürtön. Persze ehhez vannak üzemeltető szoftverek, mint például a System Center Operations Manager, de azok is leginkább az operációs rendszer beépített auditálási képességeire hagyatkoznak. Nos, az első lépéseket megtették a fejlesztők, a fürtre vonatkozó események (csoportmozgatás, erőforrás-létrehozás stb.) auditálhatóvá váltak. Ezen felül minden fontosabb tevékenység, amelyeket varázslók is segítenek, a windowsclusterreports mappában jelentéseket hagynak -- vagyis nem csak az ellenőrizhető, mi történt, hanem az is, hogyan.
És mi lett a cluster.log-gal? Nyugdíjba vonult és átadta helyét a Windows Server 2008 biztosította "Event tracing" szolgáltatásnak. Mindeddig ez a képesség az egyetlen kivétel, amely nem érhető el a fürtszolgáltatás konzoljából. A "Reliability and Performance" konzolban láthatjuk a Data Collection Sets Event Trace Sessions ágon belül. Láthatjuk, pontosabban megnézhetjük, hogy az élő események kezelése vajon fut-e. Az eseményeket magukat nem -- ahhoz egy tracerpt nevű parancssori eszköz áll a rendelkezésünkre. Ha ez nem tetszik, akkor még fordulhatunk a cluster.exe megfelelő kapcsolóihoz, amely az általunk paraméterezett módon és helyre egy olyan logot generál, amilyen korábban a cluster.log volt. Hogy megnézhessük végre.
A rövid próbálgatás némi hiányérzetet hagyott bennem. A hétköznapi események "kéz alatt" vannak, ez jó. Az adott objektumhoz tartozó gyors esemény-megtekintés briliáns ötlet. Az események leírását is megfelelőnek éreztem. A diagnosztikai elemzés azonban nehézkesen indul, és éppúgy nincs tudásbázis cikkekkel, referencia leírásokkal megtámogatva, mint a korábbi verziók.
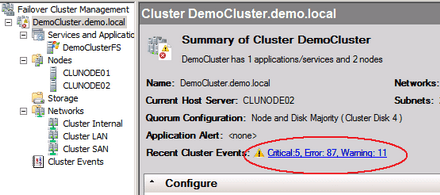
A korábbi hibák sokáig láthatóak maradnak
Ezen felül még egy dolog frusztrált. Az MMC konzol közepén elhelyezkedő belső fejléc automatikusan jelzi a kritikus és figyelmeztető üzenetek számát. Ez még rendben is lenne -- de az üzenetet nyugtázni és eltüntetni már nem tudtam, márpedig az nagyon zavaró, hogy egy problémát megoldottunk, de az eseménynaplóban fellelhető hibát x. ideig még a fejlécre is kivezetik, függetlenül az aktuális helyzettől.
Egyéb változások
Sok-sok lelkesítő újdonságról fejlesztésről esett már szó, de biztos vagyok benne, hogy az üzemeltetők majdani első számú kedvence nincs közöttük. A valószínű győztes egy aprócska dolog: nincs többé szükség cluster service fiókra! Vagyis, nincs szükség
- ezen fiók létrehozására
- jogosultságainak kezelésére (annak idején egy fél cikket rászántunk, hogy megmutassuk, a service account tud nem Domain Admin is lenni)
- a jelszóházirend meghágására – ha nem lejáróvá tesszük a fiók jelszavát
- jelszavának cserélgetésére
- hibaelhárításra, ha véletlenül töröltük a fiókot, vagy elfelejtettünk időben új jelszót adni neki, vagy csak a jogosultságait vontuk meg stb. stb.
Mennyország!
Amikor a Windows 2000 Server fürtjeit használatba vettük még a Holdban sem volt a SUS/WSUS vagy más automatikus frissítési rendszer. Egyáltalán, a frissítés, mint olyan, eléggé alacsony prioritású feladat volt. Nem úgy ma. A fürtök azonban speciális bánásmódot igényelnek. Mert teszem azt milyen állapotok keletkeznek, ha egy gépre éppen akkor költöznek át erőforrások, miközben hotfixet rak fel. Sokféle, de csak nem determinált. Épp ezért kellett bevezetni az állomások megállítását (Node pause) és és visszaállítását (Node Resume). Amíg egy állomás "Pause" állapotban van, addig a meglévő erőforrásokat futtatja, de új csoportokat nem fogad be -- egy stabil állapot keletkezik: indulhat a frissítés. A "Node Resume" ezt a helyzetet szünteti meg.
Valljuk be őszintén: a fürtök mentése és visszaállítása többnyire az ezoterikus témák közé tartozott a rendszergazdák számára. A fürtön lévő adatokat mentettük persze, de a fürt-konfigurációval nemigen lehetett mit kezdeni. A system state része, és az bizony sokszor nagy gombóc a torokban. Node ne bolygassuk a múltat...
A Windows Server 2008 Failover Clusterének mentése egy kicsit már egyértelműbb, köszönhetően a Quorum letisztultságának. Mivel a Quorum mostantól kezdve egy elosztott valami, a konfiguráció helyreállítása, legalábbis szóhasználatban, nagyon hasonlít az AD helyreállításhoz. Éppúgy, mint ott "Authorative" és "Non-Authorative" helyreállítást hajthatunk végre. Az elsőnél becsatlakoztatunk egy node-ot a meglévők közé, az utóbbi esetben visszaállítunk egy fürtöt egy korábbi konfigurációs állapot szerint. Részletek az RTM megjelenésével.
Feketeleves
Minden nagyon jó, minden nagyon szép. Tényleg? Ennyire? Bölcs ember tudja: szépség és szörnyeteg együtt járnak. A Window Server 2008-ban implementált Failover Cluster akkorát ugrott elődeihez képest, hogy a gyökereit is elszakította: történetében először nincs rolling upgrade frissítési lehetőség. Mi a rolling upgrade? Elvileg lehetséges volt, hogy egy Windows NT 4.0-val beüzemelt fürtöt átállítsunk Windows 2000-re úgy, hogy előbb az első node-ot frissítettük meg, majd az erőforrások átmozgatása után a másikat. Majd aztán ez tovább folytathattuk a Windows Server 2003-mal. Egyszerre csak egy verziókülönbség volt megengedett, a frissítésnek szigorú szabályai voltak, de mégiscsak működött. Eddig.
A Windows Server 2008-cal új korszak kezdődik. Az eltérő storage-kezelési mechanizmus és a hálózat változása bezárta a kapukat. Mit lehet tenni? Azért van egérút, a fürtök migrációját varázslók segíhetik. Egy darabig. Azután kellünk mi, mérnökök.
Összefoglalás
Mielőtt pár szép szóval elbúcsúznánk, még egyszer szeretnék idecitálni egy régi-régi cikkből. Tanulságos.
"Kényelem kontra biztonság kontra kompatibilitás: A biztonsági tényezők alkalmazásakor sokszor felhívják a szakemberek a figyelmet, hogy a biztonság növelése gyakran a kényelem és a használhatóság rovására történhet. Biztonságosabb a jelszóval történő azonosítás, mintha ilyen nem történik, de meg kell jegyezni a titkos jelsort (kényelem csökkenése), és ha tévesen adjuk meg a minket azonosító adatokat, a rendszer kizárhat minket (a használhatóság korlátozódik).
Az üzemeltetési tapasztalatok azonban azt mutatják, hogy egy harmadik dimenzió is befolyásolja a biztonsági funkciók bevezetését, ez pedig a kompatibilitás. A rendszer egyes elemeit más-más csoportok fejlesztik, akik eltérő sebességgel képesek a központi biztonsági igényekhez alkalmazkodni. A fürtszolgáltatás például nem képes a Kerberos hitelesítésre, így akik ezt a szolgáltatást igénybe veszik, nem tudnak tisztán Kerberos rendszert bevezetni."
Úgy érzem, hosszú oldalakon keresztül soroltuk azokat a példákat, amelyek alapján világossá vált: a Failover Cluster -- legalábbis a 2008-as verzió nem tartozik a fenti kompromisszumok közé. A fürt, és az azon futó alkalmazások mindazt tudják, amely az operációs rendszer része -- kompromisszumok nélkül. Nem kerékkötője és gátló tényezője a fejlesztéseknek a biztonságnak az üzemeltetésnek, hanem segítője. A virtualizáció megjelenésével a fürt -- amely maga is egyfajta virtualizációs technológia -- oda került, ahová való: nem alkalmazásokat biztosít (értsd: nem izolál), hanem azok magas rendelkezésre állását teszi lehetővé.
És a jövő? Szemetek a virtualizációra vessétek! A Failover Cluster már most is integrált a Hyper-V-vel, scriptek helyett csupán erőforrásokat kell felvennünk. A jövőben azonban ennél többre lesz szükség: live migráció, erőforrás-kihasználtság alapú csoport (értsd: virtuális gép) mozgatás és vagy még egy tucatnyi egyéb ötletem van, mire lenne szükség a jövőben. Úgy érzem, a Failover Cluster csapat felpörgött a jövendőbeli kihívásokra.
Lepenye Tamás
Rendszermérnök
Microsoft Magyarország
Véleménye van?