Megszorongatja-e az AMD Barcelona az Intel Xeonjait?
Két hete, hogy piacra dobta a Barcelonát az AMD , mely az első x86-os chip, mely egyetlen darab szilíciumon integrál négy processzormagot. Jól tükrözi a feladat komplexitását, hogy a vállalat az eredetileg reméltnél fél évvel később, ráadásul alacsony órajeleken volt kénytelen útjára bocsátani új fejlesztését. Ezen nehézségek miatt a Barcelona kezdetben biztosan nem képes felvenni a versenyt az alkalmazási területek túlnyomó többségében, ezt tükrözi árazása is, ugyanakkor jelentősen javíthatja a vállalat versenyképességét a szerverpiacon, valamint bebetonozni látszik az AMD vezető szerepét a műszaki/tudományos számítások területére. Teljesítményelemzésünk az eddig publikált SPEC CPU2006 eredmények alapján készült, mely iparági szabványnak számító tesztcsomag.
Négy processzor egy lapkán
A Barcelona a négy processzormagon kívül is számos újítást vonultat fel, melyek a teljesítmény növelését szolgálják. Az egyes magok közötti adatmegosztást a chipre integrált, 2 megabájtos harmadszintű gyorsítótár (L3 cache) szolgálja, így a magok közötti koherencia adatforgalomnak sem kell a külső HyperTransport linkeket terhelnie -- ennek az energiahatékonyságban is kiemelt szerep jut. Az egyes magok is jelentős, ugyanakkor nem radikális fejlesztéseken estek át. A nagyobb teljesítmény egyik alapköve, hogy a végrehajtóegységeket megfelelően kell etetni adatokkal. Ennek érdekében nem csak a cache-hierarchia bővült, hanem az L1 és L2 cache-ek áteresztőképessége is duplájára növekedett az adatutak szélességének megkétszerezésével.
A cache sávszélességének megduplázása előfeltétele volt annak, hogy értelme legyen a vektorizált lebegőpontos végrehajtóegységeket 128 bitesre szélesíteni, aminek eredményeként a chip elméletileg négy 64 bites pontosságú alapművelet elvégzésére képes órajelenként, szemben a korábbi kettővel -- igaz, ezt megközelíteni is csak rendkívül jól struktúrált, cache-elt adatokkla dolgozó kóddal lehetséges. A további újítások közé tartozik a szélesítés szellemében a 32 bájtos utasításbetöltés (fetch), a javított elágazásbecslés, valamint az egymástól független töltések sorrendjének dinamikus átrendezése.
A számos fejlesztés kedvezően hat a teljesítményre, ugyanakkor a korábban említett, jól strukturált lebegőpontos kódokon kívül drámai változás a K8-hoz képest nem várható az új 10h család mikroarchitektúrájától -- ezt alátámasztják a SPEC CPU2006 mérések is. Ez nem jelent mást, minthogy a Barcelonával az Intel Core után több mint egy évvel debütáló 10h többnyire inkább elmarad a konkurens mikroarchitektúrától, semmint lelépi azt. Az egyéves hátrány nagy része az Intel gyártástechnológiai lépéselőnyével, továbbá az AMD azon döntésével magyarázható, hogy a mikroarchitekturális fejlesztéseket a Barcelonához kötötték, a 10h változtatásainak mértéke pedig az AMD kutatás-fejlesztési erőforrásaira vezethetőek vissza.

Miközben a 10h generáció néhány kivételtől eltekintve nem tud a Core-hoz hasonló drámai előrelépést felmutatni elődjéhez képest, addig a monolitikus négymagos felépítés még a meglévő infrastruktúrába illesztve is drasztikus teljesítményugrást képvisel. A Barcelona rávilágít, hogy az AMD mekkorát gurított a 2003-ban bevezetett, az integrált memóriavezérlőre és az egyes chipeket összekötő koherens linkekre épülő Direct Connect rendszerarchitektúrával (DCA). A DCA ugyanis a Barcelonát is megfelelően ki tudja szolgálni, és az Intel erőltejesen felfejlesztett, dedikált adabuszokat alkalmazó infrastruktúrájánál jobban skálázódnak az AMD új négymagos chipjével szerelt rendszerek.
Bár már két hete, hogy a Barcelonát hivatalosan is bemutatta az AMD, a chippel szerelt rendszerekkel kapcsolatos mérési eredmények erősen hiányosak ahhoz, hogy teljesebb képet kapjunk. Ez valószínűleg nem véletlen, az AMD és partnerei kivárásra játszanak, hogy Drezdából kikerüljenek a magasabb órajelú, az év végére akár 2,3-2,5 gigahertzen is működőképes Barcelona-példányok is, melyek már sokkal jobb színben tűnnek fel a négymagos, két chipet egybetokozó Intel Xeonokkal szemben.
| Frissítés |
| Publikálását követően néhány kiegészítést tennénk a cikkhez.
Az összevetéskor felhasznált értékek minden esetben úgynevezett base számok, annak ellenére, hogy ezt nem jelöltük a szövegben, ami arra utalhatott, hogy a peak méréseket vettük alapul. A base és a peak közötti különbség a SPEC által megengedett optimalizáció mértékében van, valamint minden SPEC mérésnek közölnie kell base értéket, a peak viszont opcionális. Ezen praktikus ok mellett a base értékek inkább tükrözik a valós felhasználást, semmint az agyontuningolt mérések. A fórumon érkezett kritikának helyt adva a korábbi Barcelona által implementált mikroarchtektúra jelölését 10h-ra módosítottuk, mivel az AMD nem használja már sem a K-sorozatú megjelölést, a K10h pedig nem állja meg a helyét. A hexadecimális 10h család 16-ot jelöl, míg a K8 jelölése 0Fh, vagyis 15. |
A Standard Performance Evaluation Corporation által kidolgozott SPEC CPU2006 tesztcsomag számításintenzív, a valóságban is alkalmazott kódrészleteket tartalmaz, melyek számos területet igyekeznek reprezentálni. A következő összehasonlításokat végeztük el: versenyképesség az azonos árkategóriájú Xeon termékhez képest, a versenyképesség változása hasonló kétmagos Opteronhoz képest, valamint az Intel csúcsváltozatának teljesítményéhez viszonyítás.
Igyekeztünk a zavaró tényezőket kiszorítani, így a mérések lehetőség szerint SUSE Linux Enterprise 10 alatt készültek. Sajnos elegendő eredmény nem állt rendelkezésre ahhoz, hogy ugyanazon szállító gépeit vessük össze végig, így ez is egy újabb bizonytalansági tényező az időzítések, vagy az alkalmazott szoftveroptimalizációk miatt. Mindezekkel együtt úgy gondoljuk, mérvadó képet kaphatunk a Barcelona és a 10h mikroarchitektúra képességeiről.
Az egy utasításszálon futó, egész számokkal végzett műveleteket csokorba gyűjtő SPECINT2006 tizenkettő tesztet tartalmaz, melyek között kódfordítás, tömörítés, mesterséges intelligencia, kombinatorikai optimalizáció és H.264 videtömörítés is található. Az egyes altesztek eredményeit minden esetben az 1,9 gigahertzes Barcelona (Opteron 2347) egy 2 gigahertzes Clovertownhoz (Xeon E5335) viszonyított relatív teljesítménye (a Xeon a 100 százalék) alapján rendeztük sorba. A grafikonokon a vízszintes szaggatott vonal a 2 gigahertzes Clovertown, a tengerkék a 3 gighartzes változat, a sötétebb zöld az 1,9 gigahertzes Barcelona, míg a világoszöld a kétmagos K8 Opteronok, melyek a többutas tesztekben 2,6, míg az egyszálasokban 2 gigahertzen ketyegtek.
SPECint2006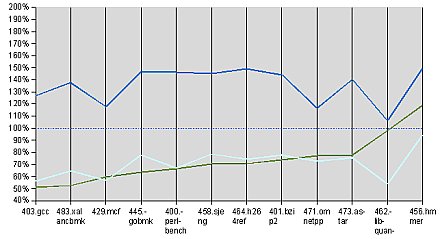
Látható, hogy az 1,9 gigahertzen futó Barcelona (IBM System x 3455) jelentősen, bőven az 5 százalékos órajelkülönbség felett marad el a 2 gigahertzes Clovertowntól (IBM BladeCenter HS21 XM), ahogyan a 2 gighartzes K8 is (IBM System x 3655). A 10h és a K8 nagyjából hasonlóan teljesít itt, összességében, számos alkalmazás alatt azonban a K8 jobban szerepel órajelre normalizáltan is. Ezt az L3 cache megjelenése és az átdolgozott memóriavezérők is magyarázhatják.
A lebegőpontos SPECfp2006 számítások 17 altesztet tartalmaznak, melyek között több áramlástani, molekuláris és kvantumfizikai dinamikát szimuláló kód, simplex algoritmus, beszédfelismerés, és sugárkövetéses (ray-tracing) renderelés is található. A 10h itt lényegesen jobban teljesít a Core-hoz (Fujitsu Siemens Computer PRIMERGY RX300) képest, mint az egészpontos műveletekben, ugyanakkor összességében alig jobban, mint az előd, a K8, sőt egyes kódok alatt még ki is kap. Ezek alapján megkockáztatható, hogy végeredményben a 10h egy-két szélsőséges esetet kivéve nem jelent átütő előrelépést az egyszálú végrehajtási teljesítmény terén. Ebből az összevetésből nélkülöztük a 3 gigahertzes Clovertownt, mivel nincs hozzá megfelelő eredmény a SPEC.org adatbázisában.
SPECfp2006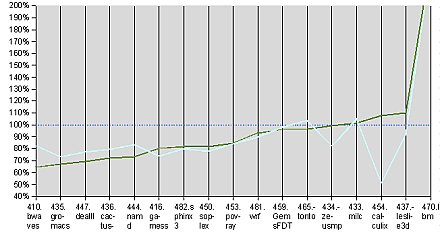
Kétutas rendszerek
Nyilvánvaló azonban, hogy nem is ez volt az AMD fejlesztéseinek fókusza, a mikroarchitektúra mindössze egy erősebb ráncfelvarrásben részesült. A mérnöki erőket a vállalat sokkal inkább az elektronikai implementációra fordította, vagyis hogy egyetlen szilícium lapkára négy magot integráljon egy memóriavezérlő és L3 cache társaságában, őgy, hogy megfelelő teljesítmény mellett a korábban meghatározott energiakereteken belül maradjanak. Az erőfeszítések meghozták gyümölcsüket: ugyanabban a kétutas IBM System x 3455 konfigurációban a két, 1,9 gigahertzes Barcelona jellemzően 30-60 százalékkal nagyobb számítási teljesítmény ad le SPECint_rate2006, alatt (minden magon egy példányban fut a csomag), mint két 2,6 gigahertzes kétmagos K8, melyek ráadásul drágábbak is valamivel.
SPECint_rate2006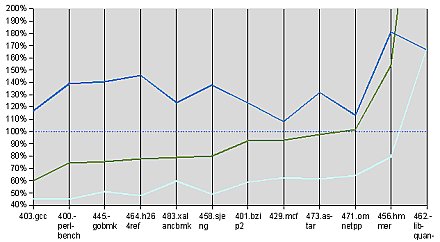
Ebből egyenesen következik, hogy a négymagos Xeonokkal szemben drasztikusan javult az Opteron versenyképessége, ugyanakkor a kódok többségében továbbra is Clovertown vezet. Feltételezve, hogy a DCA, a két független memóriavezérlő és memóriabank miatt az Opteron jobban skálázódik az órajellel, mint a Clovertown, úgy 2,5 gigahertz környékén már ki is egyenlítődhet a mérközés a legerősebb, 3 gigahertzes Clovertownnal is -- a kérdés, mikor, ugyanis az Intel ezekben a hetekben indítja be a 45 nanométeres változatok kereskedelmi tömegtermelését, melyek nagyobb L2 cache-t tartalmaznak, és a csúcsváltozatok magasabb órajeleken futhatnak majd.
A Barcelona és a DCA kombó igazán csak a SPECfp_rate2006 alatt mutatja meg a foga fehérjét -- pontosabban az Intel Bensley platformja vérzik el csúnyán. Hiába ugyanis a két dedikált adatbusz egyenként 10,4 gigabájtos áteresztőképességgel, és a négycsatornás FB-DIMM memóriavezérlő, a tesztek többségáben a Xeon-konfiguráció a memória felől válik korlátossá. A Opteron skálázódásából valószínűsíthető, hogy nem a sávszélesség fogy el (elvileg koherenciaforgalom sincs az egyes magok között), hanem a memóriavezérlő vagy a memóriabank telítődik az egyidejű műveletekkel. Ennek megfelelően a Barcelona ott veri leginkább a Clovertownt, ahol utóbbi az órajellel már szinte semmit nem skálázódik, vagyis végrehajtóegységei többnyire üresen pörögnek.
Ennek eredményeként nagyot fordul a kép az egyszálas eredményekhez képest. Az 1,9 gigahertzes Barcelonákkal szerelt IBM System x 3455 szerverben a lebegőpontos kódok többsége alatt nagymértékben felülmúlja a 2 gigahertzes Clovertownokat a PRIMERGY RX300-ban -- ráadásul sokkal nagyobb különbségekkel, mint amekkora hátrányt szerez azokban, ahol kikap. Köszönhetően a monolitikus felépítésnek és a DCA-nak, a 2,6 gigahertzes kétmagos Opteronhoz képest itt is jellemzően 30-60 százalékkal nagyobb teljesítmény leadására képes egy kétutas rendszerben.
SPECfp_rate2006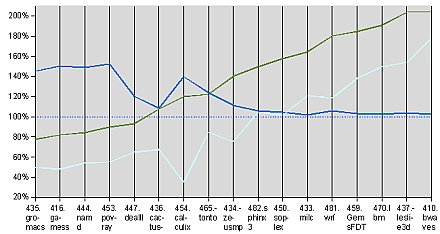
Konklúzió, kitekintés
Mint minden teszt, a SPEC CPU2006 is erősen korlátozott relevanciával bír olyan területekre, melyek messze esnek a számításintenzív, optimalizált kódokétól -- ez leginkább az üzleti célú alkalmazásokat futtató szerverekre igaz, mely a Barcelona legfőbb célterülétének tekinthető, de a PC-szoftverek is más képet mutatnak jellemzően. Addig azonban, míg nem állnak rendelkezésre mérési eredmények szélesebb körből, addig a SPEC CPU2006 eredményeiből kell főznünk.
A SPEC CPU2006, korlátai ellenére, véleményünk szerint jó indikátora az Opteronok versenyképességének változására. Mint láthattuk, a Barcelona jellemzően 30-60 százalékkal múlja felül a 2,6 gigahertzes kétmagos K8-at ugyanabban a szerverben. Úgy véljük, az extra párhuzamosságot és a cache-t díjazó tranzakciós alkalmazások (például webszerver, OLTP) alatt ez inkább a 60 százalékhoz lesz közelebb. Az Intel felhozatalához képest a Barcelona egyértelműen a négyutas szerverekben lesz a leginkább versenyképes, felülmúlva az Intel nemrég piacra dobott Caneland Xeon MP paltformját is, míg a kétutas gépek esetében nagyjából partiba kerül a négymagos Xeonokkal.
Sokkal kevésbé fényes, mondhatni borús a helyzet az AMD számára az asztali gépek körében. Sem rendszerarchitekturális előnyét nem tudja kiaknázni itt, sem pedig monolitikus felépítését a legtöbb felhasználási területen. Az erőltejes Core mikroarchitektúra az Intel 65 nanométeres gyártási eljárásán ráadásul jelentős órajelfölényt is élvez, amit a PC-szoftverek sokkal jobban kedvelnek a többszálú párhuzamosságnál -- ennél a pontnál kijelenthető, hogy ezen a területen a monolitikus négymagos felépítés kifejezetten hátrány az alacsonyabb órajel és drágább gyártás miatt. Mire az AMD piacra dobja a 10h-ra épülő asztali Phenomokat, addigra az Intel megkezdi 45 nanométeres termékeinek felfuttatását is, melyek gyorsabb rendszerbusszal, nagyobb L2 cache-sel, és egy-két fokozattal feljebb tolt órajelekkel operálnak.
Sajnálatos módon a Barcelona féléves késésén túl a négymagos chiphez dukáló új, a koherens HyperTransport 3.0 linkekkel és topológiával operáló rendszerarchitektúra sem érkezett még meg, mely jobb skálázódással kecsegtet, és valóban hatékony nyolcutas gépek tervezését is lehetővé teszi. A DCA 2 jövő év második felére várható, a Shanghai kódnéven ismert, 45 nanométeres Barcelona-derivatívával. A Shanghai valószínűleg nagyobb, akár 6-8 megabájt L3 cache-t is alkalmazhat.
Közben azonban az Intel sem tétlenkedik, és jövő év végén, de várhatóan legkésőbb 2009 elején leváltja jelenlegi adatbuszokat, és a DCA-hoz hasonló QuickPath (korábban CSI) architektúrát vezet be a továbbfejlesztett Core-ra épülő Nehalem-generációval. A Nehalemmel az Intel várhatóan bezárja a skálázódási ollót, sőt a várakozások alapján még fölényre is szert tesz. Az AMD-nek így összességében alig 1 év áll rendelkezésre, hogy kihasználja a 2003-ban debütált DCA adta előnyét, és javítsa profitabilitását, mielőtt az Intel az összes piaci szegmensben fölényt épít ki 2009 elejére -- a jelenlegi információk alapján.
Véleménye van?