Soha nem látott nyelvpárokat is képes fordítani a Google
Újabb említésre méltó eredményeket villantott fel az AI és a deep learning kutatás a Google montreali laborjában, ezúttal a többnyelvű neurális gépi fordítással kapcsolatban. A Google Fordító fejlődésére nem csak az AI-szakértőknek lesz érdemes figyelniük, hanem a nyelvészeknek és a fordítóknak is.
Olyan nyelvpárokat is lefordíthat a Google mesterséges intelligenciája a közeljövőben, amelyekre eddig még nem volt képes, és nem is tanították rá a fejlesztői. A többnyelvű Google neurális gépi fordítás (GNMT) lényege, hogy a rendszer minden nyelvet lefordít egy köztes nyelvre, például ha megtanult már portugálról angolra fordítani és angolról spanyolra, akkor innentől kezdve portugálról spanyolra is fordíthat annak ellenére, hogy ezt a nyelvpárt még nem tanulta - a kettő közti kapcsolatot hívják "zero-shot" fordításnak.
Szeptemberben írt arról a Google, hogy elkezdte alkalmazni a neurális gépi fordítást, vagyis egy olyan keretrendszert, amelyet több millió példa alapján tanított fordításra. Folyamat közben a szöveget nem szavakra és kifejezésekre bontja fel, hanem a mondat egészét veszi figyelembe, és így értelmezhetőbb eredményt ad a korábbi változatnál. A bevezetés következtében jelentős mértékben javult a mandarin és az angol nyelv közötti fordítás minősége is, amit például az Engadget mindkét nyelven anyanyelvi szinten beszélő szerzője is alátámasztotta.
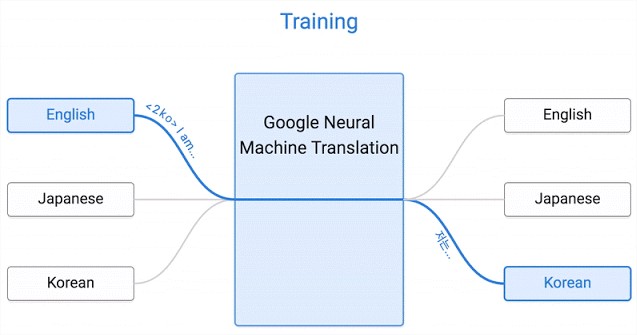
Az AI-labor szakértőinek tapasztalata szerint nem csak egy-egy nyelvpár lefordítását oldhatja meg az GNMT, hanem egyszerre akár többet is . A Google Brain csoport részeként létrehozott szakértői gárda nem olyan régen alakult Montrealban, ehhez képest pedig már viszonylag sok eredményt mutatott fel, a többnyelvű fordítás lehetőségeit egy kutatási jelentésben fejtették ki az AI-szakértők.
Összesen 103 nyelvvel működik a Google Fordító, ennek következtében 5 253 nyelvpárt képest lefordítani, melyekhez egyenként több millió példán keresztül vezet a CPU- és időigényes folyamat. A kutatók pár nyelv megtanítása után figyelmesek lettek arra, hogy a fordítás abban az esetben is működik a már ismert nyelvek között, ha a köztük lévő kapcsolatot még nem tanították meg a rendszernek.
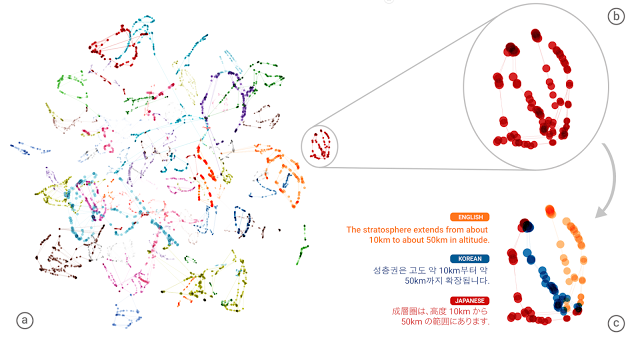
A csapat kiemelt egy részletet a deep learning működéséből, ez alapján a rendszer automatikusan csoportokat képzett az angol, a koreai és a japán nyelv azonos jelentésű mondataiból, vagyis a GNMT kifejlesztett egy saját belső nyelvet, amely összeállítja a hasonló kifejezésekből és mondatokból álló nyelvi képződményeket. A kutatók szerint ez mutatja, hogy a hálózat nem csak memorizálta azt, hogy hogyan fordítson le egy kifejezést egy másik nyelvre, hanem sikerült megértenie valamit a mondat szemantikájából is - ezt nevezték el interlinguanak.
Jogod van tudni: mankó kirúgáshoz, munkahelyi szkanderezéshez Ezúttal egy mindenki számára kötelező, de laza jogi különkiadással jelentkezünk. Ennyi a minimum, amit munkavállalóként illik tudnod.
A kutatók legnagyobb kísérletükben eddig 12 nyelvpárt egyesítettek egyetlen modellben, amely önmagában volt akkora méretű, mint az egyes nyelvpárok modelljei önmagukban. Az egy nyelvre jutó, drasztikusan lecsökkent kapacitás ellenére a kutatók úgy tapasztalták, hogy a fordítás minősége "csak némileg vált alacsonyabbá" mint a kétnyelvű modelleknél. Nem a fordítás minőségének tökéletesítése most a cél, hanem inkább a kiterjesztés a Google Fordító összes nyelvére, mivel abban biztos a kutatócsoport, hogy az eredmények gyorsan skálázhatóak az eddigi kísérleteknél sokkal több nyelvre.
Az eredmények gyakorlati alkalmazásával sem tétlenkedik a Google, a kutatási beszámolóval egy időben a Google Research Blog arról is hírt adott, hogy a 16 leggyakrabban használt nyelvpár közül 10 már ezt a többnyelvű neurális gépi fordítási rendszert alkalmazza működés közben - azt nem részletezi, hogy pontosan melyek ezek. A magyarról egyik írás sem tesz említést, bár köztudottan nem tartozik sem a legkönnyebb, sem a legismertebb nyelvek közé, ezért egyelőre az is megfelelő lenne, ha a Google Fordító valamivel elfogadhatóbban oldaná meg a magyar és angol közötti fordítást.