Lassan itt a JIT-éra vége?
Úgy tűnik, lassan véget ér a just-in-time fordítás kora. A technológia fejlődésével, a hardverek gyorsulásával és az elvárások átalakulásával nem tudta tartani a lépést ez a megközelítés - jöhet a hibrid, AOT+interpretált világ?
A Windows 10 egyik kevéssé publikált újdonsága a .NET kód előfordítás (ahead of time compilation, AOT), amit a Microsoft .NET Native néven emleget. Ez lehetővé teszi, hogy a fejlesztő eldöntse, C# kódja a hagyományos JIT motoron fusson, vagy telepítéskor készüljön belőle egy natív futtatható kód. A cég szerint az utóbbi előnye, hogy lényegesen lerövídíti az app indulásához szükséges időt és jobb felhasználói élményt nyújt.
JIT vs AOT vs interpretált
A Microsoft azonban nem jár egyedül ezen az úton. A Google szintén fokozatosan AOT alapokra helyezte át az Android futtatókörnyezetét, a szinte az indulás óta használt Dalvik VM még JIT fordítást használt, a Lollipoptól fogva azonban az alapértelmezett futtatókörnyezet az ART (Android RunTime), amely a JIT megközelítés helyett már telepítéskor fordít hardverspecifikus gépi kódot, és a következő futtatásoknál ezt használja az alkalmazás.
A Java esetében is hagyományosnak számít a just-in-time fordítás, bár kivételek korábban is voltak. Augusztusban az Oracle bejelentette, hogy AOT fordítóra állítja át a HotSpot futtatókörnyezetet (JVM). Ugyan AOT Java VM-ek már korábban is léteztek, az Oracle döntése azt jelenti, hogy hamarosan a Java fősodra is AOT-s lesz, a JIT pedig várhatóan kuriózummá válik.
JIT - tündöklés és bukás?
A JIT nagy ígérete az volt, hogy kombinálni tudja az interpretált és az előre fordított kód előnyeit. Az ígért JIT-forradalom alól azonban kicsúszott az alap, a dinamikus típusok használata. A dinamikus típusokat használó nyelveknél ugyanis szinte lehetetlen előre meghatározni az objektumok típusait futásidő előtt, így rendkívül nehéz előre optimális gépi kódot előállítani. Futásidőben azonban ismert a változók által felvett érték, meghatározható a típus és optimizálható a kód, a sűrűn futó kódrészlet pedig tovább gyorsítható. A dinamikus típusokra alapozó klasszikus nyelvek, mint a Self és a Smalltalk azonban mára gyakorlatilag kihaltak, az új generáció (Ruby, PHP, Perl) pedig elsősorban szerveroldalon nyert teret, ahol a JIT hátrányai kevésbé érezhetőek. Az egyetlen fontos kivétel a JavaScript – itt a hordozhatóság és keresztplatformos futtathatóság igénye jelenleg minden egyéb szempontot felülír.
JVMLS 2015 - Java Goes AOT
Még több videóA legfontosabb előnyök elvesztésével kidomborodnak a JIT hátrányai. Az alkalmazás indulásához szükséges idő megnyúlik, ugyanis nem csak a szoftvernek, de mellette a fordítónak is el kell indulnia. A problémát súlyosbítja, hogy kezdetben nincs idő az alapos kódoptimalizálásra, emiatt az előállított gépi kód is sokkal lassabb az elején. Emiatt áll elő az a fura helyzet, hogy a rövid ideig futó alkalmazások esetén a JIT még az interpretált kódnál is lassabb lehet. Részben emiatt vált gyakorlattá, hogy ma már több fordítóval dolgoznak a nagyobb platformok, induláskor egy egyszerűbb compiler áll fel először, amely beépített heurisztikával igyekszik elfogadható kódot gyártani, majd később indul be a komplexebb, alaposabban dolgozó fordító, amely elkezdi komolyan optimalizálni az alkalmazást.
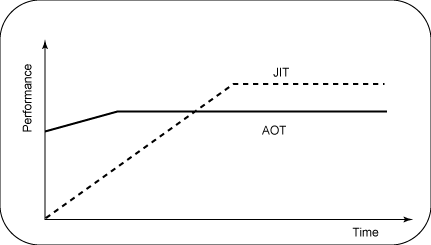
Az ígéret (forrás: IBM)
Egy érdekes, ritkán említett hátránya a dinamikusan optimalizáló JIT-nek a gyorsítótárazás kiiktatása. A JIT által előállított kód legtöbbször dirty flaget kap, amely letiltja a gyorsítótárazást, emiatt az új utasítások betöltéséhez a processzornak rendszeresen a rendszermemóriáig kell hátranyúlnia. Ez adott esetben száznál is több órajelciklust jelent, szemben az integrált másod- vagy harmadszintű gyorsítótár néhány órajeles elérésével. A lemezről betöltött statikus kód ellenben gyorsítótárazható, ami drámaian tudja növelni a végrehajtás sebességét.
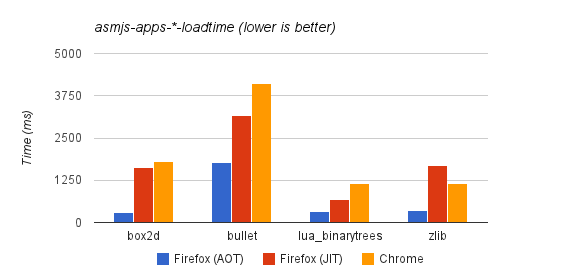
És a tények (asm.js alkalmazások betöltődési ideje)
Ezzel összefügg egy másik probléma, a virtuális memória. Ha az operációs rendszer kifut a rendelkezésre álló rendszermemóriából, akkor megvizsgálja az ott található információt. A betöltött statikus állományokat egyszerűen kidobja (hiszen azokat bármikor újra betöltheti, ha szükség van rá), a dirty flaggel rendelkező oldalakat azonban kénytelen kiírni lemezre (az adatvesztés elkerülése végett). Ez különösen okostelefonok esetében tud kegyetlen lenni, ahol korlátozott a memóriakapacitás és nincs swap fájl (mint Androidon), ilyenkor a rendszer egyszerűen lelövi az alkalmazást. Ez már a felhasználói élményt is komolyan befolyásoló szituáció.
Nagyon fontos elvárás a kiszámítható, viszonylag pontosan előrejelezhető teljesítmény - egy másik olyan terület, ahol a JIT elég látványosan elbukik. A fejlesztő ugyanis nincs érdemi ráhatással arra, hogy a fordító pontosan hogyan és mikor optimalizálja az adott kódrészletet. Ez a fajta véletlenszerűség ráadásul csak súlyosbodik azzal, hogy a modern JIT-motorok már magas minőségű gépi kódot tudnak előállítani. Az eredmény ugyanis annyi, hogy a kód vagy rendkívül gyorsan, vagy rendkívül lassan fut - azt pedig nem lehet előrejelezni, hogy adott pillanatban ezek közül éppen melyik lesz igaz. Ennek kapcsán roppant nehéz (sőt gyakorlatilag lehetetlen) a kritikus kódrészletet úgy megírni, hogy mindig egy bizonyos minimumnál gyorsabban fusson.
Két oldalról szorul a hurok
A JIT előnye egyébként az interpretált kóddal szemben is erősen olvadni látszik. Az interpretált végrehajtás ugyan jóval nagyobb CPU-terhelést jelent, de ma már sok esetben ez a terhelés egész egyszerűen belefér. Egy-egy Python script lefutása vagy a Ruby végrehajtása ugyan sokszorosára lenne gyorsítható, de néhány kivételtől eltekintve (hatalmas skálázódó rendszerek) ez már nem probléma. A magyarázat, hogy a processzorok az elmúlt évtizedben annyira gyorssá váltak (még a mobil, beágyazott processzorok is), hogy az interpretálás által képzett overhead sok esetben már nem fogja vissza érdemben (a felhasználó által érzékelhetően) a sebességet.
A fenti trendek eredményeként egy új megközelítés terjedt el az elmúlt években, amely szintén kombinálja az AOT és az interpretáció előnyeit, de hatékonyabban, mint a JIT. Ez nagyjából úgy írható le, hogy a kritikus kód kapjon maximális optimalizációt, készüljön a klasszikus "rendszernyelvek" egyikén, a nem kritikus kód viszont íródjon magas szintű nyelven. A legjobb példa a NumPy és a Python kapcsolata - a sebességet igénylő matematikai számításokhoz készült könyvtár legnagyobb része C-ben íródott és rendszerspecifikus, natív kódként fut.
Cikkünk Marcel Weither gondolatébresztő bejegyése alapján készült.