Leváltja a Google a Wikipediát
A Google is emeli a tétet a keresők világában: a szemantikus keresés felé tesz egy lépést, elindítja a korábban már belengetett “knowledge graph” nevű rendszert, ami ha úgy tetszik, egy mesterségesen létrehozott Wikipedia.
Az újítás lényege, hogy a Google fogalmi entitásokat hozott létre, mondhatni szócikkeket a webes tartalmak alapján. Különböző kategóriákban a kereső összegyűjtötte a lehető legtöbb elemet, így már képes értelmezni személyeket, korszakokat, földrajzi helyeket, tárgyakat. A Google rendszere nagyjából hasonló módon működik, mint a Facebook ismeretségi gráfja, azzal a különbséggel, hogy míg a Facebook a felhasználók közti interakciókat rendezi össze, addig a Google a keresője által feltárt tudást rakja össze kategóriákba keresési kifejezések szerint.
Személy? Ma is élő? Rákérdezhetek?
A kereső eddigi fejlesztései tartalmi szempontból jó ideje nem léptek előre, az újítások inkább arról szóltak, hogyan tálalja a Google ugyanazt, illetve hogyan spóroljon tizedmásodperceket minden egyes kereséskor. Ezúttal viszont alapjaiban változik meg a kereső viselkedése, hiszen nem csak linkeket dob vissza, hanem egy saját adatbázist tart fenn, amiből saját organikus válaszokat készít. Ez azért is egy komoly lépés, mert az eddigi primitív műveletek után a Google egy sokkal komplexebb tartalmi területen is megtartja a látogatót és nem passzolja azt tovább egy másik oldalra.
CI/CD-vel folytatódik az AWS hazai online meetup-sorozata! A sorozat december 12-i, ötödik állomásán bemutatjuk az AWS CodeCatalyst platformot, és a nyílt forráskódú Daggert is.
A funkció működése egyszerű. A felhasználó ugyanúgy elkezdi beírni a keresésőkifejezést, és amennyiben az szerepel a Google fogalmi felhőjében, akkor az organikus találatokat eleve ennek megfelelően rendezi, illetve a jobb oldalon egy külön kiemelésben jön elő az adatsor a keresett személyről, helyről, fogalomról. Egyelőre inkább a tulajdonnevek keresésekor látványos a megoldás, egy személynél a képe mellett megjelennek a biográfiai adatok, legfontosabb alkotások, események, illetve a hozzá köthető további személyek.
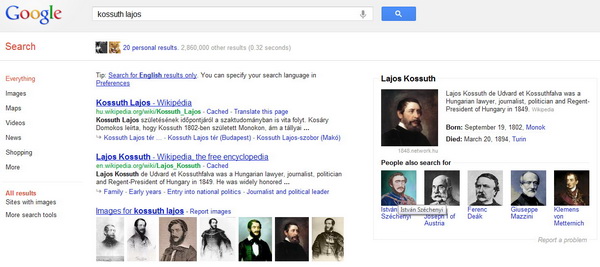
Mindent tudni fog előbb-utóbb
A knowledge graph megjelenése egyértelmű csapás a Wikipedia számára, jelentős mennyiségű forgalmat fog ellopni tőle ez a képesség - a Google adta, most elveszi. Eddig bármilyen névre, fogalomra rákerestünk, nagy eséllyel egy Wikipedia-szócikket találtunk az első három hely valamelyikén a listának. Ez valószínűleg így is marad, de a felhasználónak nem kell rákattintania a linkre, ha például csak azt szeretné megtudni, hogy a keresett személy mikor és hol született. Egy nem elhanyagolható extra, hogy ezen túl a Legyen Ön is milliomos című műsorban a telefonos segítség sokkal hatékonyabban lesz használható a Google segítségével.
A metakeresés, illetve a szemantikus keresés a Google életében egy fontos lépés, a mostani fejlesztés egy mérföldkő ugyan, de még mindig csak az út kezdete. A Bing és a Google fejlesztéseiben is egyaránt látszik viszont, hogy a következő időszak egy komoly szintlépés lesz a körülbelül 10 éve azonos logikai elvek alapján működő keresők piacán. A Google elkötelezett célja, hogy egy olyan mesterséges intelligenciát építsen fel, ami képes jobban megérteni a valódi világ entitásai közt lévő kapcsolatokat. A linkekre épülő adatbázis helyett valós viszonyok, metaadatok szerinti következtetések adhatják a találati listák gerincét. A knowledge graph kevésbé egy keresőmotor, inkább egy “válaszmotor”.
A funkció már a felhasználók jelentős részének élesedett is, legalábbis azoknak, akik az angol nyelvű felületet használják.